 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffLocks: Generating 3D Hair from a Single Image using Diffusion Models
May 09, 2025



We address the task of generating 3D hair geometry from a single image, which is challenging due to the diversity of hairstyles and the lack of paired image-to-3D hair data. Previous methods are primarily trained on synthetic data and cope with the limited amount of such data by using low-dimensional intermediate representations, such as guide strands and scalp-level embeddings, that require post-processing to decode, upsample, and add realism. These approaches fail to reconstruct detailed hair, struggle with curly hair, or are limited to handling only a few hairstyles. To overcome these limitations, we propose DiffLocks, a novel framework that enables detailed reconstruction of a wide variety of hairstyles directly from a single image. First, we address the lack of 3D hair data by automating the creation of the largest synthetic hair dataset to date, containing 40K hairstyles. Second, we leverage the synthetic hair dataset to learn an image-conditioned diffusion-transfomer model that generates accurate 3D strands from a single frontal image. By using a pretrained image backbone, our method generalizes to in-the-wild images despite being trained only on synthetic data. Our diffusion model predicts a scalp texture map in which any point in the map contains the latent code for an individual hair strand. These codes are directly decoded to 3D strands without post-processing techniques. Representing individual strands, instead of guide strands, enables the transformer to model the detailed spatial structure of complex hairstyles. With this, DiffLocks can recover highly curled hair, like afro hairstyles, from a single image for the first time. Data and code is available at https://radualexandru.github.io/difflocks/
Rethinking the Generation of High-Quality CoT Data from the Perspective of LLM-Adaptive Question Difficulty Grading
Apr 16, 2025



Recently, DeepSeek-R1 (671B) (DeepSeek-AIet al., 2025) has demonstrated its excellent reasoning ability in complex tasks and has publiclyshared its methodology. This provides potentially high-quality chain-of-thought (CoT) data for stimulating the reasoning abilities of small-sized large language models (LLMs). To generate high-quality CoT data for different LLMs, we seek an efficient method for generating high-quality CoT data with LLM-Adaptive questiondifficulty levels. First, we grade the difficulty of the questions according to the reasoning ability of the LLMs themselves and construct a LLM-Adaptive question database. Second, we sample the problem database based on a distribution of difficulty levels of the questions and then use DeepSeek-R1 (671B) (DeepSeek-AI et al., 2025) to generate the corresponding high-quality CoT data with correct answers. Thanks to the construction of CoT data with LLM-Adaptive difficulty levels, we have significantly reduced the cost of data generation and enhanced the efficiency of model supervised fine-tuning (SFT). Finally, we have validated the effectiveness and generalizability of the proposed method in the fields of complex mathematical competitions and code generation tasks. Notably, with only 2k high-quality mathematical CoT data, our ZMath-32B surpasses DeepSeek-Distill-32B in math reasoning task. Similarly, with only 2k high-quality code CoT data, our ZCode-32B surpasses DeepSeek-Distill-32B in code reasoning tasks.
Graph-attention-based Casual Discovery with Trust Region-navigated Clipping Policy Optimization
Dec 27, 2024
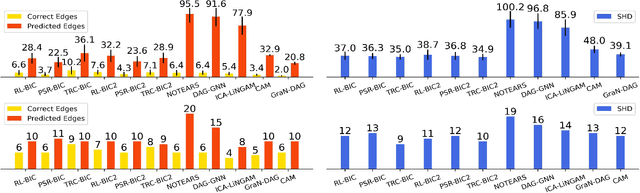
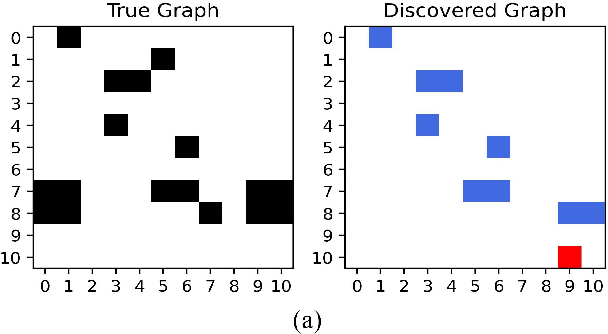
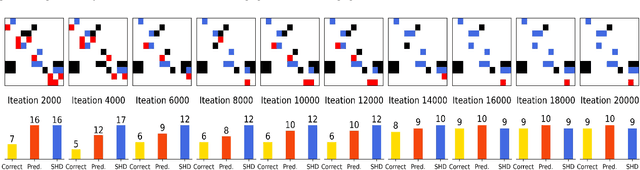
In many domains of empirical sciences, discovering the causal structure within variables remains an indispensable task. Recently, to tackle with unoriented edges or latent assumptions violation suffered by conventional methods, researchers formulated a reinforcement learning (RL) procedure for causal discovery, and equipped REINFORCE algorithm to search for the best-rewarded directed acyclic graph. The two keys to the overall performance of the procedure are the robustness of RL methods and the efficient encoding of variables. However, on the one hand, REINFORCE is prone to local convergence and unstable performance during training. Neither trust region policy optimization, being computationally-expensive, nor proximal policy optimization (PPO), suffering from aggregate constraint deviation, is decent alternative for combinatory optimization problems with considerable individual subactions. We propose a trust region-navigated clipping policy optimization method for causal discovery that guarantees both better search efficiency and steadiness in policy optimization, in comparison with REINFORCE, PPO and our prioritized sampling-guided REINFORCE implementation. On the other hand, to boost the efficient encoding of variables, we propose a refined graph attention encoder called SDGAT that can grasp more feature information without priori neighbourhood information. With these improvements, the proposed method outperforms former RL method in both synthetic and benchmark datasets in terms of output results and optimization robustness.
MonoHair: High-Fidelity Hair Modeling from a Monocular Video
Mar 27, 2024



Undoubtedly, high-fidelity 3D hair is crucial for achieving realism, artistic expression, and immersion in computer graphics. While existing 3D hair modeling methods have achieved impressive performance, the challenge of achieving high-quality hair reconstruction persists: they either require strict capture conditions, making practical applications difficult, or heavily rely on learned prior data, obscuring fine-grained details in images. To address these challenges, we propose MonoHair,a generic framework to achieve high-fidelity hair reconstruction from a monocular video, without specific requirements for environments. Our approach bifurcates the hair modeling process into two main stages: precise exterior reconstruction and interior structure inference. The exterior is meticulously crafted using our Patch-based Multi-View Optimization (PMVO). This method strategically collects and integrates hair information from multiple views, independent of prior data, to produce a high-fidelity exterior 3D line map. This map not only captures intricate details but also facilitates the inference of the hair's inner structure. For the interior, we employ a data-driven, multi-view 3D hair reconstruction method. This method utilizes 2D structural renderings derived from the reconstructed exterior, mirroring the synthetic 2D inputs used during training. This alignment effectively bridges the domain gap between our training data and real-world data, thereby enhancing the accuracy and reliability of our interior structure inference. Lastly, we generate a strand model and resolve the directional ambiguity by our hair growth algorithm. Our experiments demonstrate that our method exhibits robustness across diverse hairstyles and achieves state-of-the-art performance. For more results, please refer to our project page https://keyuwu-cs.github.io/MonoHair/.
Self-evolving Autoencoder Embedded Q-Network
Feb 18, 2024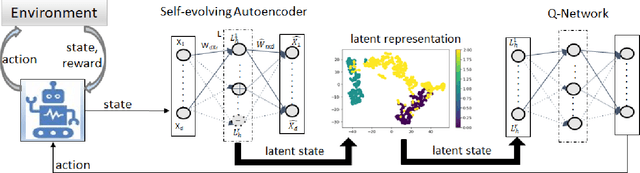

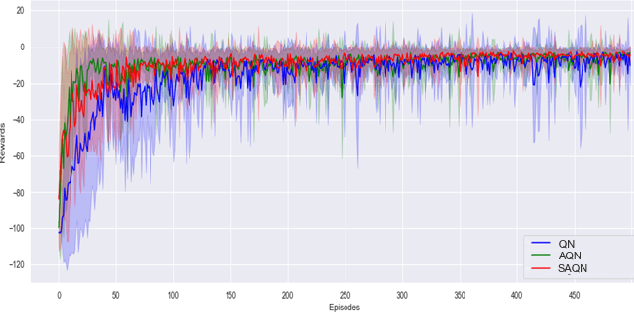
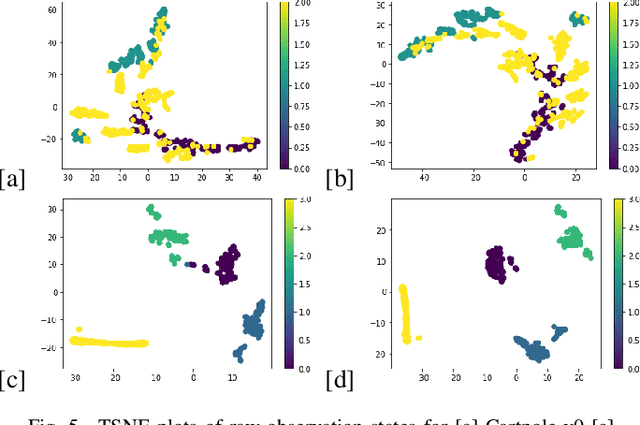
In the realm of sequential decision-making tasks, the exploration capability of a reinforcement learning (RL) agent is paramount for achieving high rewards through interactions with the environment. To enhance this crucial ability, we propose SAQN, a novel approach wherein a self-evolving autoencoder (SA) is embedded with a Q-Network (QN). In SAQN, the self-evolving autoencoder architecture adapts and evolves as the agent explores the environment. This evolution enables the autoencoder to capture a diverse range of raw observations and represent them effectively in its latent space. By leveraging the disentangled states extracted from the encoder generated latent space, the QN is trained to determine optimal actions that improve rewards. During the evolution of the autoencoder architecture, a bias-variance regulatory strategy is employed to elicit the optimal response from the RL agent. This strategy involves two key components: (i) fostering the growth of nodes to retain previously acquired knowledge, ensuring a rich representation of the environment, and (ii) pruning the least contributing nodes to maintain a more manageable and tractable latent space. Extensive experimental evaluations conducted on three distinct benchmark environments and a real-world molecular environment demonstrate that the proposed SAQN significantly outperforms state-of-the-art counterparts. The results highlight the effectiveness of the self-evolving autoencoder and its collaboration with the Q-Network in tackling sequential decision-making tasks.
UAV 3-D path planning based on MOEA/D with adaptive areal weight adjustment
Aug 20, 2023Unmanned aerial vehicles (UAVs) are desirable platforms for time-efficient and cost-effective task execution. 3-D path planning is a key challenge for task decision-making. This paper proposes an improved multi-objective evolutionary algorithm based on decomposition (MOEA/D) with an adaptive areal weight adjustment (AAWA) strategy to make a tradeoff between the total flight path length and the terrain threat. AAWA is designed to improve the diversity of the solutions. More specifically, AAWA first removes a crowded individual and its weight vector from the current population and then adds a sparse individual from the external elite population to the current population. To enable the newly-added individual to evolve towards the sparser area of the population in the objective space, its weight vector is constructed by the objective function value of its neighbors. The effectiveness of MOEA/D-AAWA is validated in twenty synthetic scenarios with different number of obstacles and four realistic scenarios in comparison with other three classical methods.
NeuralHDHair: Automatic High-fidelity Hair Modeling from a Single Image Using Implicit Neural Representations
May 09, 2022

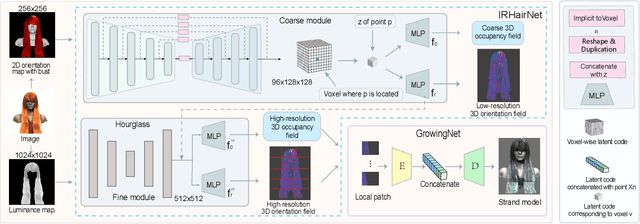

Undoubtedly, high-fidelity 3D hair plays an indispensable role in digital humans. However, existing monocular hair modeling methods are either tricky to deploy in digital systems (e.g., due to their dependence on complex user interactions or large databases) or can produce only a coarse geometry. In this paper, we introduce NeuralHDHair, a flexible, fully automatic system for modeling high-fidelity hair from a single image. The key enablers of our system are two carefully designed neural networks: an IRHairNet (Implicit representation for hair using neural network) for inferring high-fidelity 3D hair geometric features (3D orientation field and 3D occupancy field) hierarchically and a GrowingNet(Growing hair strands using neural network) to efficiently generate 3D hair strands in parallel. Specifically, we perform a coarse-to-fine manner and propose a novel voxel-aligned implicit function (VIFu) to represent the global hair feature, which is further enhanced by the local details extracted from a hair luminance map. To improve the efficiency of a traditional hair growth algorithm, we adopt a local neural implicit function to grow strands based on the estimated 3D hair geometric features. Extensive experiments show that our method is capable of constructing a high-fidelity 3D hair model from a single image, both efficiently and effectively, and achieves the-state-of-the-art performance.
Learning Temporal Consistency for Source-Free Video Domain Adaptation
Mar 09, 2022
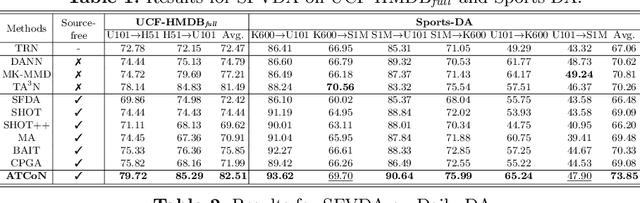
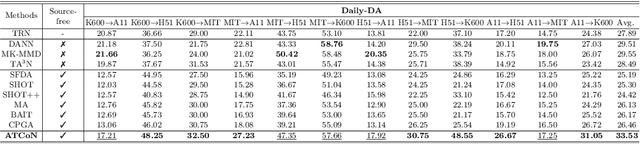

Video-based Unsupervised Domain Adaptation (VUDA) methods improve the robustness of video models, enabling them to be applied to action recognition tasks across different environments. However, these methods require constant access to source data during the adaptation process. Yet in many real-world applications, subjects and scenes in the source video domain should be irrelevant to those in the target video domain. With the increasing emphasis on data privacy, such methods that require source data access would raise serious privacy issues. Therefore, to cope with such concern, a more practical domain adaptation scenario is formulated as the Source-Free Video-based Domain Adaptation (SFVDA). Though there are a few methods for Source-Free Domain Adaptation (SFDA) on image data, these methods yield degenerating performance in SFVDA due to the multi-modality nature of videos, with the existence of additional temporal features. In this paper, we propose a novel Attentive Temporal Consistent Network (ATCoN) to address SFVDA by learning temporal consistency, guaranteed by two novel consistency objectives, namely feature consistency and source prediction consistency, performed across local temporal features. ATCoN further constructs effective overall temporal features by attending to local temporal features based on prediction confidence. Empirical results demonstrate the state-of-the-art performance of ATCoN across various cross-domain action recognition benchmarks.
Multi-Source Video Domain Adaptation with Temporal Attentive Moment Alignment
Sep 26, 2021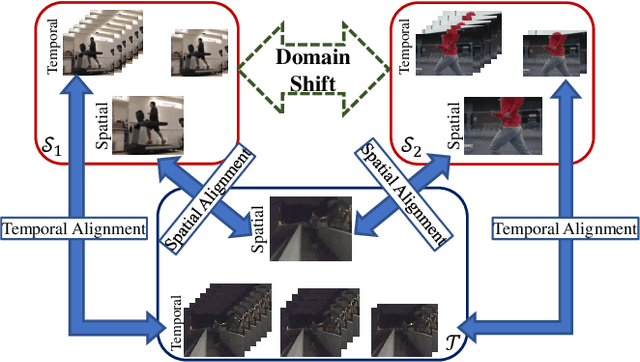
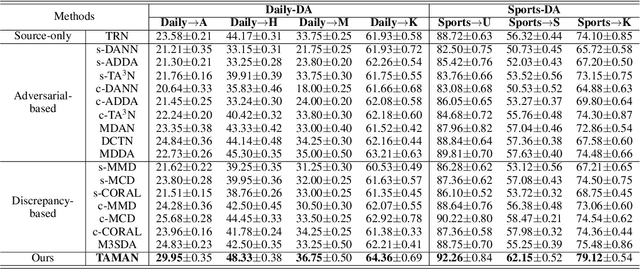
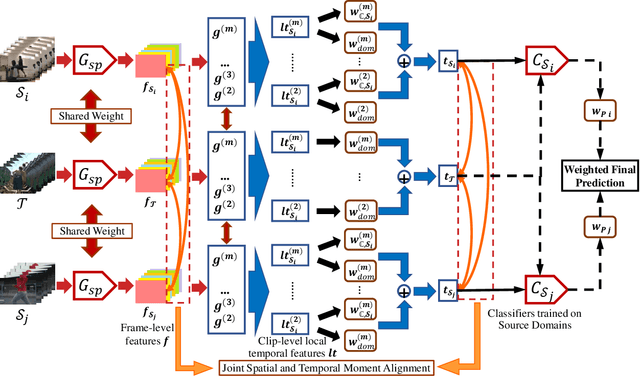

Multi-Source Domain Adaptation (MSDA) is a more practical domain adaptation scenario in real-world scenarios. It relaxes the assumption in conventional Unsupervised Domain Adaptation (UDA) that source data are sampled from a single domain and match a uniform data distribution. MSDA is more difficult due to the existence of different domain shifts between distinct domain pairs. When considering videos, the negative transfer would be provoked by spatial-temporal features and can be formulated into a more challenging Multi-Source Video Domain Adaptation (MSVDA) problem. In this paper, we address the MSVDA problem by proposing a novel Temporal Attentive Moment Alignment Network (TAMAN) which aims for effective feature transfer by dynamically aligning both spatial and temporal feature moments. TAMAN further constructs robust global temporal features by attending to dominant domain-invariant local temporal features with high local classification confidence and low disparity between global and local feature discrepancies. To facilitate future research on the MSVDA problem, we introduce comprehensive benchmarks, covering extensive MSVDA scenarios. Empirical results demonstrate a superior performance of the proposed TAMAN across multiple MSVDA benchmarks.