 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to generate one-sentence biographies from Wikidata
Feb 21, 2017



We investigate the generation of one-sentence Wikipedia biographies from facts derived from Wikidata slot-value pairs. We train a recurrent neural network sequence-to-sequence model with attention to select facts and generate textual summaries. Our model incorporates a novel secondary objective that helps ensure it generates sentences that contain the input facts. The model achieves a BLEU score of 41, improving significantly upon the vanilla sequence-to-sequence model and scoring roughly twice that of a simple template baseline. Human preference evaluation suggests the model is nearly as good as the Wikipedia reference. Manual analysis explores content selection, suggesting the model can trade the ability to infer knowledge against the risk of hallucinating incorrect information.
Post-edit Analysis of Collective Biography Generation
Feb 20, 2017

Text generation is increasingly common but often requires manual post-editing where high precision is critical to end users. However, manual editing is expensive so we want to ensure this effort is focused on high-value tasks. And we want to maintain stylistic consistency, a particular challenge in crowd settings. We present a case study, analysing human post-editing in the context of a template-based biography generation system. An edit flow visualisation combined with manual characterisation of edits helps identify and prioritise work for improving end-to-end efficiency and accuracy.
:telephone::person::sailboat::whale::okhand:; or "Call me Ishmael" - How do you translate emoji?
Nov 07, 2016
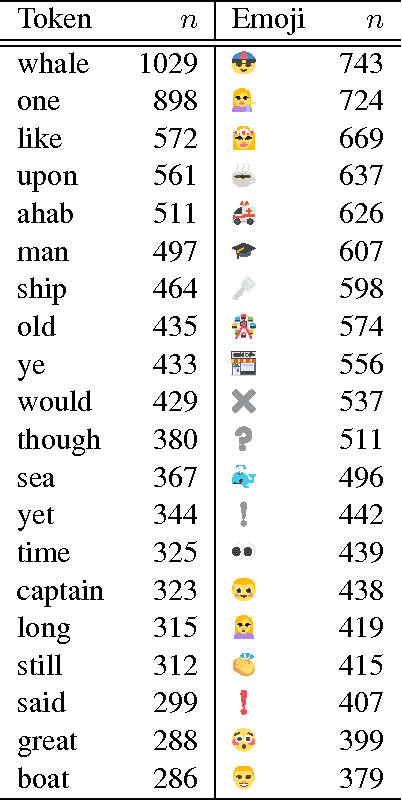
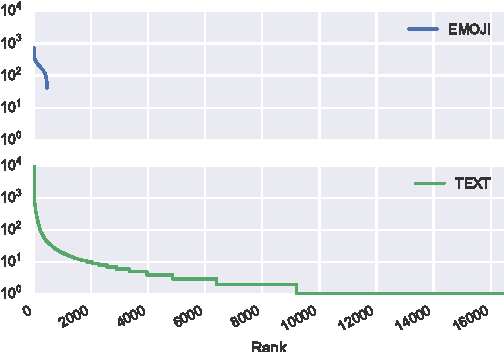
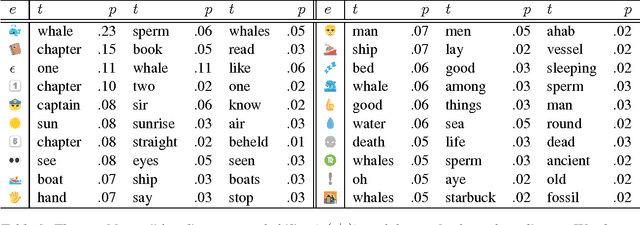
We report on an exploratory analysis of Emoji Dick, a project that leverages crowdsourcing to translate Melville's Moby Dick into emoji. This distinctive use of emoji removes textual context, and leads to a varying translation quality. In this paper, we use statistical word alignment and part-of-speech tagging to explore how people use emoji. Despite these simple methods, we observed differences in token and part-of-speech distributions. Experiments also suggest that semantics are preserved in the translation, and repetition is more common in emoji.