 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSD-CAP: Fractional Subgraph Diffusion with Class-Aware Propagation for Graph Feature Imputation
Jan 26, 2026Imputing missing node features in graphs is challenging, particularly under high missing rates. Existing methods based on latent representations or global diffusion often fail to produce reliable estimates, and may propagate errors across the graph. We propose FSD-CAP, a two-stage framework designed to improve imputation quality under extreme sparsity. In the first stage, a graph-distance-guided subgraph expansion localizes the diffusion process. A fractional diffusion operator adjusts propagation sharpness based on local structure. In the second stage, imputed features are refined using class-aware propagation, which incorporates pseudo-labels and neighborhood entropy to promote consistency. We evaluated FSD-CAP on multiple datasets. With $99.5\%$ of features missing across five benchmark datasets, FSD-CAP achieves average accuracies of $80.06\%$ (structural) and $81.01\%$ (uniform) in node classification, close to the $81.31\%$ achieved by a standard GCN with full features. For link prediction under the same setting, it reaches AUC scores of $91.65\%$ (structural) and $92.41\%$ (uniform), compared to $95.06\%$ for the fully observed case. Furthermore, FSD-CAP demonstrates superior performance on both large-scale and heterophily datasets when compared to other models.
Draw it like Euclid: Teaching transformer models to generate CAD profiles using ruler and compass construction steps
Jan 14, 2026We introduce a new method of generating Computer Aided Design (CAD) profiles via a sequence of simple geometric constructions including curve offsetting, rotations and intersections. These sequences start with geometry provided by a designer and build up the points and curves of the final profile step by step. We demonstrate that adding construction steps between the designer's input geometry and the final profile improves generation quality in a similar way to the introduction of a chain of thought in language models. Similar to the constraints in a parametric CAD model, the construction sequences reduce the degrees of freedom in the modeled shape to a small set of parameter values which can be adjusted by the designer, allowing parametric editing with the constructed geometry evaluated to floating point precision. In addition we show that applying reinforcement learning to the construction sequences gives further improvements over a wide range of metrics, including some which were not explicitly optimized.
TrojanTO: Action-Level Backdoor Attacks against Trajectory Optimization Models
Jun 15, 2025Recent advances in Trajectory Optimization (TO) models have achieved remarkable success in offline reinforcement learning. However, their vulnerabilities against backdoor attacks are poorly understood. We find that existing backdoor attacks in reinforcement learning are based on reward manipulation, which are largely ineffective against the TO model due to its inherent sequence modeling nature. Moreover, the complexities introduced by high-dimensional action spaces further compound the challenge of action manipulation. To address these gaps, we propose TrojanTO, the first action-level backdoor attack against TO models. TrojanTO employs alternating training to enhance the connection between triggers and target actions for attack effectiveness. To improve attack stealth, it utilizes precise poisoning via trajectory filtering for normal performance and batch poisoning for trigger consistency. Extensive evaluations demonstrate that TrojanTO effectively implants backdoor attacks across diverse tasks and attack objectives with a low attack budget (0.3\% of trajectories). Furthermore, TrojanTO exhibits broad applicability to DT, GDT, and DC, underscoring its scalability across diverse TO model architectures.
Is Mamba Compatible with Trajectory Optimization in Offline Reinforcement Learning?
May 20, 2024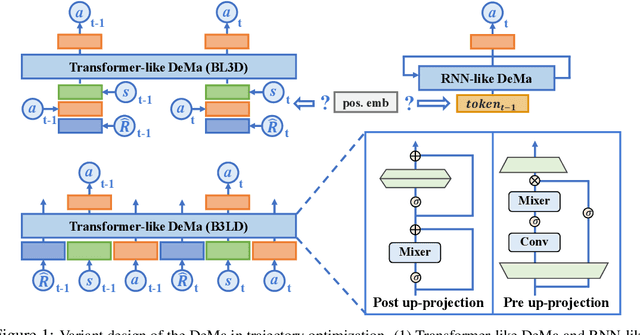
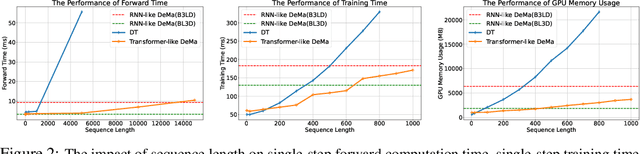
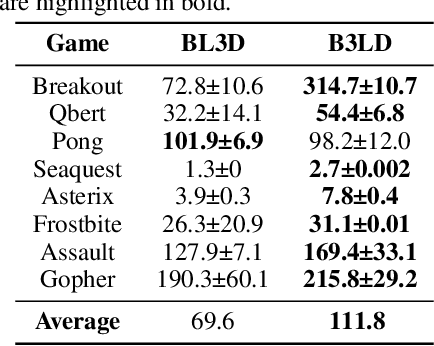
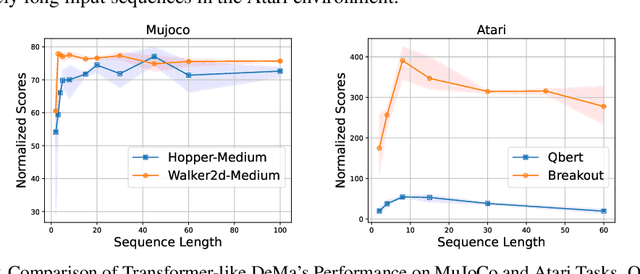
Transformer-based trajectory optimization methods have demonstrated exceptional performance in offline Reinforcement Learning (offline RL), yet it poses challenges due to substantial parameter size and limited scalability, which is particularly critical in sequential decision-making scenarios where resources are constrained such as in robots and drones with limited computational power. Mamba, a promising new linear-time sequence model, offers performance on par with transformers while delivering substantially fewer parameters on long sequences. As it remains unclear whether Mamba is compatible with trajectory optimization, this work aims to conduct comprehensive experiments to explore the potential of Decision Mamba in offline RL (dubbed DeMa) from the aspect of data structures and network architectures with the following insights: (1) Long sequences impose a significant computational burden without contributing to performance improvements due to the fact that DeMa's focus on sequences diminishes approximately exponentially. Consequently, we introduce a Transformer-like DeMa as opposed to an RNN-like DeMa. (2) For the components of DeMa, we identify that the hidden attention mechanism is key to its success, which can also work well with other residual structures and does not require position embedding. Extensive evaluations from eight Atari games demonstrate that our specially designed DeMa is compatible with trajectory optimization and surpasses previous state-of-the-art methods, outdoing Decision Transformer (DT) by 80\% with 30\% fewer parameters, and exceeds DT in MuJoCo with only a quarter of the parameters.
Reconstructing editable prismatic CAD from rounded voxel models
Sep 02, 2022
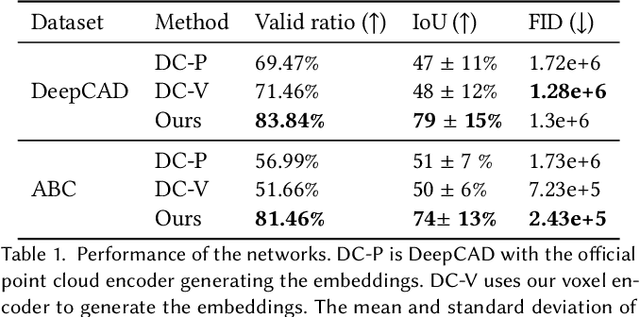
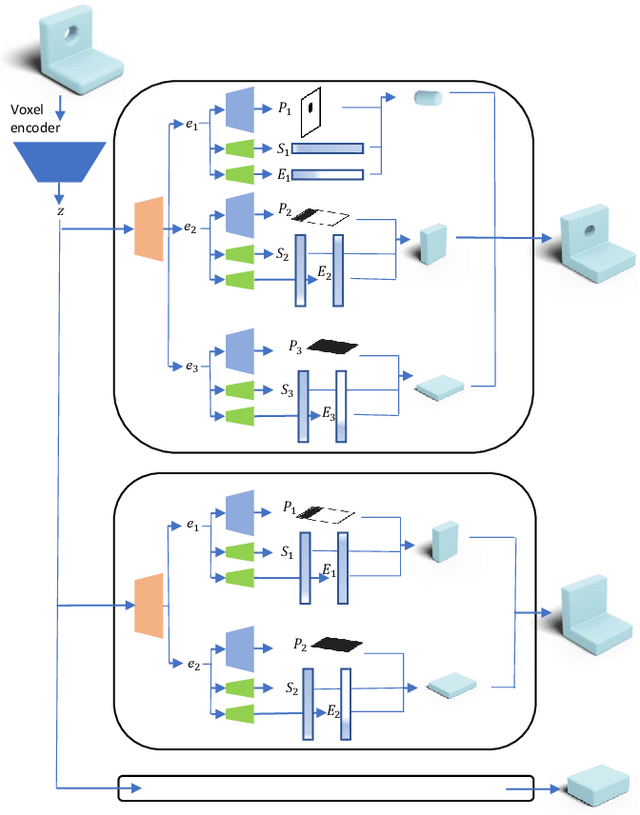
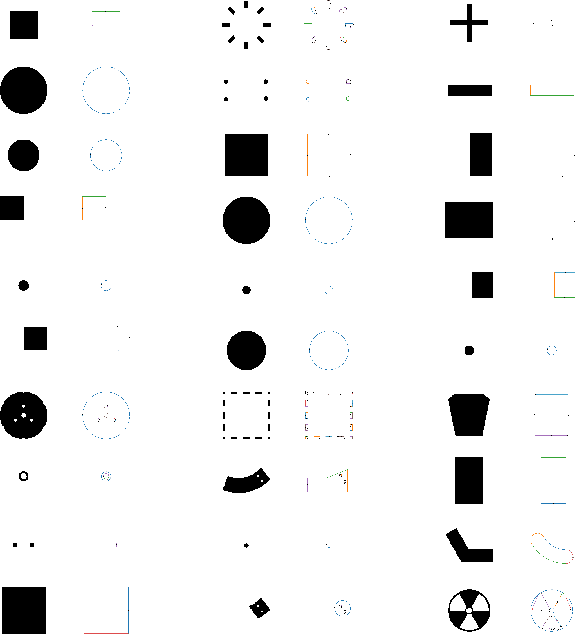
Reverse Engineering a CAD shape from other representations is an important geometric processing step for many downstream applications. In this work, we introduce a novel neural network architecture to solve this challenging task and approximate a smoothed signed distance function with an editable, constrained, prismatic CAD model. During training, our method reconstructs the input geometry in the voxel space by decomposing the shape into a series of 2D profile images and 1D envelope functions. These can then be recombined in a differentiable way allowing a geometric loss function to be defined. During inference, we obtain the CAD data by first searching a database of 2D constrained sketches to find curves which approximate the profile images, then extrude them and use Boolean operations to build the final CAD model. Our method approximates the target shape more closely than other methods and outputs highly editable constrained parametric sketches which are compatible with existing CAD software.
TiKick: Towards Playing Multi-agent Football Full Games from Single-agent Demonstrations
Oct 19, 2021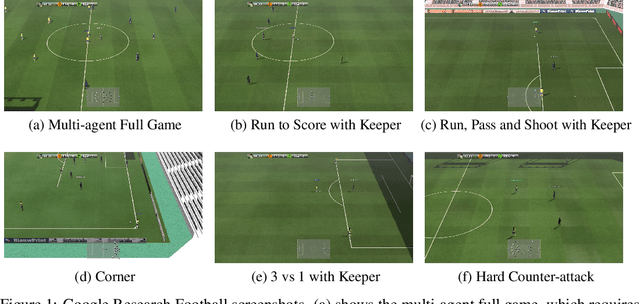

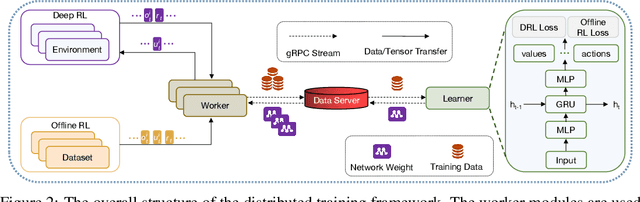
Deep reinforcement learning (DRL) has achieved super-human performance on complex video games (e.g., StarCraft II and Dota II). However, current DRL systems still suffer from challenges of multi-agent coordination, sparse rewards, stochastic environments, etc. In seeking to address these challenges, we employ a football video game, e.g., Google Research Football (GRF), as our testbed and develop an end-to-end learning-based AI system (denoted as TiKick) to complete this challenging task. In this work, we first generated a large replay dataset from the self-playing of single-agent experts, which are obtained from league training. We then developed a distributed learning system and new offline algorithms to learn a powerful multi-agent AI from the fixed single-agent dataset. To the best of our knowledge, Tikick is the first learning-based AI system that can take over the multi-agent Google Research Football full game, while previous work could either control a single agent or experiment on toy academic scenarios. Extensive experiments further show that our pre-trained model can accelerate the training process of the modern multi-agent algorithm and our method achieves state-of-the-art performances on various academic scenarios.