 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning AI Research with the Needs of Clinical Coding Workflows: Eight Recommendations Based on US Data Analysis and Critical Review
Dec 23, 2024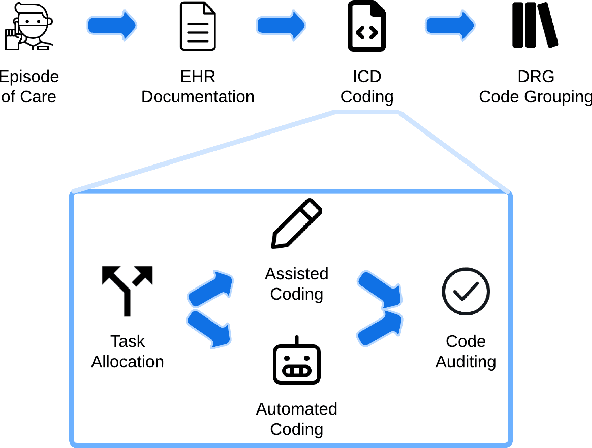
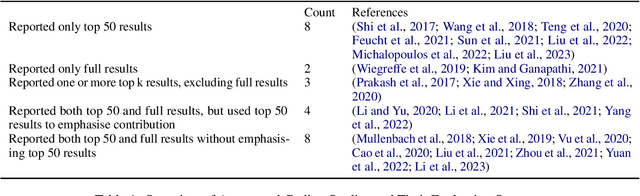
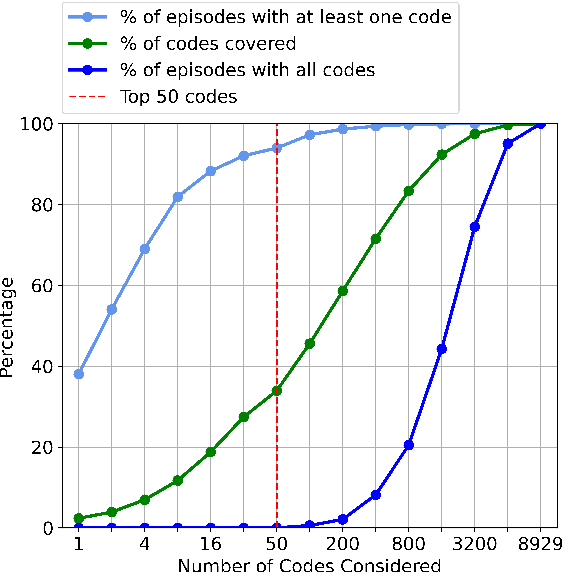

Clinical coding is crucial for healthcare billing and data analysis. Manual clinical coding is labour-intensive and error-prone, which has motivated research towards full automation of the process. However, our analysis, based on US English electronic health records and automated coding research using these records, shows that widely used evaluation methods are not aligned with real clinical contexts. For example, evaluations that focus on the top 50 most common codes are an oversimplification, as there are thousands of codes used in practice. This position paper aims to align AI coding research more closely with practical challenges of clinical coding. Based on our analysis, we offer eight specific recommendations, suggesting ways to improve current evaluation methods. Additionally, we propose new AI-based methods beyond automated coding, suggesting alternative approaches to assist clinical coders in their workflows.
MultiADE: A Multi-domain Benchmark for Adverse Drug Event Extraction
May 28, 2024
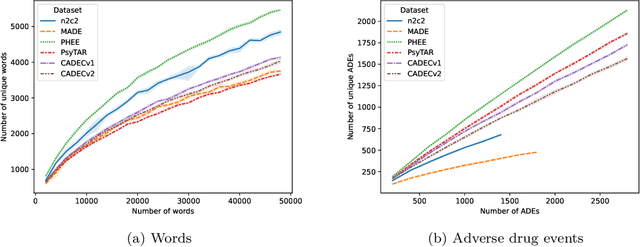
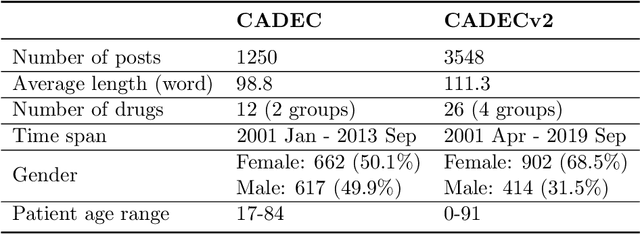
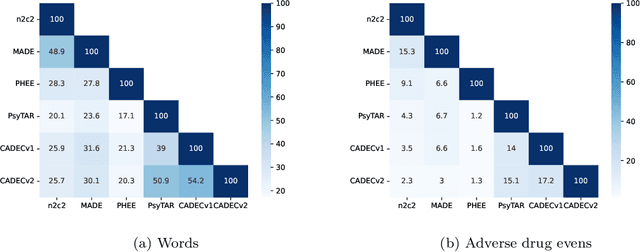
Objective. Active adverse event surveillance monitors Adverse Drug Events (ADE) from different data sources, such as electronic health records, medical literature, social media and search engine logs. Over years, many datasets are created, and shared tasks are organised to facilitate active adverse event surveillance. However, most-if not all-datasets or shared tasks focus on extracting ADEs from a particular type of text. Domain generalisation-the ability of a machine learning model to perform well on new, unseen domains (text types)-is under-explored. Given the rapid advancements in natural language processing, one unanswered question is how far we are from having a single ADE extraction model that are effective on various types of text, such as scientific literature and social media posts}. Methods. We contribute to answering this question by building a multi-domain benchmark for adverse drug event extraction, which we named MultiADE. The new benchmark comprises several existing datasets sampled from different text types and our newly created dataset-CADECv2, which is an extension of CADEC (Karimi, et al., 2015), covering online posts regarding more diverse drugs than CADEC. Our new dataset is carefully annotated by human annotators following detailed annotation guidelines. Conclusion. Our benchmark results show that the generalisation of the trained models is far from perfect, making it infeasible to be deployed to process different types of text. In addition, although intermediate transfer learning is a promising approach to utilising existing resources, further investigation is needed on methods of domain adaptation, particularly cost-effective methods to select useful training instances.
Cost-effective Selection of Pretraining Data: A Case Study of Pretraining BERT on Social Media
Oct 02, 2020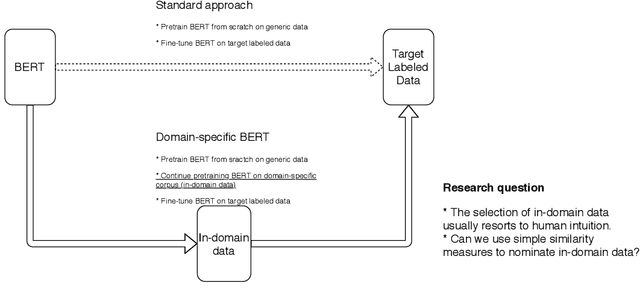

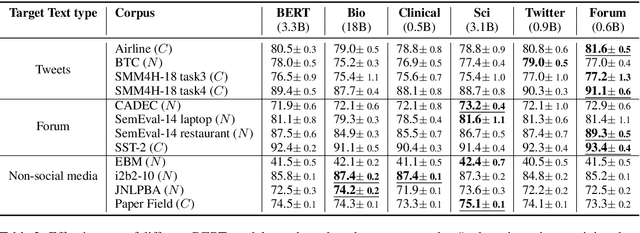
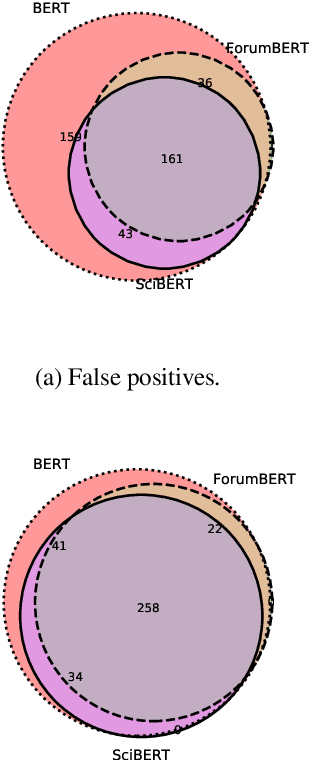
Recent studies on domain-specific BERT models show that effectiveness on downstream tasks can be improved when models are pretrained on in-domain data. Often, the pretraining data used in these models are selected based on their subject matter, e.g., biology or computer science. Given the range of applications using social media text, and its unique language variety, we pretrain two models on tweets and forum text respectively, and empirically demonstrate the effectiveness of these two resources. In addition, we investigate how similarity measures can be used to nominate in-domain pretraining data. We publicly release our pretrained models at https://bit.ly/35RpTf0.
An Effective Transition-based Model for Discontinuous NER
Apr 28, 2020
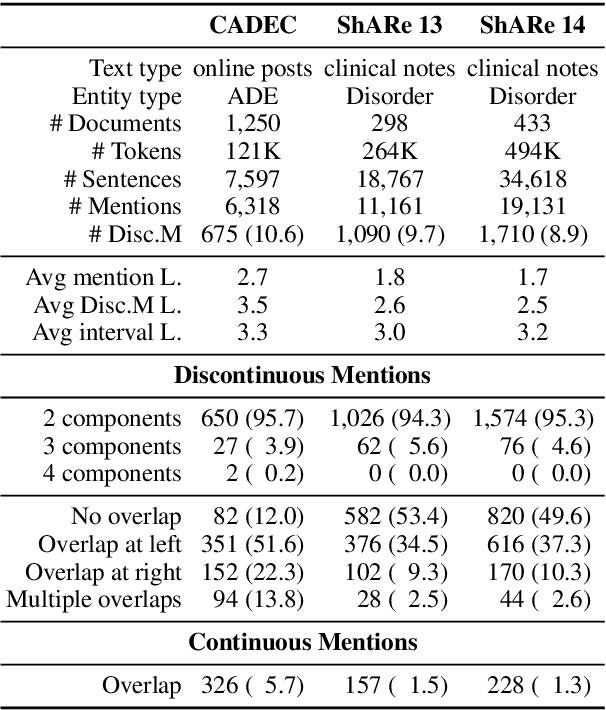
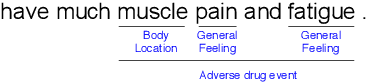
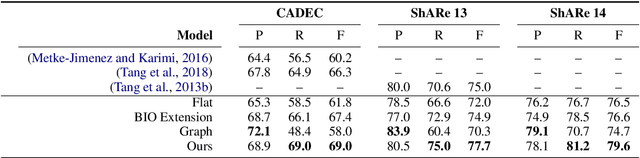
Unlike widely used Named Entity Recognition (NER) data sets in generic domains, biomedical NER data sets often contain mentions consisting of discontinuous spans. Conventional sequence tagging techniques encode Markov assumptions that are efficient but preclude recovery of these mentions. We propose a simple, effective transition-based model with generic neural encoding for discontinuous NER. Through extensive experiments on three biomedical data sets, we show that our model can effectively recognize discontinuous mentions without sacrificing the accuracy on continuous mentions.
NNE: A Dataset for Nested Named Entity Recognition in English Newswire
Jun 04, 2019

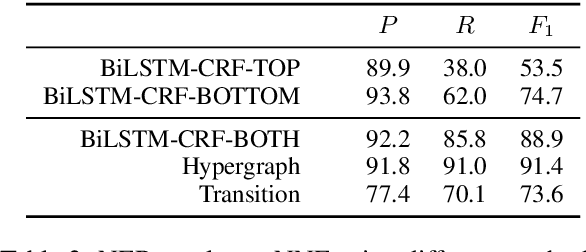

Named entity recognition (NER) is widely used in natural language processing applications and downstream tasks. However, most NER tools target flat annotation from popular datasets, eschewing the semantic information available in nested entity mentions. We describe NNE---a fine-grained, nested named entity dataset over the full Wall Street Journal portion of the Penn Treebank (PTB). Our annotation comprises 279,795 mentions of 114 entity types with up to 6 layers of nesting. We hope the public release of this large dataset for English newswire will encourage development of new techniques for nested NER.
Using Similarity Measures to Select Pretraining Data for NER
May 17, 2019

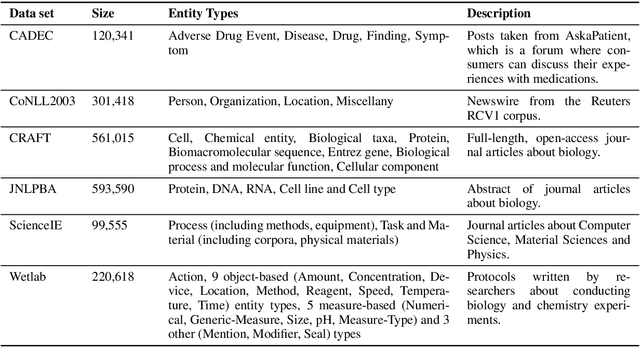
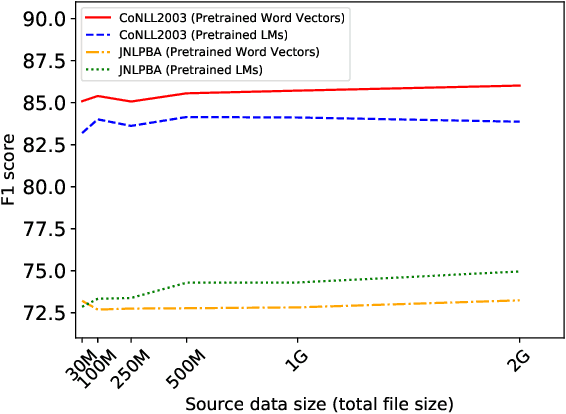
Word vectors and Language Models (LMs) pretrained on a large amount of unlabelled data can dramatically improve various Natural Language Processing (NLP) tasks. However, the measure and impact of similarity between pretraining data and target task data are left to intuition. We propose three cost-effective measures to quantify different aspects of similarity between source pretraining and target task data. We demonstrate that these measures are good predictors of the usefulness of pretrained models for Named Entity Recognition (NER) over 30 data pairs. Results also suggest that pretrained LMs are more effective and more predictable than pretrained word vectors, but pretrained word vectors are better when pretraining data is dissimilar.
Learning to generate one-sentence biographies from Wikidata
Feb 21, 2017



We investigate the generation of one-sentence Wikipedia biographies from facts derived from Wikidata slot-value pairs. We train a recurrent neural network sequence-to-sequence model with attention to select facts and generate textual summaries. Our model incorporates a novel secondary objective that helps ensure it generates sentences that contain the input facts. The model achieves a BLEU score of 41, improving significantly upon the vanilla sequence-to-sequence model and scoring roughly twice that of a simple template baseline. Human preference evaluation suggests the model is nearly as good as the Wikipedia reference. Manual analysis explores content selection, suggesting the model can trade the ability to infer knowledge against the risk of hallucinating incorrect information.
Post-edit Analysis of Collective Biography Generation
Feb 20, 2017

Text generation is increasingly common but often requires manual post-editing where high precision is critical to end users. However, manual editing is expensive so we want to ensure this effort is focused on high-value tasks. And we want to maintain stylistic consistency, a particular challenge in crowd settings. We present a case study, analysing human post-editing in the context of a template-based biography generation system. An edit flow visualisation combined with manual characterisation of edits helps identify and prioritise work for improving end-to-end efficiency and accuracy.
:telephone::person::sailboat::whale::okhand:; or "Call me Ishmael" - How do you translate emoji?
Nov 07, 2016
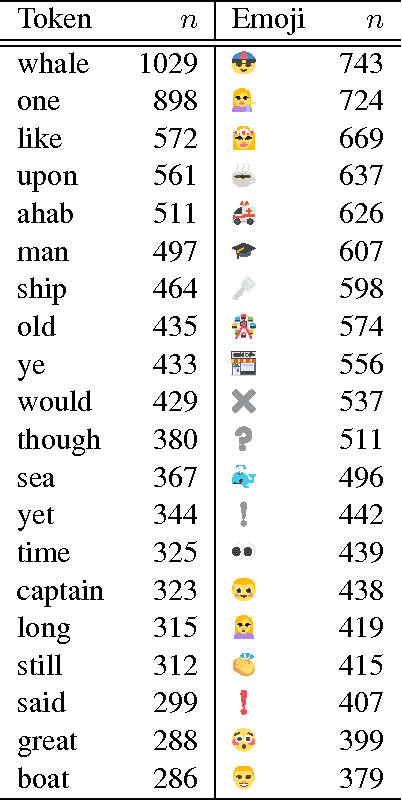
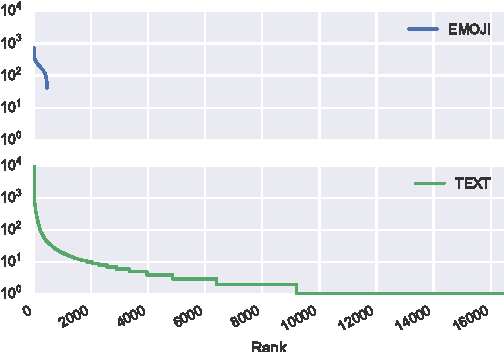
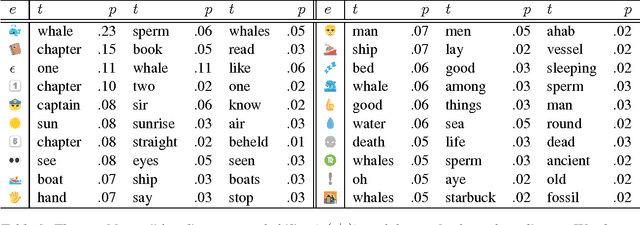
We report on an exploratory analysis of Emoji Dick, a project that leverages crowdsourcing to translate Melville's Moby Dick into emoji. This distinctive use of emoji removes textual context, and leads to a varying translation quality. In this paper, we use statistical word alignment and part-of-speech tagging to explore how people use emoji. Despite these simple methods, we observed differences in token and part-of-speech distributions. Experiments also suggest that semantics are preserved in the translation, and repetition is more common in emoji.
Presenting a New Dataset for the Timeline Generation Problem
Nov 07, 2016



The timeline generation task summarises an entity's biography by selecting stories representing key events from a large pool of relevant documents. This paper addresses the lack of a standard dataset and evaluative methodology for the problem. We present and make publicly available a new dataset of 18,793 news articles covering 39 entities. For each entity, we provide a gold standard timeline and a set of entity-related articles. We propose ROUGE as an evaluation metric and validate our dataset by showing that top Google results outperform straw-man baselines.