 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop Pass: Improve Code Generation by Pass@k-Maximized Code Ranking
Aug 11, 2024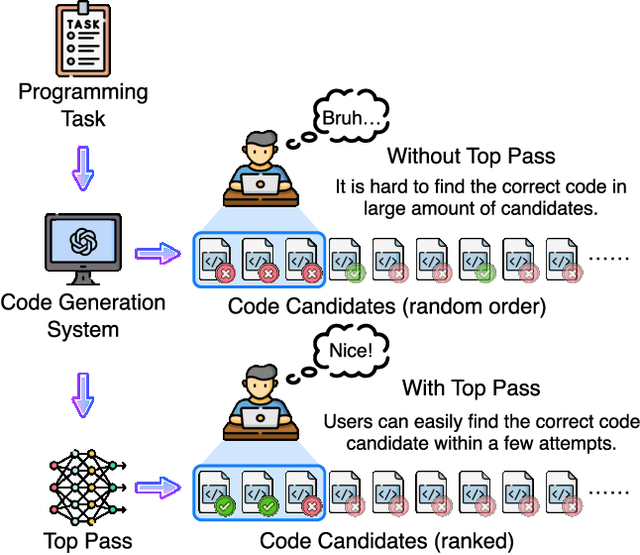
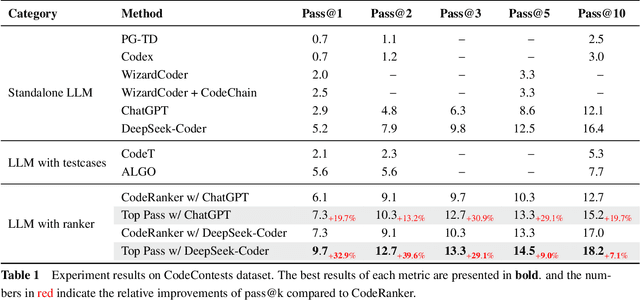
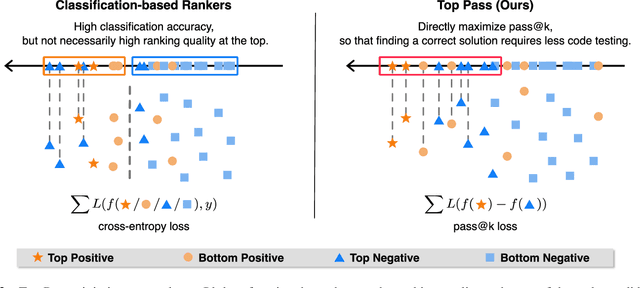
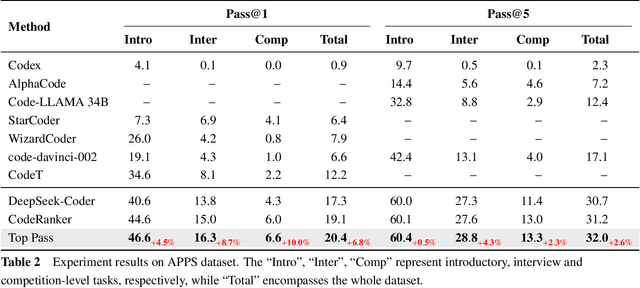
Code generation has been greatly enhanced by the profound advancements in Large Language Models (LLMs) recently. Nevertheless, such LLM-based code generation approaches still struggle to generate error-free code in a few tries when faced with complex problems. To address this, the prevailing strategy is to sample a huge number of candidate programs, with the hope of any one in them could work. However, users of code generation systems usually expect to find a correct program by reviewing or testing only a small number of code candidates. Otherwise, the system would be unhelpful. In this paper, we propose Top Pass, a code ranking approach that identifies potential correct solutions from a large number of candidates. Top Pass directly optimizes the pass@k loss function, enhancing the quality at the top of the candidate list. This enables the user to find the correct solution within as few tries as possible. Experimental results on four benchmarks indicate that our Top Pass method enhances the usability of code generation models by producing better ranking results, particularly achieving a 32.9\% relative improvement in pass@1 on CodeContests when compared to the state-of-the-art ranking method.
Think Outside the Code: Brainstorming Boosts Large Language Models in Code Generation
May 18, 2023Code generation aims to automatically generate source code from high-level task specifications, which can significantly increase productivity of software engineering. Recently, approaches based on large language models (LLMs) have shown remarkable code generation abilities on simple tasks. However, generate code for more complex tasks, such as competition-level problems, remains challenging. In this paper, we introduce Brainstorm framework for code generation. It leverages a brainstorming step that generates and selects diverse thoughts on the problem to facilitate algorithmic reasoning, where the thoughts are possible blueprint of solving the problem. We demonstrate that Brainstorm significantly enhances the ability of LLMs to solve competition-level programming problems, resulting in a more than 50% increase in the pass@$k$ metrics for ChatGPT on the CodeContests benchmark, achieving state-of-the-art performance. Furthermore, our experiments conducted on LeetCode contests show that our framework boosts the ability of ChatGPT to a level comparable to that of human programmers.