 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTR-PPO: Proximal Policy Optimization with Prioritized Trajectory Replay
Paper and Code
Dec 08, 2021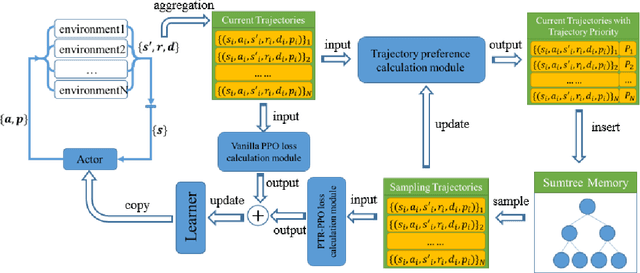
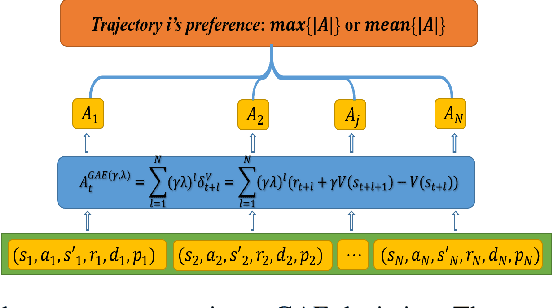

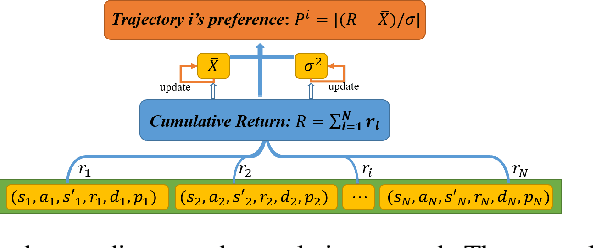
On-policy deep reinforcement learning algorithms have low data utilization and require significant experience for policy improvement. This paper proposes a proximal policy optimization algorithm with prioritized trajectory replay (PTR-PPO) that combines on-policy and off-policy methods to improve sampling efficiency by prioritizing the replay of trajectories generated by old policies. We first design three trajectory priorities based on the characteristics of trajectories: the first two being max and mean trajectory priorities based on one-step empirical generalized advantage estimation (GAE) values and the last being reward trajectory priorities based on normalized undiscounted cumulative reward. Then, we incorporate the prioritized trajectory replay into the PPO algorithm, propose a truncated importance weight method to overcome the high variance caused by large importance weights under multistep experience, and design a policy improvement loss function for PPO under off-policy conditions. We evaluate the performance of PTR-PPO in a set of Atari discrete control tasks, achieving state-of-the-art performance. In addition, by analyzing the heatmap of priority changes at various locations in the priority memory during training, we find that memory size and rollout length can have a significant impact on the distribution of trajectory priorities and, hence, on the performance of the algorithm.