 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning AI Research with the Needs of Clinical Coding Workflows: Eight Recommendations Based on US Data Analysis and Critical Review
Dec 23, 2024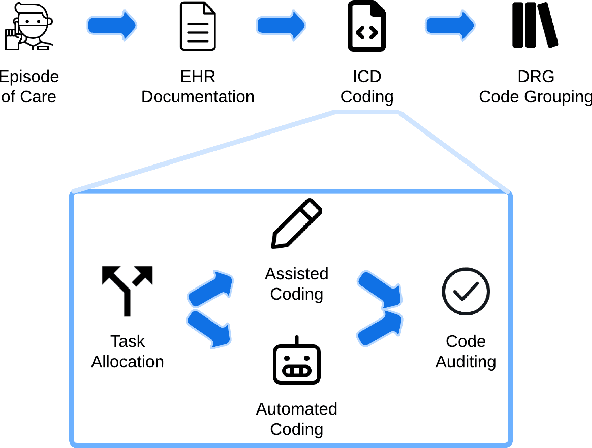
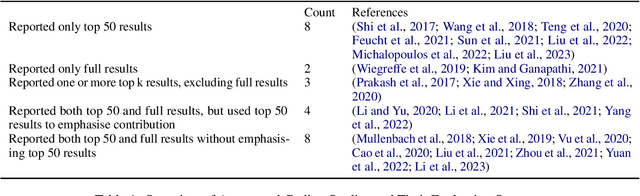
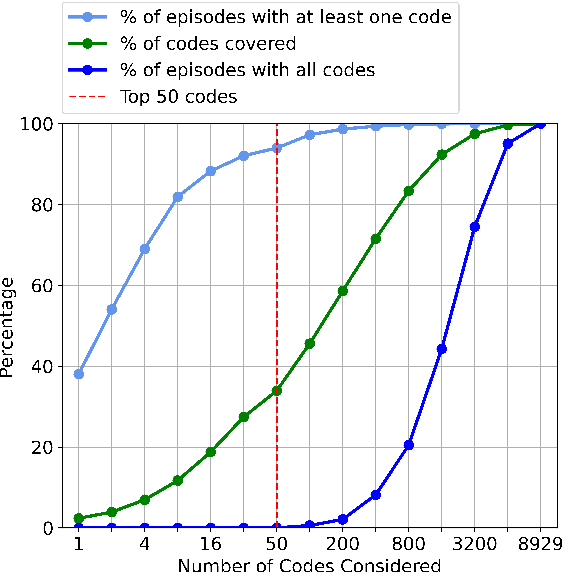

Clinical coding is crucial for healthcare billing and data analysis. Manual clinical coding is labour-intensive and error-prone, which has motivated research towards full automation of the process. However, our analysis, based on US English electronic health records and automated coding research using these records, shows that widely used evaluation methods are not aligned with real clinical contexts. For example, evaluations that focus on the top 50 most common codes are an oversimplification, as there are thousands of codes used in practice. This position paper aims to align AI coding research more closely with practical challenges of clinical coding. Based on our analysis, we offer eight specific recommendations, suggesting ways to improve current evaluation methods. Additionally, we propose new AI-based methods beyond automated coding, suggesting alternative approaches to assist clinical coders in their workflows.
Causal Graph Discovery with Retrieval-Augmented Generation based Large Language Models
Feb 23, 2024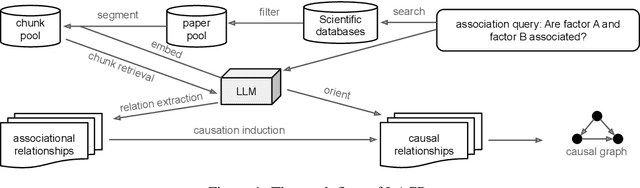
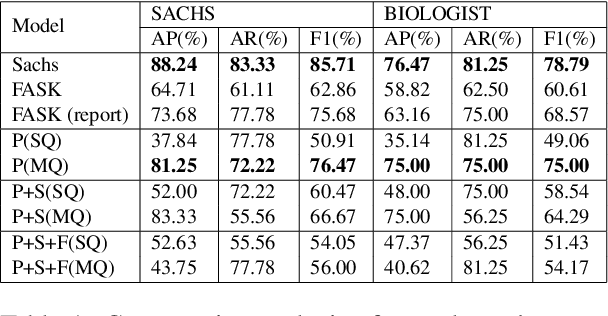
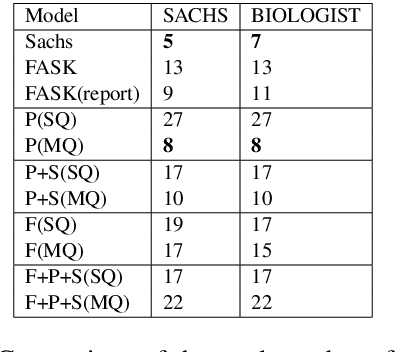

Causal graph recovery is essential in the field of causal inference. Traditional methods are typically knowledge-based or statistical estimation-based, which are limited by data collection biases and individuals' knowledge about factors affecting the relations between variables of interests. The advance of large language models (LLMs) provides opportunities to address these problems. We propose a novel method that utilizes the extensive knowledge contained within a large corpus of scientific literature to deduce causal relationships in general causal graph recovery tasks. This method leverages Retrieval Augmented-Generation (RAG) based LLMs to systematically analyze and extract pertinent information from a comprehensive collection of research papers. Our method first retrieves relevant text chunks from the aggregated literature. Then, the LLM is tasked with identifying and labelling potential associations between factors. Finally, we give a method to aggregate the associational relationships to build a causal graph. We demonstrate our method is able to construct high quality causal graphs on the well-known SACHS dataset solely from literature.
Jaeger: A Concatenation-Based Multi-Transformer VQA Model
Oct 19, 2023

Document-based Visual Question Answering poses a challenging task between linguistic sense disambiguation and fine-grained multimodal retrieval. Although there has been encouraging progress in document-based question answering due to the utilization of large language and open-world prior models\cite{1}, several challenges persist, including prolonged response times, extended inference durations, and imprecision in matching. In order to overcome these challenges, we propose Jaegar, a concatenation-based multi-transformer VQA model. To derive question features, we leverage the exceptional capabilities of RoBERTa large\cite{2} and GPT2-xl\cite{3} as feature extractors. Subsequently, we subject the outputs from both models to a concatenation process. This operation allows the model to consider information from diverse sources concurrently, strengthening its representational capability. By leveraging pre-trained models for feature extraction, our approach has the potential to amplify the performance of these models through concatenation. After concatenation, we apply dimensionality reduction to the output features, reducing the model's computational effectiveness and inference time. Empirical results demonstrate that our proposed model achieves competitive performance on Task C of the PDF-VQA Dataset. If the user adds any new data, they should make sure to style it as per the instructions provided in previous sections.