 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks
Apr 04, 2024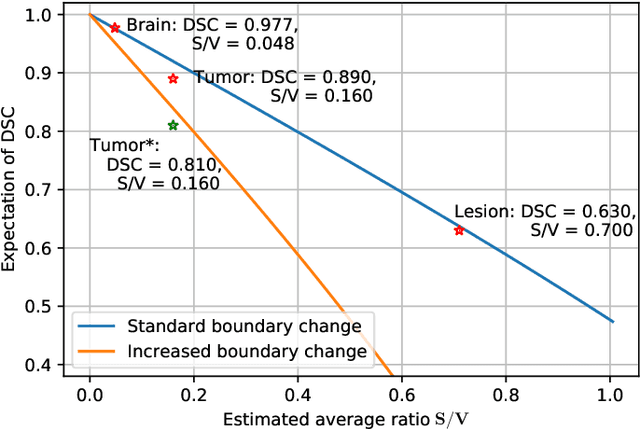
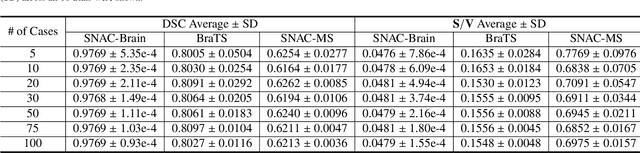

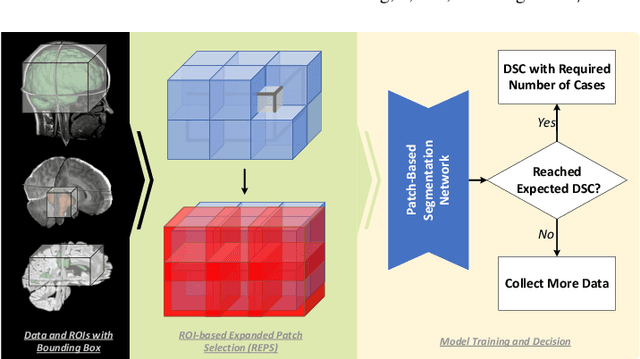
Training deep neural networks reliably requires access to large-scale datasets. However, obtaining such datasets can be challenging, especially in the context of neuroimaging analysis tasks, where the cost associated with image acquisition and annotation can be prohibitive. To mitigate both the time and financial costs associated with model development, a clear understanding of the amount of data required to train a satisfactory model is crucial. This paper focuses on an early stage phase of deep learning research, prior to model development, and proposes a strategic framework for estimating the amount of annotated data required to train patch-based segmentation networks. This framework includes the establishment of performance expectations using a novel Minor Boundary Adjustment for Threshold (MinBAT) method, and standardizing patch selection through the ROI-based Expanded Patch Selection (REPS) method. Our experiments demonstrate that tasks involving regions of interest (ROIs) with different sizes or shapes may yield variably acceptable Dice Similarity Coefficient (DSC) scores. By setting an acceptable DSC as the target, the required amount of training data can be estimated and even predicted as data accumulates. This approach could assist researchers and engineers in estimating the cost associated with data collection and annotation when defining a new segmentation task based on deep neural networks, ultimately contributing to their efficient translation to real-world applications.
Improving Multiple Sclerosis Lesion Segmentation Across Clinical Sites: A Federated Learning Approach with Noise-Resilient Training
Aug 31, 2023



Accurately measuring the evolution of Multiple Sclerosis (MS) with magnetic resonance imaging (MRI) critically informs understanding of disease progression and helps to direct therapeutic strategy. Deep learning models have shown promise for automatically segmenting MS lesions, but the scarcity of accurately annotated data hinders progress in this area. Obtaining sufficient data from a single clinical site is challenging and does not address the heterogeneous need for model robustness. Conversely, the collection of data from multiple sites introduces data privacy concerns and potential label noise due to varying annotation standards. To address this dilemma, we explore the use of the federated learning framework while considering label noise. Our approach enables collaboration among multiple clinical sites without compromising data privacy under a federated learning paradigm that incorporates a noise-robust training strategy based on label correction. Specifically, we introduce a Decoupled Hard Label Correction (DHLC) strategy that considers the imbalanced distribution and fuzzy boundaries of MS lesions, enabling the correction of false annotations based on prediction confidence. We also introduce a Centrally Enhanced Label Correction (CELC) strategy, which leverages the aggregated central model as a correction teacher for all sites, enhancing the reliability of the correction process. Extensive experiments conducted on two multi-site datasets demonstrate the effectiveness and robustness of our proposed methods, indicating their potential for clinical applications in multi-site collaborations.
MS Lesion Segmentation: Revisiting Weighting Mechanisms for Federated Learning
May 03, 2022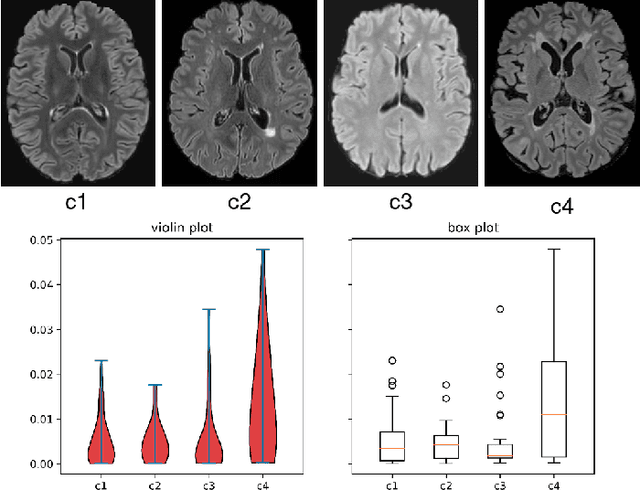
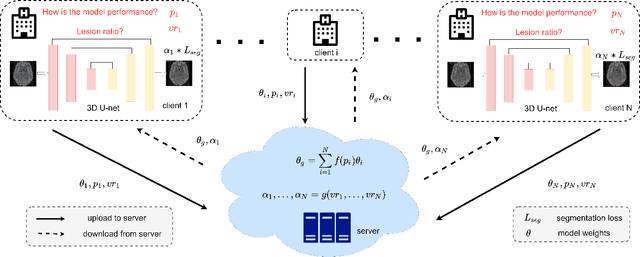
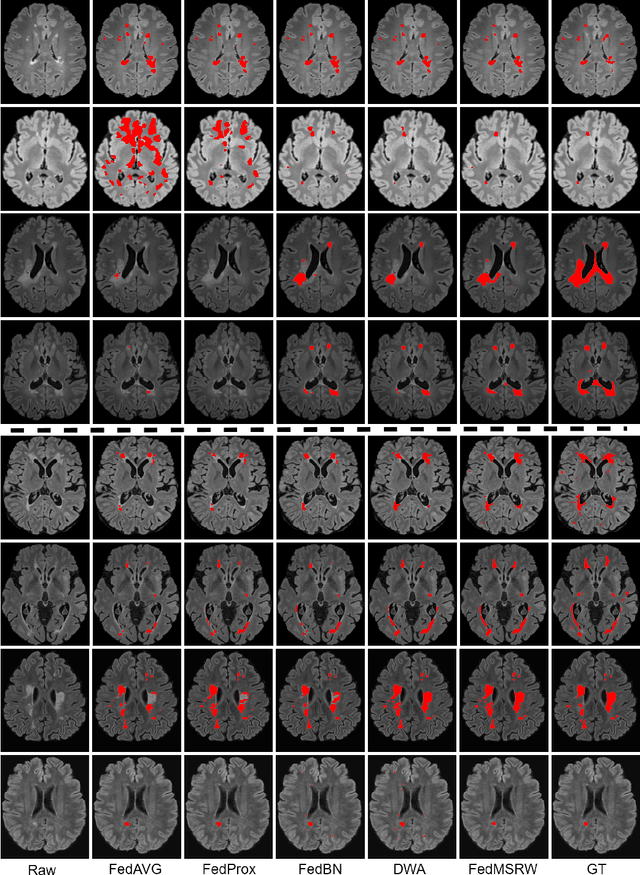

Federated learning (FL) has been widely employed for medical image analysis to facilitate multi-client collaborative learning without sharing raw data. Despite great success, FL's performance is limited for multiple sclerosis (MS) lesion segmentation tasks, due to variance in lesion characteristics imparted by different scanners and acquisition parameters. In this work, we propose the first FL MS lesion segmentation framework via two effective re-weighting mechanisms. Specifically, a learnable weight is assigned to each local node during the aggregation process, based on its segmentation performance. In addition, the segmentation loss function in each client is also re-weighted according to the lesion volume for the data during training. Comparison experiments on two FL MS segmentation scenarios using public and clinical datasets have demonstrated the effectiveness of the proposed method by outperforming other FL methods significantly. Furthermore, the segmentation performance of FL incorporating our proposed aggregation mechanism can exceed centralised training with all the raw data. The extensive evaluation also indicated the superiority of our method when estimating brain volume differences estimation after lesion inpainting.