 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILE: SeMantic Ids Enhanced CoLd Item Representation for Click-through Rate Prediction in E-commerce SEarch
Oct 14, 2025



With the rise of modern search and recommendation platforms, insufficient collaborative information of cold-start items exacerbates the Matthew effect of existing platform items, challenging platform diversity and becoming a longstanding issue. Existing methods align items' side content with collaborative information to transfer collaborative signals from high-popularity items to cold-start items. However, these methods fail to account for the asymmetry between collaboration and content, nor the fine-grained differences among items. To address these issues, we propose SMILE, an item representation enhancement approach based on fused alignment of semantic IDs. Specifically, we use RQ-OPQ encoding to quantize item content and collaborative information, followed by a two-step alignment: RQ encoding transfers shared collaborative signals across items, while OPQ encoding learns differentiated information of items. Comprehensive offline experiments on large-scale industrial datasets demonstrate superiority of SMILE, and rigorous online A/B tests confirm statistically significant improvements: item CTR +1.66%, buyers +1.57%, and order volume +2.17%.
DiffusionGS: Generative Search with Query Conditioned Diffusion in Kuaishou
Aug 25, 2025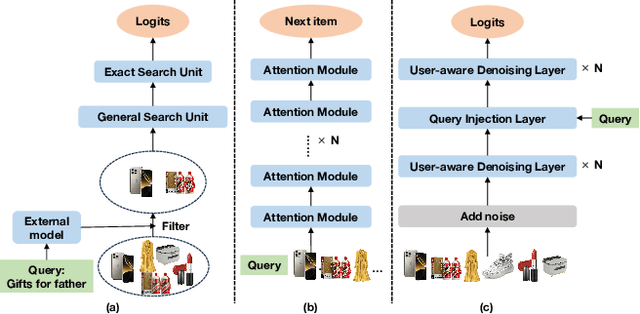
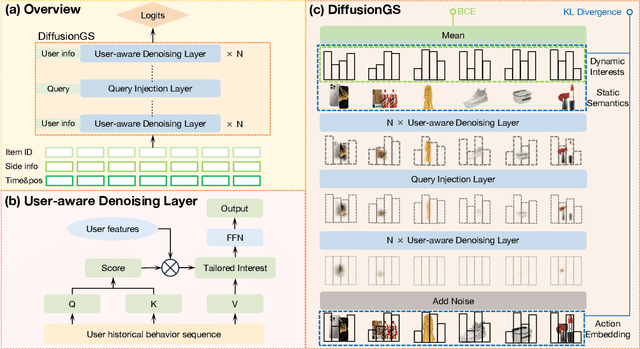
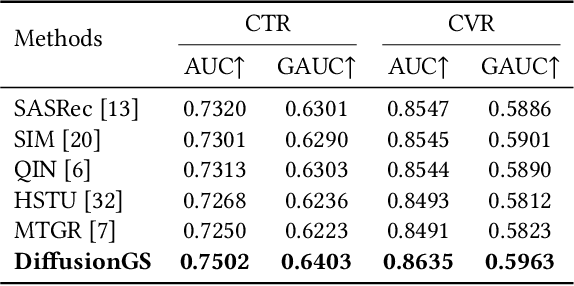
Personalized search ranking systems are critical for driving engagement and revenue in modern e-commerce and short-video platforms. While existing methods excel at estimating users' broad interests based on the filtered historical behaviors, they typically under-exploit explicit alignment between a user's real-time intent (represented by the user query) and their past actions. In this paper, we propose DiffusionGS, a novel and scalable approach powered by generative models. Our key insight is that user queries can serve as explicit intent anchors to facilitate the extraction of users' immediate interests from long-term, noisy historical behaviors. Specifically, we formulate interest extraction as a conditional denoising task, where the user's query guides a conditional diffusion process to produce a robust, user intent-aware representation from their behavioral sequence. We propose the User-aware Denoising Layer (UDL) to incorporate user-specific profiles into the optimization of attention distribution on the user's past actions. By reframing queries as intent priors and leveraging diffusion-based denoising, our method provides a powerful mechanism for capturing dynamic user interest shifts. Extensive offline and online experiments demonstrate the superiority of DiffusionGS over state-of-the-art methods.
Redefining Information Retrieval of Structured Database via Large Language Models
May 09, 2024



Retrieval augmentation is critical when Language Models (LMs) exploit non-parametric knowledge related to the query through external knowledge bases before reasoning. The retrieved information is incorporated into LMs as context alongside the query, enhancing the reliability of responses towards factual questions. Prior researches in retrieval augmentation typically follow a retriever-generator paradigm. In this context, traditional retrievers encounter challenges in precisely and seamlessly extracting query-relevant information from knowledge bases. To address this issue, this paper introduces a novel retrieval augmentation framework called ChatLR that primarily employs the powerful semantic understanding ability of Large Language Models (LLMs) as retrievers to achieve precise and concise information retrieval. Additionally, we construct an LLM-based search and question answering system tailored for the financial domain by fine-tuning LLM on two tasks including Text2API and API-ID recognition. Experimental results demonstrate the effectiveness of ChatLR in addressing user queries, achieving an overall information retrieval accuracy exceeding 98.8\%.
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
Apr 10, 2024



We present Eagle (RWKV-5) and Finch (RWKV-6), sequence models improving upon the RWKV (RWKV-4) architecture. Our architectural design advancements include multi-headed matrix-valued states and a dynamic recurrence mechanism that improve expressivity while maintaining the inference efficiency characteristics of RNNs. We introduce a new multilingual corpus with 1.12 trillion tokens and a fast tokenizer based on greedy matching for enhanced multilinguality. We trained four Eagle models, ranging from 0.46 to 7.5 billion parameters, and two Finch models with 1.6 and 3.1 billion parameters and find that they achieve competitive performance across a wide variety of benchmarks. We release all our models on HuggingFace under the Apache 2.0 license. Models at: https://huggingface.co/RWKV Training code at: https://github.com/RWKV/RWKV-LM Inference code at: https://github.com/RWKV/ChatRWKV Time-parallel training code at: https://github.com/RWKV/RWKV-infctx-trainer
Highly Accurate Disease Diagnosis and Highly Reproducible Biomarker Identification with PathFormer
Feb 11, 2024



Biomarker identification is critical for precise disease diagnosis and understanding disease pathogenesis in omics data analysis, like using fold change and regression analysis. Graph neural networks (GNNs) have been the dominant deep learning model for analyzing graph-structured data. However, we found two major limitations of existing GNNs in omics data analysis, i.e., limited-prediction (diagnosis) accuracy and limited-reproducible biomarker identification capacity across multiple datasets. The root of the challenges is the unique graph structure of biological signaling pathways, which consists of a large number of targets and intensive and complex signaling interactions among these targets. To resolve these two challenges, in this study, we presented a novel GNN model architecture, named PathFormer, which systematically integrate signaling network, priori knowledge and omics data to rank biomarkers and predict disease diagnosis. In the comparison results, PathFormer outperformed existing GNN models significantly in terms of highly accurate prediction capability ( 30% accuracy improvement in disease diagnosis compared with existing GNN models) and high reproducibility of biomarker ranking across different datasets. The improvement was confirmed using two independent Alzheimer's Disease (AD) and cancer transcriptomic datasets. The PathFormer model can be directly applied to other omics data analysis studies.
Universal Normalization Enhanced Graph Representation Learning for Gene Network Prediction
Sep 01, 2023



Effective gene network representation learning is of great importance in bioinformatics to predict/understand the relation of gene profiles and disease phenotypes. Though graph neural networks (GNNs) have been the dominant architecture for analyzing various graph-structured data like social networks, their predicting on gene networks often exhibits subpar performance. In this paper, we formally investigate the gene network representation learning problem and characterize a notion of \textit{universal graph normalization}, where graph normalization can be applied in an universal manner to maximize the expressive power of GNNs while maintaining the stability. We propose a novel UNGNN (Universal Normalized GNN) framework, which leverages universal graph normalization in both the message passing phase and readout layer to enhance the performance of a base GNN. UNGNN has a plug-and-play property and can be combined with any GNN backbone in practice. A comprehensive set of experiments on gene-network-based bioinformatical tasks demonstrates that our UNGNN model significantly outperforms popular GNN benchmarks and provides an overall performance improvement of 16 $\%$ on average compared to previous state-of-the-art (SOTA) baselines. Furthermore, we also evaluate our theoretical findings on other graph datasets where the universal graph normalization is solvable, and we observe that UNGNN consistently achieves the superior performance.
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.
Both Efficiency and Effectiveness! A Large Scale Pre-ranking Framework in Search System
Apr 05, 2023



In the realm of search systems, multi-stage cascade architecture is a prevalent method, typically consisting of sequential modules such as matching, pre-ranking, and ranking. It is generally acknowledged that the model used in the pre-ranking stage must strike a balance between efficacy and efficiency. Thus, the most commonly employed architecture is the representation-focused vector product based model. However, this architecture lacks effective interaction between the query and document, resulting in a reduction in the effectiveness of the search system. To address this issue, we present a novel pre-ranking framework called RankDFM. Our framework leverages DeepFM as the backbone and employs a pairwise training paradigm to learn the ranking of videos under a query. The capability of RankDFM to cross features provides significant improvement in offline and online A/B testing performance. Furthermore, we introduce a learnable feature selection scheme to optimize the model and reduce the time required for online inference, equivalent to a tree model. Currently, RankDFM has been deployed in the search system of a shortvideo App, providing daily services to hundreds of millions users.
SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks
Feb 28, 2023As the size of large language models continue to scale, so does the computational resources required to run it. Spiking neural networks (SNNs) have emerged as an energy-efficient approach to deep learning that leverage sparse and event-driven activations to reduce the computational overhead associated with model inference. While they have become competitive with non-spiking models on many computer vision tasks, SNNs have also proven to be more challenging to train. As a result, their performance lags behind modern deep learning, and we are yet to see the effectiveness of SNNs in language generation. In this paper, inspired by the RWKV language model, we successfully implement `SpikeGPT', a generative language model with pure binary, event-driven spiking activation units. We train the proposed model on three model variants: 45M, 125M and 260M parameters. To the best of our knowledge, this is 4x larger than any functional backprop-trained SNN to date. We achieve this by modifying the transformer block to replace multi-head self attention to reduce quadratic computational complexity to linear with increasing sequence length. Input tokens are instead streamed in sequentially to our attention mechanism (as with typical SNNs). Our preliminary experiments show that SpikeGPT remains competitive with non-spiking models on tested benchmarks, while maintaining 5x less energy consumption when processed on neuromorphic hardware that can leverage sparse, event-driven activations. Our code implementation is available at https://github.com/ridgerchu/SpikeGPT.
TCJA-SNN: Temporal-Channel Joint Attention for Spiking Neural Networks
Jun 21, 2022
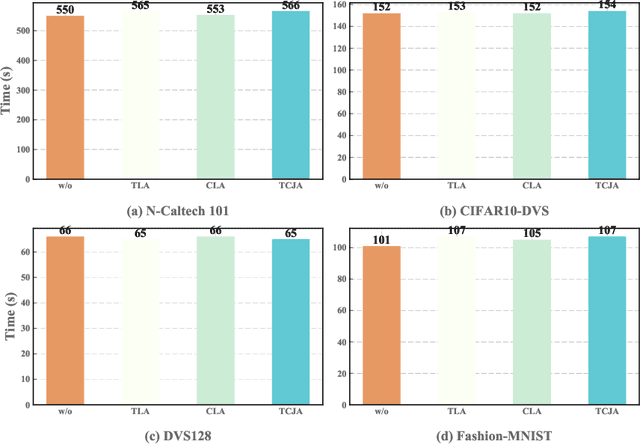
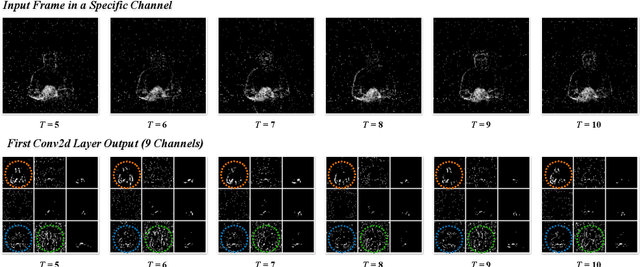

Spiking Neural Networks (SNNs) is a practical approach toward more data-efficient deep learning by simulating neurons leverage on temporal information. In this paper, we propose the Temporal-Channel Joint Attention (TCJA) architectural unit, an efficient SNN technique that depends on attention mechanisms, by effectively enforcing the relevance of spike sequence along both spatial and temporal dimensions. Our essential technical contribution lies on: 1) compressing the spike stream into an average matrix by employing the squeeze operation, then using two local attention mechanisms with an efficient 1-D convolution to establish temporal-wise and channel-wise relations for feature extraction in a flexible fashion. 2) utilizing the Cross Convolutional Fusion (CCF) layer for modeling inter-dependencies between temporal and channel scope, which breaks the independence of the two dimensions and realizes the interaction between features. By virtue of jointly exploring and recalibrating data stream, our method outperforms the state-of-the-art (SOTA) by up to 15.7% in terms of top-1 classification accuracy on all tested mainstream static and neuromorphic datasets, including Fashion-MNIST, CIFAR10-DVS, N-Caltech 101, and DVS128 Gesture.