 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNNE: A Dataset for Nested Named Entity Recognition in English Newswire
Jun 04, 2019

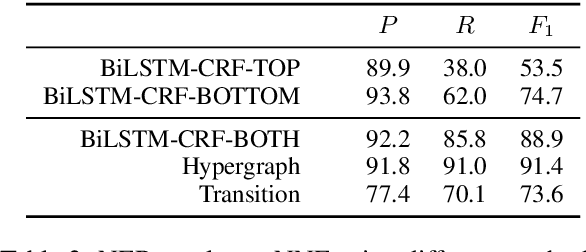

Named entity recognition (NER) is widely used in natural language processing applications and downstream tasks. However, most NER tools target flat annotation from popular datasets, eschewing the semantic information available in nested entity mentions. We describe NNE---a fine-grained, nested named entity dataset over the full Wall Street Journal portion of the Penn Treebank (PTB). Our annotation comprises 279,795 mentions of 114 entity types with up to 6 layers of nesting. We hope the public release of this large dataset for English newswire will encourage development of new techniques for nested NER.
Web-scale Surface and Syntactic n-gram Features for Dependency Parsing
Feb 25, 2015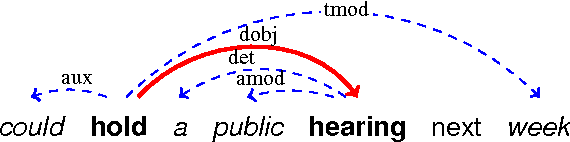
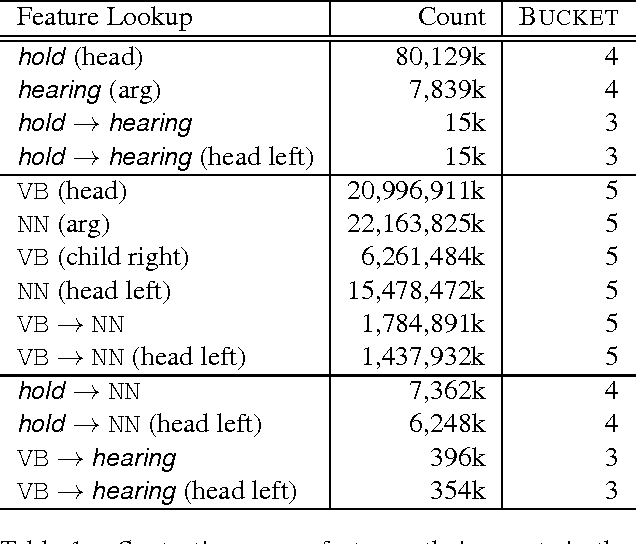

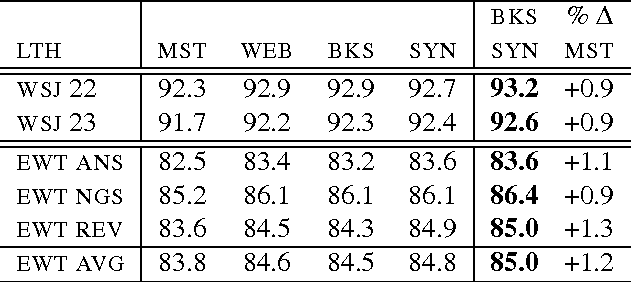
We develop novel first- and second-order features for dependency parsing based on the Google Syntactic Ngrams corpus, a collection of subtree counts of parsed sentences from scanned books. We also extend previous work on surface $n$-gram features from Web1T to the Google Books corpus and from first-order to second-order, comparing and analysing performance over newswire and web treebanks. Surface and syntactic $n$-grams both produce substantial and complementary gains in parsing accuracy across domains. Our best system combines the two feature sets, achieving up to 0.8% absolute UAS improvements on newswire and 1.4% on web text.