Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb-scale Surface and Syntactic n-gram Features for Dependency Parsing
Paper and Code
Feb 25, 2015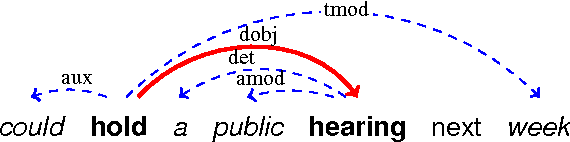
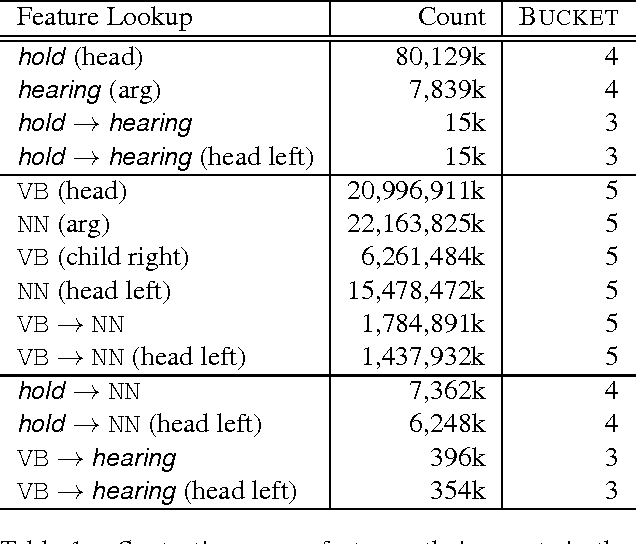

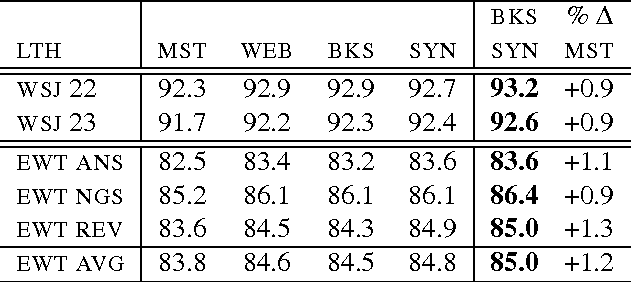
We develop novel first- and second-order features for dependency parsing based on the Google Syntactic Ngrams corpus, a collection of subtree counts of parsed sentences from scanned books. We also extend previous work on surface $n$-gram features from Web1T to the Google Books corpus and from first-order to second-order, comparing and analysing performance over newswire and web treebanks. Surface and syntactic $n$-grams both produce substantial and complementary gains in parsing accuracy across domains. Our best system combines the two feature sets, achieving up to 0.8% absolute UAS improvements on newswire and 1.4% on web text.
View paper on