 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-based Policy With Distributional Reinforcement Learning in Trajectory Optimization
Apr 01, 2026Reinforcement Learning (RL) has proven highly effective in addressing complex control and decision-making tasks. However, in most traditional RL algorithms, the policy is typically parameterized as a diagonal Gaussian distribution, which constrains the policy from capturing multimodal distributions, making it difficult to cover the full range of optimal solutions in multi-solution problems, and the return is reduced to a mean value, losing its multimodal nature and thus providing insufficient guidance for policy updates. In response to these problems, we propose a RL algorithm termed flow-based policy with distributional RL (FP-DRL). This algorithm models the policy using flow matching, which offers both computational efficiency and the capacity to fit complex distributions. Additionally, it employs a distributional RL approach to model and optimize the entire return distribution, thereby more effectively guiding multimodal policy updates and improving agent performance. Experimental trails on MuJoCo benchmarks demonstrate that the FP-DRL algorithm achieves state-of-the-art (SOTA) performance in most MuJoCo control tasks while exhibiting superior representation capability of the flow policy.
TrojanTO: Action-Level Backdoor Attacks against Trajectory Optimization Models
Jun 15, 2025Recent advances in Trajectory Optimization (TO) models have achieved remarkable success in offline reinforcement learning. However, their vulnerabilities against backdoor attacks are poorly understood. We find that existing backdoor attacks in reinforcement learning are based on reward manipulation, which are largely ineffective against the TO model due to its inherent sequence modeling nature. Moreover, the complexities introduced by high-dimensional action spaces further compound the challenge of action manipulation. To address these gaps, we propose TrojanTO, the first action-level backdoor attack against TO models. TrojanTO employs alternating training to enhance the connection between triggers and target actions for attack effectiveness. To improve attack stealth, it utilizes precise poisoning via trajectory filtering for normal performance and batch poisoning for trigger consistency. Extensive evaluations demonstrate that TrojanTO effectively implants backdoor attacks across diverse tasks and attack objectives with a low attack budget (0.3\% of trajectories). Furthermore, TrojanTO exhibits broad applicability to DT, GDT, and DC, underscoring its scalability across diverse TO model architectures.
Group Distributionally Robust Optimization can Suppress Class Imbalance Effect in Network Traffic Classification
Sep 28, 2024



Internet services have led to the eruption of traffic, and machine learning on these Internet data has become an indispensable tool, especially when the application is risk-sensitive. This paper focuses on network traffic classification in the presence of class imbalance, which fundamentally and ubiquitously exists in Internet data analysis. This existence of class imbalance mostly drifts the optimal decision boundary, resulting in a less optimal solution for machine learning models. To alleviate the effect, we propose to design strategies for alleviating the class imbalance through the lens of group distributionally robust optimization. Our approach iteratively updates the non-parametric weights for separate classes and optimizes the learning model by minimizing reweighted losses. We interpret the optimization steps from a Stackelberg game and perform extensive experiments on typical benchmarks. Results show that our approach can not only suppress the negative effect of class imbalance but also improve the comprehensive performance in prediction.
Is Mamba Compatible with Trajectory Optimization in Offline Reinforcement Learning?
May 20, 2024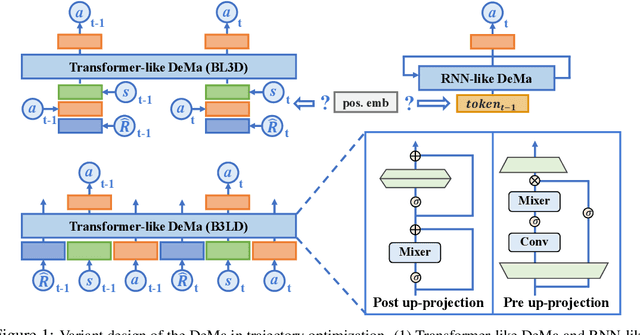
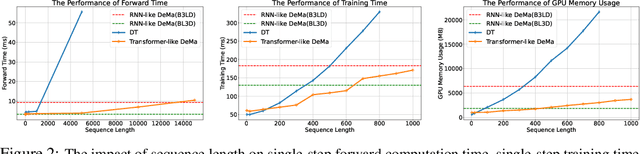
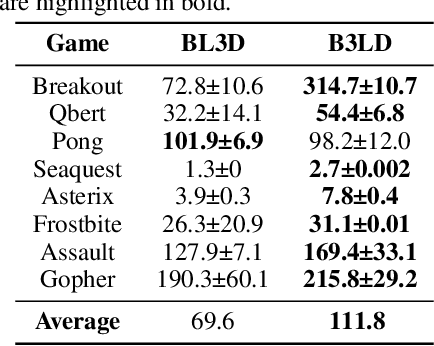
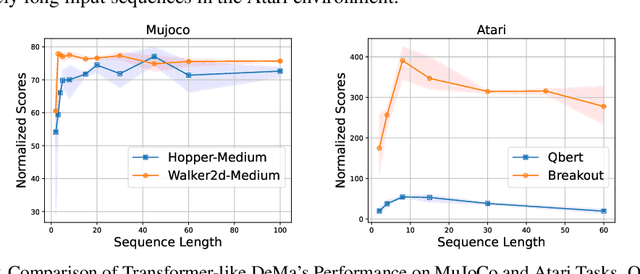
Transformer-based trajectory optimization methods have demonstrated exceptional performance in offline Reinforcement Learning (offline RL), yet it poses challenges due to substantial parameter size and limited scalability, which is particularly critical in sequential decision-making scenarios where resources are constrained such as in robots and drones with limited computational power. Mamba, a promising new linear-time sequence model, offers performance on par with transformers while delivering substantially fewer parameters on long sequences. As it remains unclear whether Mamba is compatible with trajectory optimization, this work aims to conduct comprehensive experiments to explore the potential of Decision Mamba in offline RL (dubbed DeMa) from the aspect of data structures and network architectures with the following insights: (1) Long sequences impose a significant computational burden without contributing to performance improvements due to the fact that DeMa's focus on sequences diminishes approximately exponentially. Consequently, we introduce a Transformer-like DeMa as opposed to an RNN-like DeMa. (2) For the components of DeMa, we identify that the hidden attention mechanism is key to its success, which can also work well with other residual structures and does not require position embedding. Extensive evaluations from eight Atari games demonstrate that our specially designed DeMa is compatible with trajectory optimization and surpasses previous state-of-the-art methods, outdoing Decision Transformer (DT) by 80\% with 30\% fewer parameters, and exceeds DT in MuJoCo with only a quarter of the parameters.
PTR-PPO: Proximal Policy Optimization with Prioritized Trajectory Replay
Dec 08, 2021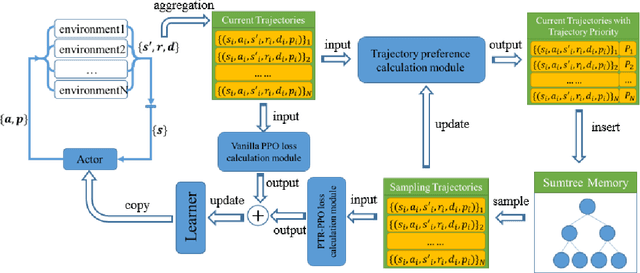
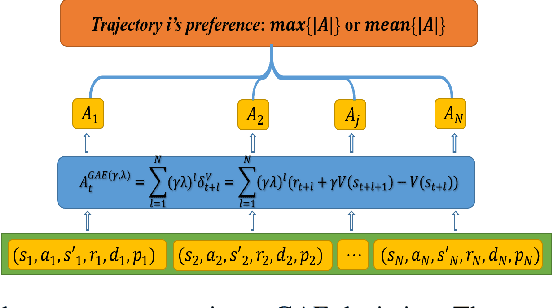

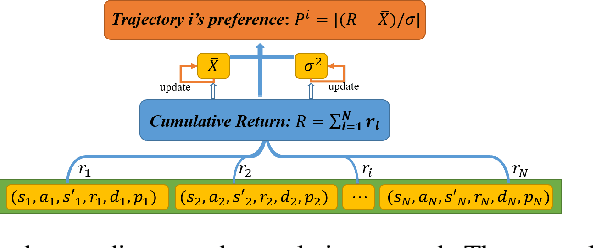
On-policy deep reinforcement learning algorithms have low data utilization and require significant experience for policy improvement. This paper proposes a proximal policy optimization algorithm with prioritized trajectory replay (PTR-PPO) that combines on-policy and off-policy methods to improve sampling efficiency by prioritizing the replay of trajectories generated by old policies. We first design three trajectory priorities based on the characteristics of trajectories: the first two being max and mean trajectory priorities based on one-step empirical generalized advantage estimation (GAE) values and the last being reward trajectory priorities based on normalized undiscounted cumulative reward. Then, we incorporate the prioritized trajectory replay into the PPO algorithm, propose a truncated importance weight method to overcome the high variance caused by large importance weights under multistep experience, and design a policy improvement loss function for PPO under off-policy conditions. We evaluate the performance of PTR-PPO in a set of Atari discrete control tasks, achieving state-of-the-art performance. In addition, by analyzing the heatmap of priority changes at various locations in the priority memory during training, we find that memory size and rollout length can have a significant impact on the distribution of trajectory priorities and, hence, on the performance of the algorithm.
VMAV-C: A Deep Attention-based Reinforcement Learning Algorithm for Model-based Control
Dec 24, 2018Recent breakthroughs in Go play and strategic games have witnessed the great potential of reinforcement learning in intelligently scheduling in uncertain environment, but some bottlenecks are also encountered when we generalize this paradigm to universal complex tasks. Among them, the low efficiency of data utilization in model-free reinforcement algorithms is of great concern. In contrast, the model-based reinforcement learning algorithms can reveal underlying dynamics in learning environments and seldom suffer the data utilization problem. To address the problem, a model-based reinforcement learning algorithm with attention mechanism embedded is proposed as an extension of World Models in this paper. We learn the environment model through Mixture Density Network Recurrent Network(MDN-RNN) for agents to interact, with combinations of variational auto-encoder(VAE) and attention incorporated in state value estimates during the process of learning policy. In this way, agent can learn optimal policies through less interactions with actual environment, and final experiments demonstrate the effectiveness of our model in control problem.