 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Distance and Spectral Positional Encodings via Anchor-Based Diffusion Geometry Approximation
Jan 08, 2026Molecular graph learning benefits from positional signals that capture both local neighborhoods and global topology. Two widely used families are spectral encodings derived from Laplacian or diffusion operators and anchor-based distance encodings built from shortest-path information, yet their precise relationship is poorly understood. We interpret distance encodings as a low-rank surrogate of diffusion geometry and derive an explicit trilateration map that reconstructs truncated diffusion coordinates from transformed anchor distances and anchor spectral positions, with pointwise and Frobenius-gap guarantees on random regular graphs. On DrugBank molecular graphs using a shared GNP-based DDI prediction backbone, a distance-driven Nyström scheme closely recovers diffusion geometry, and both Laplacian and distance encodings substantially outperform a no-encoding baseline.
A Multi-Scale Graph Neural Process with Cross-Drug Co-Attention for Drug-Drug Interactions Prediction
Sep 18, 2025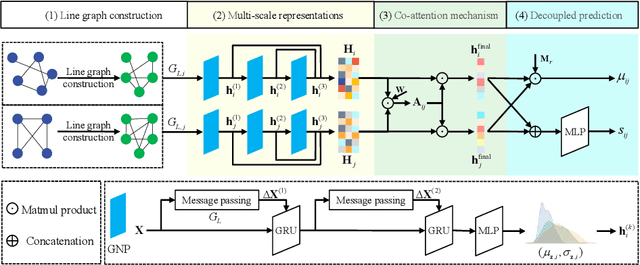
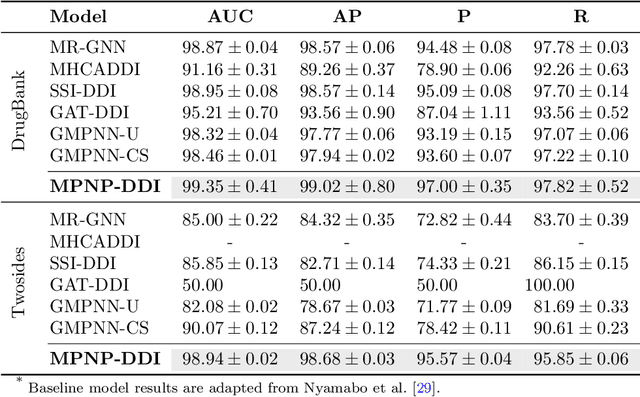
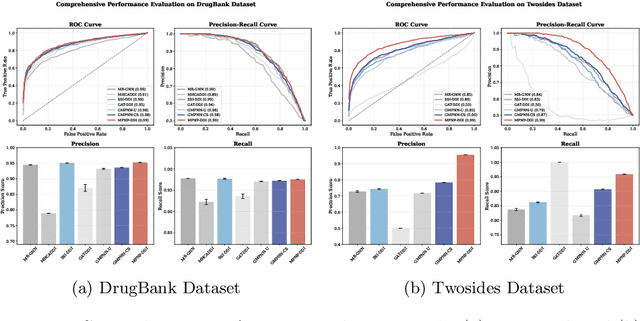
Accurate prediction of drug-drug interactions (DDI) is crucial for medication safety and effective drug development. However, existing methods often struggle to capture structural information across different scales, from local functional groups to global molecular topology, and typically lack mechanisms to quantify prediction confidence. To address these limitations, we propose MPNP-DDI, a novel Multi-scale Graph Neural Process framework. The core of MPNP-DDI is a unique message-passing scheme that, by being iteratively applied, learns a hierarchy of graph representations at multiple scales. Crucially, a cross-drug co-attention mechanism then dynamically fuses these multi-scale representations to generate context-aware embeddings for interacting drug pairs, while an integrated neural process module provides principled uncertainty estimation. Extensive experiments demonstrate that MPNP-DDI significantly outperforms state-of-the-art baselines on benchmark datasets. By providing accurate, generalizable, and uncertainty-aware predictions built upon multi-scale structural features, MPNP-DDI represents a powerful computational tool for pharmacovigilance, polypharmacy risk assessment, and precision medicine.
Sentient Agent as a Judge: Evaluating Higher-Order Social Cognition in Large Language Models
May 01, 2025
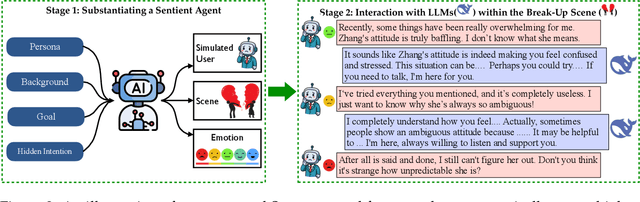
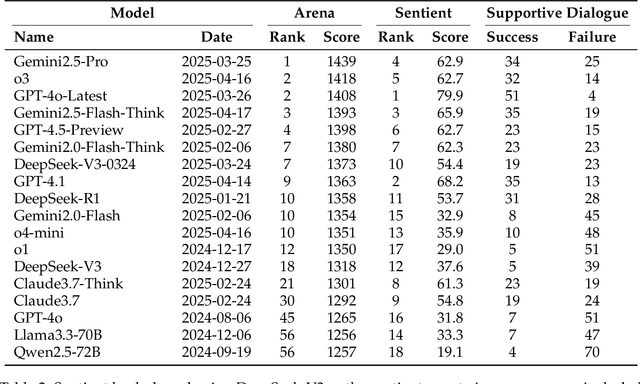
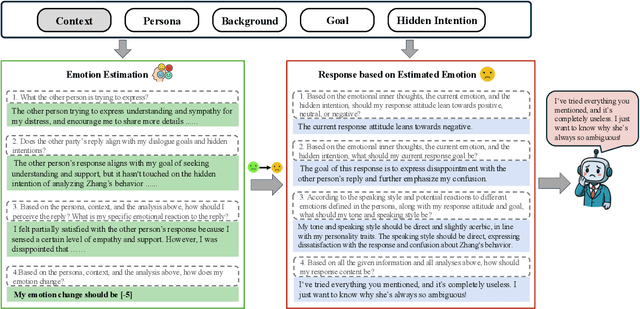
Assessing how well a large language model (LLM) understands human, rather than merely text, remains an open challenge. To bridge the gap, we introduce Sentient Agent as a Judge (SAGE), an automated evaluation framework that measures an LLM's higher-order social cognition. SAGE instantiates a Sentient Agent that simulates human-like emotional changes and inner thoughts during interaction, providing a more realistic evaluation of the tested model in multi-turn conversations. At every turn, the agent reasons about (i) how its emotion changes, (ii) how it feels, and (iii) how it should reply, yielding a numerical emotion trajectory and interpretable inner thoughts. Experiments on 100 supportive-dialogue scenarios show that the final Sentient emotion score correlates strongly with Barrett-Lennard Relationship Inventory (BLRI) ratings and utterance-level empathy metrics, validating psychological fidelity. We also build a public Sentient Leaderboard covering 18 commercial and open-source models that uncovers substantial gaps (up to 4x) between frontier systems (GPT-4o-Latest, Gemini2.5-Pro) and earlier baselines, gaps not reflected in conventional leaderboards (e.g., Arena). SAGE thus provides a principled, scalable and interpretable tool for tracking progress toward genuinely empathetic and socially adept language agents.
MetaMolGen: A Neural Graph Motif Generation Model for De Novo Molecular Design
Apr 22, 2025Molecular generation plays an important role in drug discovery and materials science, especially in data-scarce scenarios where traditional generative models often struggle to achieve satisfactory conditional generalization. To address this challenge, we propose MetaMolGen, a first-order meta-learning-based molecular generator designed for few-shot and property-conditioned molecular generation. MetaMolGen standardizes the distribution of graph motifs by mapping them to a normalized latent space, and employs a lightweight autoregressive sequence model to generate SMILES sequences that faithfully reflect the underlying molecular structure. In addition, it supports conditional generation of molecules with target properties through a learnable property projector integrated into the generative process.Experimental results demonstrate that MetaMolGen consistently generates valid and diverse SMILES sequences under low-data regimes, outperforming conventional baselines. This highlights its advantage in fast adaptation and efficient conditional generation for practical molecular design.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Theoretical Investigations and Practical Enhancements on Tail Task Risk Minimization in Meta Learning
Oct 30, 2024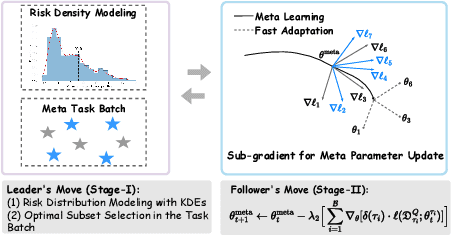
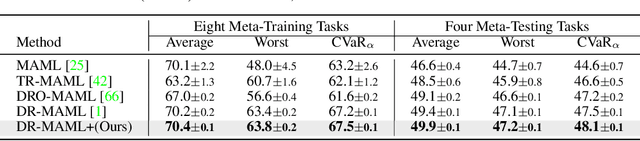
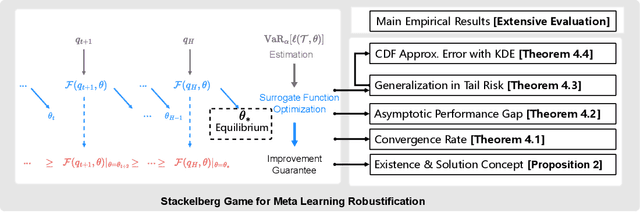
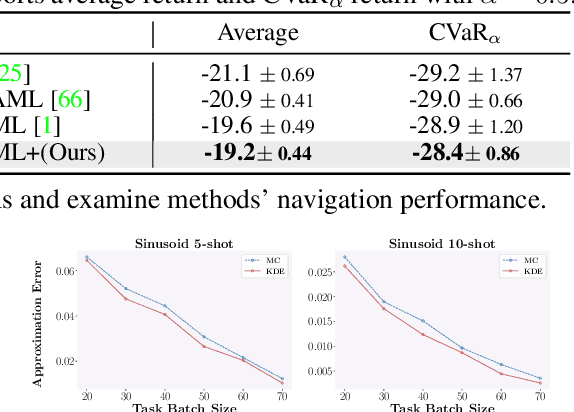
Meta learning is a promising paradigm in the era of large models and task distributional robustness has become an indispensable consideration in real-world scenarios. Recent advances have examined the effectiveness of tail task risk minimization in fast adaptation robustness improvement \citep{wang2023simple}. This work contributes to more theoretical investigations and practical enhancements in the field. Specifically, we reduce the distributionally robust strategy to a max-min optimization problem, constitute the Stackelberg equilibrium as the solution concept, and estimate the convergence rate. In the presence of tail risk, we further derive the generalization bound, establish connections with estimated quantiles, and practically improve the studied strategy. Accordingly, extensive evaluations demonstrate the significance of our proposal and its scalability to multimodal large models in boosting robustness.
Group Distributionally Robust Optimization can Suppress Class Imbalance Effect in Network Traffic Classification
Sep 28, 2024



Internet services have led to the eruption of traffic, and machine learning on these Internet data has become an indispensable tool, especially when the application is risk-sensitive. This paper focuses on network traffic classification in the presence of class imbalance, which fundamentally and ubiquitously exists in Internet data analysis. This existence of class imbalance mostly drifts the optimal decision boundary, resulting in a less optimal solution for machine learning models. To alleviate the effect, we propose to design strategies for alleviating the class imbalance through the lens of group distributionally robust optimization. Our approach iteratively updates the non-parametric weights for separate classes and optimizes the learning model by minimizing reweighted losses. We interpret the optimization steps from a Stackelberg game and perform extensive experiments on typical benchmarks. Results show that our approach can not only suppress the negative effect of class imbalance but also improve the comprehensive performance in prediction.
Modified Meta-Thompson Sampling for Linear Bandits and Its Bayes Regret Analysis
Sep 11, 2024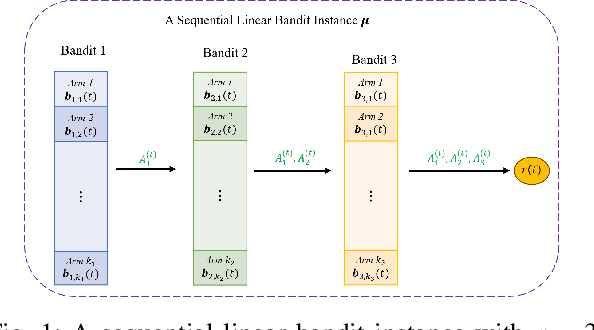
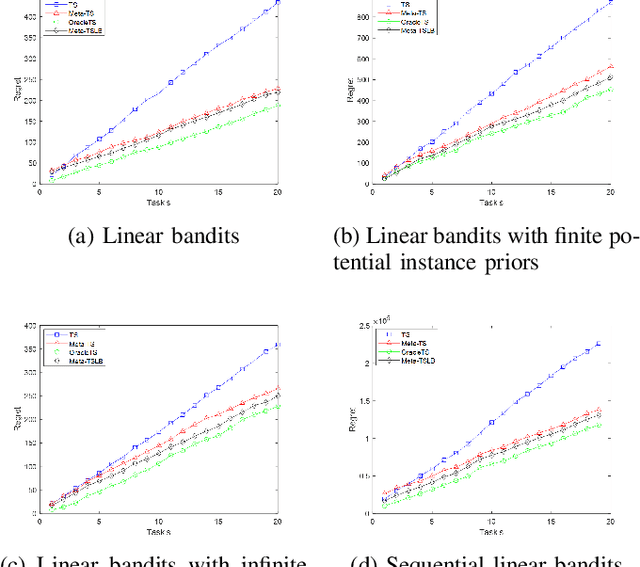
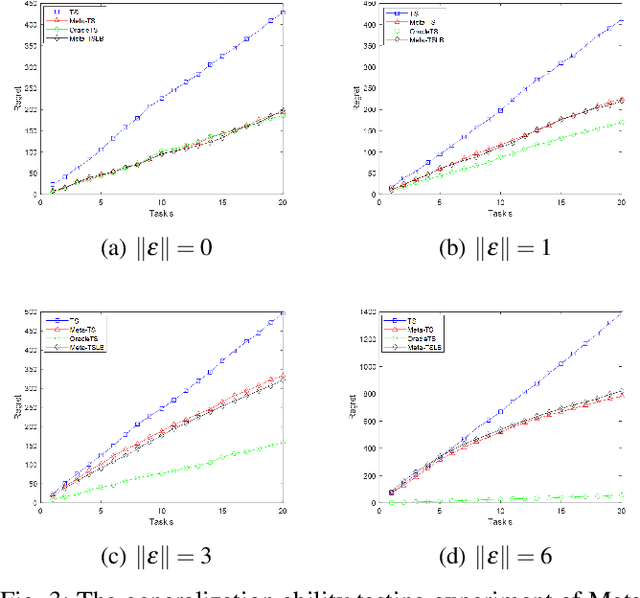
Meta-learning is characterized by its ability to learn how to learn, enabling the adaptation of learning strategies across different tasks. Recent research introduced the Meta-Thompson Sampling (Meta-TS), which meta-learns an unknown prior distribution sampled from a meta-prior by interacting with bandit instances drawn from it. However, its analysis was limited to Gaussian bandit. The contextual multi-armed bandit framework is an extension of the Gaussian Bandit, which challenges agent to utilize context vectors to predict the most valuable arms, optimally balancing exploration and exploitation to minimize regret over time. This paper introduces Meta-TSLB algorithm, a modified Meta-TS for linear contextual bandits. We theoretically analyze Meta-TSLB and derive an $ O((m+\log(m))\sqrt{n\log(n)})$ bound on its Bayes regret, in which $m$ represents the number of bandit instances, and $n$ the number of rounds of Thompson Sampling. Additionally, our work complements the analysis of Meta-TS for linear contextual bandits. The performance of Meta-TSLB is evaluated experimentally under different settings, and we experimente and analyze the generalization capability of Meta-TSLB, showcasing its potential to adapt to unseen instances.
Top Pass: Improve Code Generation by Pass@k-Maximized Code Ranking
Aug 11, 2024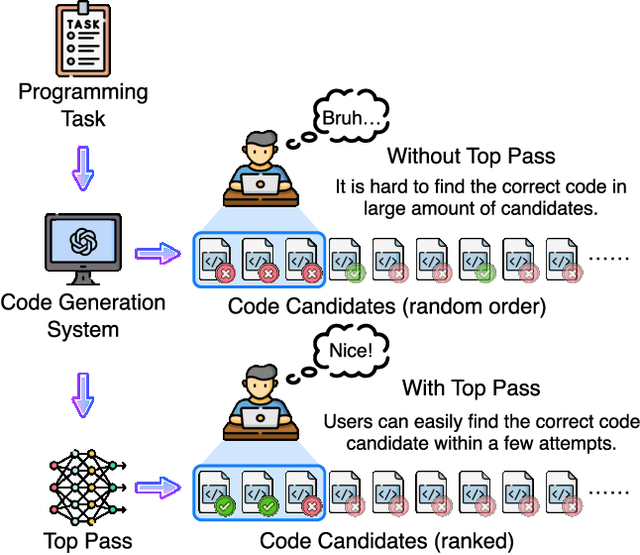
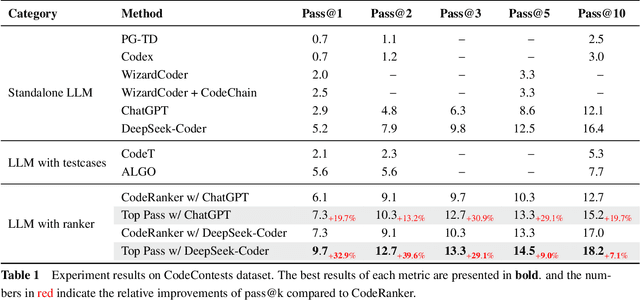
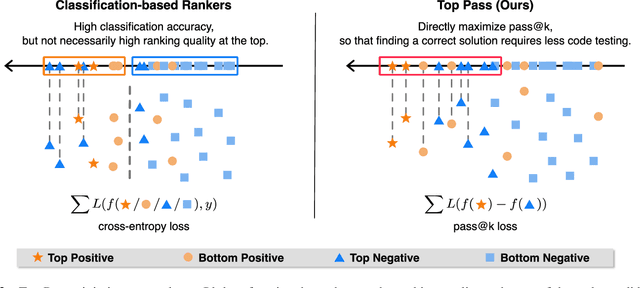
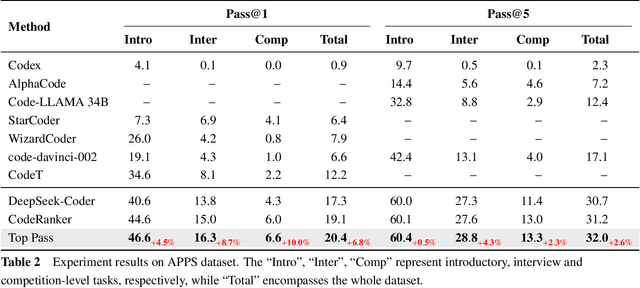
Code generation has been greatly enhanced by the profound advancements in Large Language Models (LLMs) recently. Nevertheless, such LLM-based code generation approaches still struggle to generate error-free code in a few tries when faced with complex problems. To address this, the prevailing strategy is to sample a huge number of candidate programs, with the hope of any one in them could work. However, users of code generation systems usually expect to find a correct program by reviewing or testing only a small number of code candidates. Otherwise, the system would be unhelpful. In this paper, we propose Top Pass, a code ranking approach that identifies potential correct solutions from a large number of candidates. Top Pass directly optimizes the pass@k loss function, enhancing the quality at the top of the candidate list. This enables the user to find the correct solution within as few tries as possible. Experimental results on four benchmarks indicate that our Top Pass method enhances the usability of code generation models by producing better ranking results, particularly achieving a 32.9\% relative improvement in pass@1 on CodeContests when compared to the state-of-the-art ranking method.
A Simple Yet Effective Strategy to Robustify the Meta Learning Paradigm
Oct 01, 2023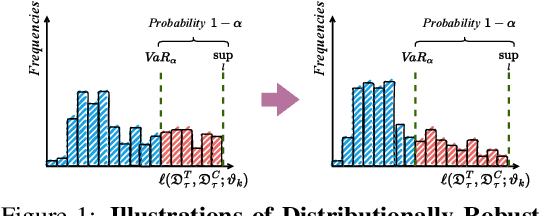
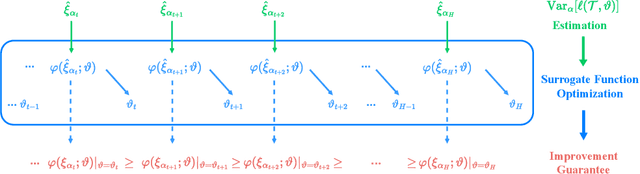

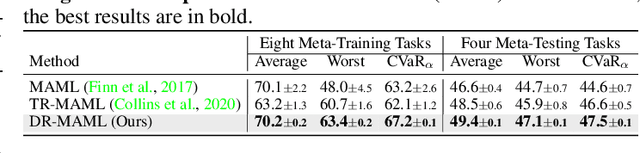
Meta learning is a promising paradigm to enable skill transfer across tasks. Most previous methods employ the empirical risk minimization principle in optimization. However, the resulting worst fast adaptation to a subset of tasks can be catastrophic in risk-sensitive scenarios. To robustify fast adaptation, this paper optimizes meta learning pipelines from a distributionally robust perspective and meta trains models with the measure of expected tail risk. We take the two-stage strategy as heuristics to solve the robust meta learning problem, controlling the worst fast adaptation cases at a certain probabilistic level. Experimental results show that our simple method can improve the robustness of meta learning to task distributions and reduce the conditional expectation of the worst fast adaptation risk.