 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry Awareness Encoded Deep Learning Framework for Brain Imaging Analysis
Jul 12, 2024


The heterogeneity of neurological conditions, ranging from structural anomalies to functional impairments, presents a significant challenge in medical imaging analysis tasks. Moreover, the limited availability of well-annotated datasets constrains the development of robust analysis models. Against this backdrop, this study introduces a novel approach leveraging the inherent anatomical symmetrical features of the human brain to enhance the subsequent detection and segmentation analysis for brain diseases. A novel Symmetry-Aware Cross-Attention (SACA) module is proposed to encode symmetrical features of left and right hemispheres, and a proxy task to detect symmetrical features as the Symmetry-Aware Head (SAH) is proposed, which guides the pretraining of the whole network on a vast 3D brain imaging dataset comprising both healthy and diseased brain images across various MRI and CT. Through meticulous experimentation on downstream tasks, including both classification and segmentation for brain diseases, our model demonstrates superior performance over state-of-the-art methodologies, particularly highlighting the significance of symmetry-aware learning. Our findings advocate for the effectiveness of incorporating symmetry awareness into pretraining and set a new benchmark for medical imaging analysis, promising significant strides toward accurate and efficient diagnostic processes. Code is available at https://github.com/bitMyron/sa-swin.
How Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks
Apr 04, 2024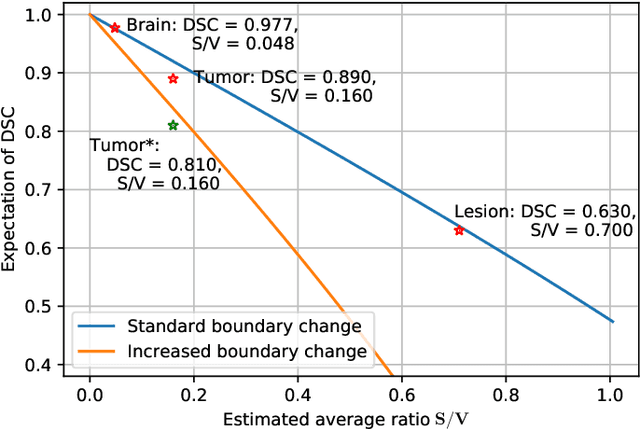
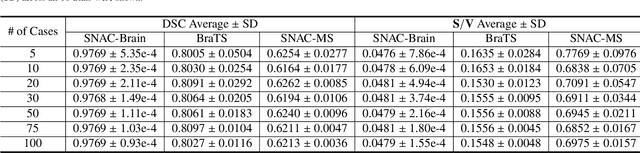

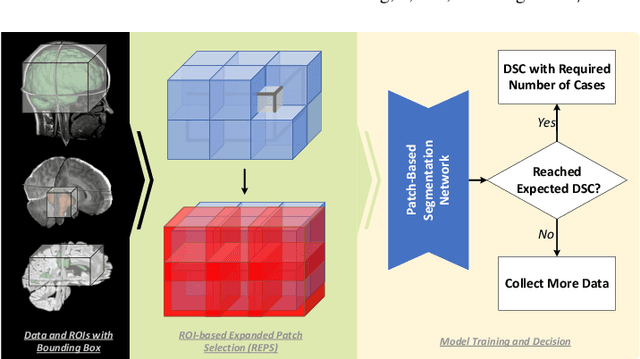
Training deep neural networks reliably requires access to large-scale datasets. However, obtaining such datasets can be challenging, especially in the context of neuroimaging analysis tasks, where the cost associated with image acquisition and annotation can be prohibitive. To mitigate both the time and financial costs associated with model development, a clear understanding of the amount of data required to train a satisfactory model is crucial. This paper focuses on an early stage phase of deep learning research, prior to model development, and proposes a strategic framework for estimating the amount of annotated data required to train patch-based segmentation networks. This framework includes the establishment of performance expectations using a novel Minor Boundary Adjustment for Threshold (MinBAT) method, and standardizing patch selection through the ROI-based Expanded Patch Selection (REPS) method. Our experiments demonstrate that tasks involving regions of interest (ROIs) with different sizes or shapes may yield variably acceptable Dice Similarity Coefficient (DSC) scores. By setting an acceptable DSC as the target, the required amount of training data can be estimated and even predicted as data accumulates. This approach could assist researchers and engineers in estimating the cost associated with data collection and annotation when defining a new segmentation task based on deep neural networks, ultimately contributing to their efficient translation to real-world applications.
Improving Multiple Sclerosis Lesion Segmentation Across Clinical Sites: A Federated Learning Approach with Noise-Resilient Training
Aug 31, 2023



Accurately measuring the evolution of Multiple Sclerosis (MS) with magnetic resonance imaging (MRI) critically informs understanding of disease progression and helps to direct therapeutic strategy. Deep learning models have shown promise for automatically segmenting MS lesions, but the scarcity of accurately annotated data hinders progress in this area. Obtaining sufficient data from a single clinical site is challenging and does not address the heterogeneous need for model robustness. Conversely, the collection of data from multiple sites introduces data privacy concerns and potential label noise due to varying annotation standards. To address this dilemma, we explore the use of the federated learning framework while considering label noise. Our approach enables collaboration among multiple clinical sites without compromising data privacy under a federated learning paradigm that incorporates a noise-robust training strategy based on label correction. Specifically, we introduce a Decoupled Hard Label Correction (DHLC) strategy that considers the imbalanced distribution and fuzzy boundaries of MS lesions, enabling the correction of false annotations based on prediction confidence. We also introduce a Centrally Enhanced Label Correction (CELC) strategy, which leverages the aggregated central model as a correction teacher for all sites, enhancing the reliability of the correction process. Extensive experiments conducted on two multi-site datasets demonstrate the effectiveness and robustness of our proposed methods, indicating their potential for clinical applications in multi-site collaborations.
MS Lesion Segmentation: Revisiting Weighting Mechanisms for Federated Learning
May 03, 2022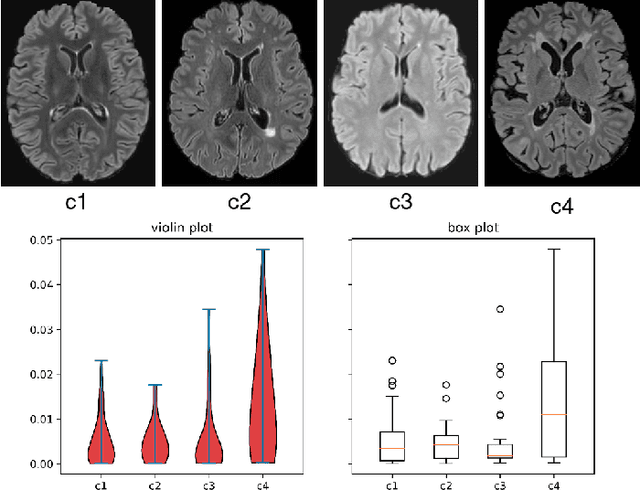
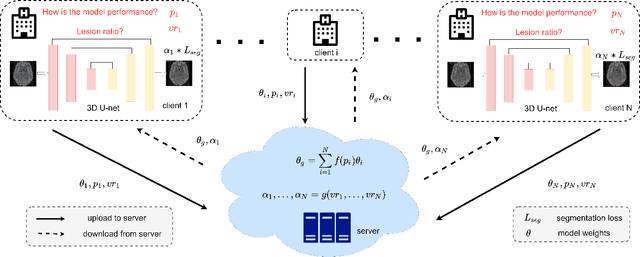
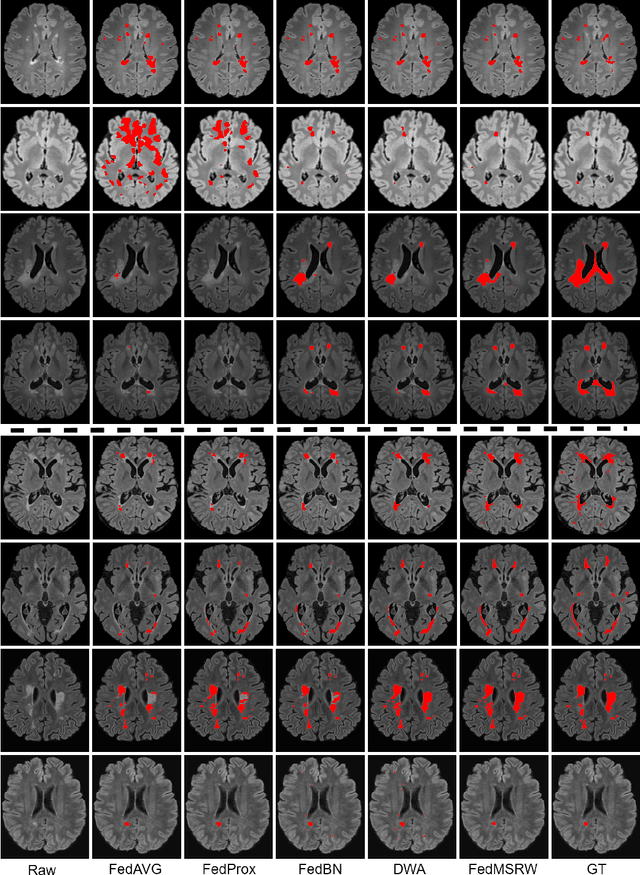

Federated learning (FL) has been widely employed for medical image analysis to facilitate multi-client collaborative learning without sharing raw data. Despite great success, FL's performance is limited for multiple sclerosis (MS) lesion segmentation tasks, due to variance in lesion characteristics imparted by different scanners and acquisition parameters. In this work, we propose the first FL MS lesion segmentation framework via two effective re-weighting mechanisms. Specifically, a learnable weight is assigned to each local node during the aggregation process, based on its segmentation performance. In addition, the segmentation loss function in each client is also re-weighted according to the lesion volume for the data during training. Comparison experiments on two FL MS segmentation scenarios using public and clinical datasets have demonstrated the effectiveness of the proposed method by outperforming other FL methods significantly. Furthermore, the segmentation performance of FL incorporating our proposed aggregation mechanism can exceed centralised training with all the raw data. The extensive evaluation also indicated the superiority of our method when estimating brain volume differences estimation after lesion inpainting.
EventNet Version 1.1 Technical Report
Sep 11, 2016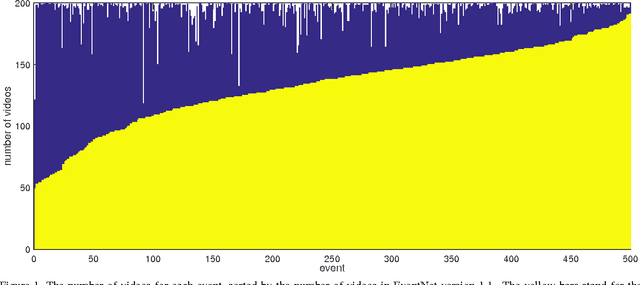

EventNet is a large-scale video corpus and event ontology consisting of 500 events associated with event-specific concepts. In order to improve the quality of the current EventNet, we conduct the following steps and introduce EventNet version 1.1: (1) manually verify the correctness of event labels for all videos; (2) remove the YouTube user bias by limiting the maximum number of videos in each event from the same YouTube user as 3; (3) remove the videos which are currently not accessible online; (4) remove the video belonging to multiple event categories. After the above procedure, some events may contain only a small number of videos, and therefore we crawl more videos for those events to ensure every event will contain more than 50 videos. Finally, EventNet version 1.1 contains 67,641 videos, 500 events, and 5,028 event-specific concepts. In addition, we train a Convolutional Neural Network (CNN) model for event classification via fine-tuning AlexNet using EventNet version 1.1. Then we use the trained CNN model to extract FC7 layer feature and train binary classifiers using linear SVM for each event-specific concept. We believe this new version of EventNet will significantly facilitate research in computer vision and multimedia, and will put it online for public downloading in the future.
Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs
Apr 21, 2016



We address temporal action localization in untrimmed long videos. This is important because videos in real applications are usually unconstrained and contain multiple action instances plus video content of background scenes or other activities. To address this challenging issue, we exploit the effectiveness of deep networks in temporal action localization via three segment-based 3D ConvNets: (1) a proposal network identifies candidate segments in a long video that may contain actions; (2) a classification network learns one-vs-all action classification model to serve as initialization for the localization network; and (3) a localization network fine-tunes on the learned classification network to localize each action instance. We propose a novel loss function for the localization network to explicitly consider temporal overlap and therefore achieve high temporal localization accuracy. Only the proposal network and the localization network are used during prediction. On two large-scale benchmarks, our approach achieves significantly superior performances compared with other state-of-the-art systems: mAP increases from 1.7% to 7.4% on MEXaction2 and increases from 15.0% to 19.0% on THUMOS 2014, when the overlap threshold for evaluation is set to 0.5.