 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiADE: A Multi-domain Benchmark for Adverse Drug Event Extraction
Paper and Code
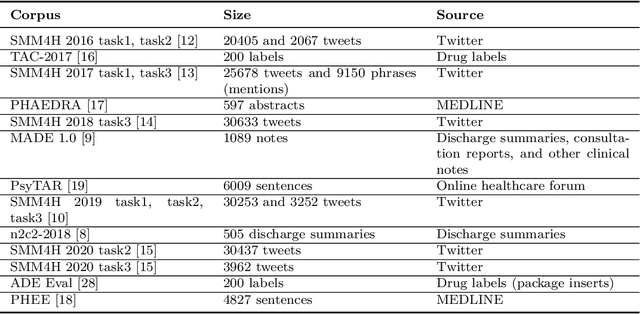
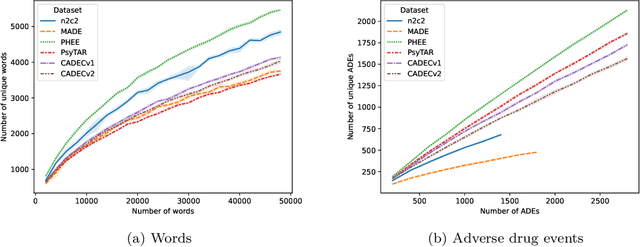
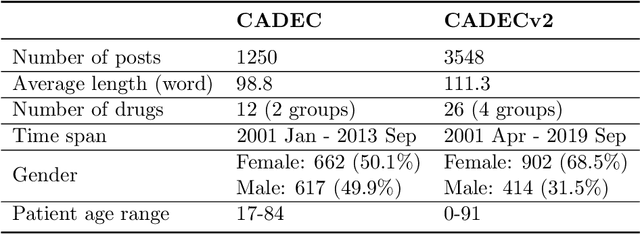
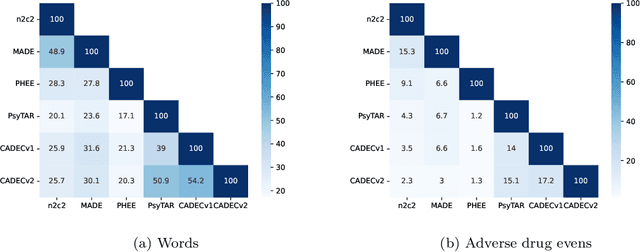
Objective. Active adverse event surveillance monitors Adverse Drug Events (ADE) from different data sources, such as electronic health records, medical literature, social media and search engine logs. Over years, many datasets are created, and shared tasks are organised to facilitate active adverse event surveillance. However, most-if not all-datasets or shared tasks focus on extracting ADEs from a particular type of text. Domain generalisation-the ability of a machine learning model to perform well on new, unseen domains (text types)-is under-explored. Given the rapid advancements in natural language processing, one unanswered question is how far we are from having a single ADE extraction model that are effective on various types of text, such as scientific literature and social media posts}. Methods. We contribute to answering this question by building a multi-domain benchmark for adverse drug event extraction, which we named MultiADE. The new benchmark comprises several existing datasets sampled from different text types and our newly created dataset-CADECv2, which is an extension of CADEC (Karimi, et al., 2015), covering online posts regarding more diverse drugs than CADEC. Our new dataset is carefully annotated by human annotators following detailed annotation guidelines. Conclusion. Our benchmark results show that the generalisation of the trained models is far from perfect, making it infeasible to be deployed to process different types of text. In addition, although intermediate transfer learning is a promising approach to utilising existing resources, further investigation is needed on methods of domain adaptation, particularly cost-effective methods to select useful training instances.