Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-effective Selection of Pretraining Data: A Case Study of Pretraining BERT on Social Media
Paper and Code
Oct 02, 2020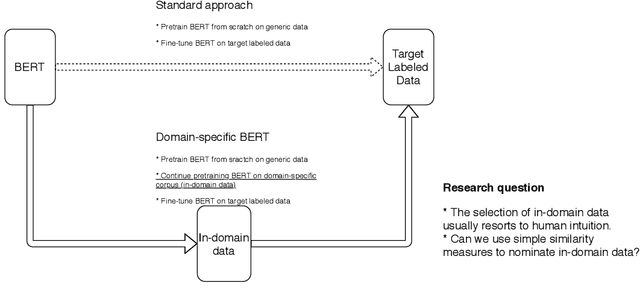

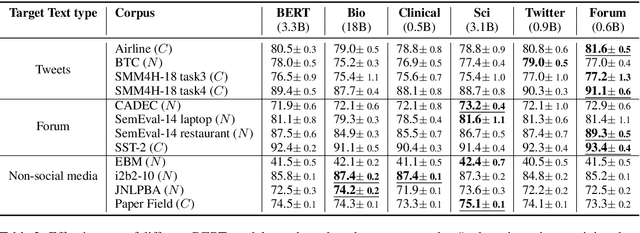
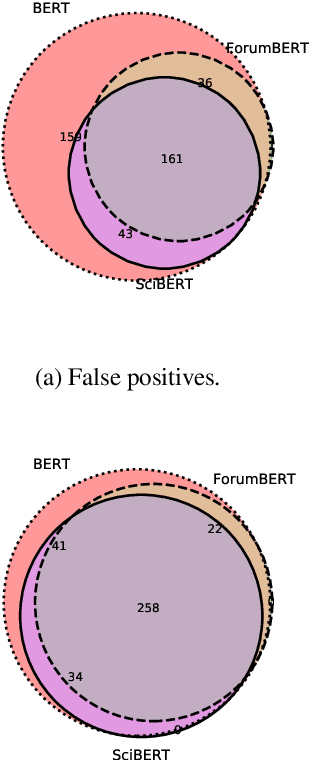
Recent studies on domain-specific BERT models show that effectiveness on downstream tasks can be improved when models are pretrained on in-domain data. Often, the pretraining data used in these models are selected based on their subject matter, e.g., biology or computer science. Given the range of applications using social media text, and its unique language variety, we pretrain two models on tweets and forum text respectively, and empirically demonstrate the effectiveness of these two resources. In addition, we investigate how similarity measures can be used to nominate in-domain pretraining data. We publicly release our pretrained models at https://bit.ly/35RpTf0.
* Findings of EMNLP 2020
View paper on