 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks
Paper and Code
Apr 04, 2024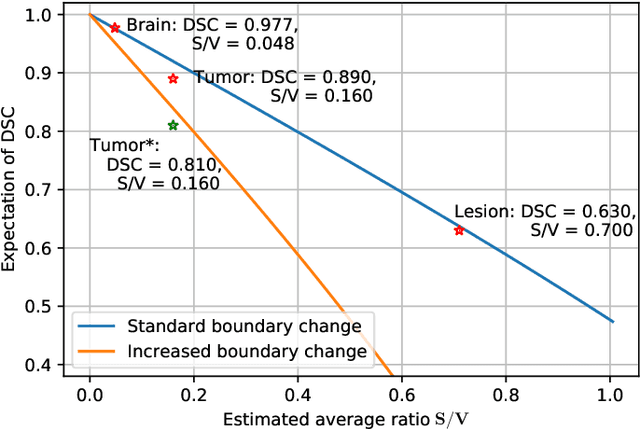
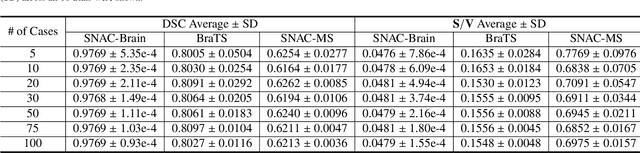

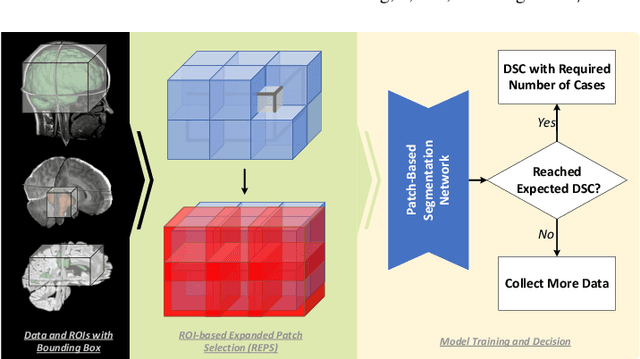
Training deep neural networks reliably requires access to large-scale datasets. However, obtaining such datasets can be challenging, especially in the context of neuroimaging analysis tasks, where the cost associated with image acquisition and annotation can be prohibitive. To mitigate both the time and financial costs associated with model development, a clear understanding of the amount of data required to train a satisfactory model is crucial. This paper focuses on an early stage phase of deep learning research, prior to model development, and proposes a strategic framework for estimating the amount of annotated data required to train patch-based segmentation networks. This framework includes the establishment of performance expectations using a novel Minor Boundary Adjustment for Threshold (MinBAT) method, and standardizing patch selection through the ROI-based Expanded Patch Selection (REPS) method. Our experiments demonstrate that tasks involving regions of interest (ROIs) with different sizes or shapes may yield variably acceptable Dice Similarity Coefficient (DSC) scores. By setting an acceptable DSC as the target, the required amount of training data can be estimated and even predicted as data accumulates. This approach could assist researchers and engineers in estimating the cost associated with data collection and annotation when defining a new segmentation task based on deep neural networks, ultimately contributing to their efficient translation to real-world applications.