 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoHair: High-Fidelity Hair Modeling from a Monocular Video
Mar 27, 2024



Undoubtedly, high-fidelity 3D hair is crucial for achieving realism, artistic expression, and immersion in computer graphics. While existing 3D hair modeling methods have achieved impressive performance, the challenge of achieving high-quality hair reconstruction persists: they either require strict capture conditions, making practical applications difficult, or heavily rely on learned prior data, obscuring fine-grained details in images. To address these challenges, we propose MonoHair,a generic framework to achieve high-fidelity hair reconstruction from a monocular video, without specific requirements for environments. Our approach bifurcates the hair modeling process into two main stages: precise exterior reconstruction and interior structure inference. The exterior is meticulously crafted using our Patch-based Multi-View Optimization (PMVO). This method strategically collects and integrates hair information from multiple views, independent of prior data, to produce a high-fidelity exterior 3D line map. This map not only captures intricate details but also facilitates the inference of the hair's inner structure. For the interior, we employ a data-driven, multi-view 3D hair reconstruction method. This method utilizes 2D structural renderings derived from the reconstructed exterior, mirroring the synthetic 2D inputs used during training. This alignment effectively bridges the domain gap between our training data and real-world data, thereby enhancing the accuracy and reliability of our interior structure inference. Lastly, we generate a strand model and resolve the directional ambiguity by our hair growth algorithm. Our experiments demonstrate that our method exhibits robustness across diverse hairstyles and achieves state-of-the-art performance. For more results, please refer to our project page https://keyuwu-cs.github.io/MonoHair/.
AniDress: Animatable Loose-Dressed Avatar from Sparse Views Using Garment Rigging Model
Jan 27, 2024Recent communities have seen significant progress in building photo-realistic animatable avatars from sparse multi-view videos. However, current workflows struggle to render realistic garment dynamics for loose-fitting characters as they predominantly rely on naked body models for human modeling while leaving the garment part un-modeled. This is mainly due to that the deformations yielded by loose garments are highly non-rigid, and capturing such deformations often requires dense views as supervision. In this paper, we introduce AniDress, a novel method for generating animatable human avatars in loose clothes using very sparse multi-view videos (4-8 in our setting). To allow the capturing and appearance learning of loose garments in such a situation, we employ a virtual bone-based garment rigging model obtained from physics-based simulation data. Such a model allows us to capture and render complex garment dynamics through a set of low-dimensional bone transformations. Technically, we develop a novel method for estimating temporal coherent garment dynamics from a sparse multi-view video. To build a realistic rendering for unseen garment status using coarse estimations, a pose-driven deformable neural radiance field conditioned on both body and garment motions is introduced, providing explicit control of both parts. At test time, the new garment poses can be captured from unseen situations, derived from a physics-based or neural network-based simulator to drive unseen garment dynamics. To evaluate our approach, we create a multi-view dataset that captures loose-dressed performers with diverse motions. Experiments show that our method is able to render natural garment dynamics that deviate highly from the body and generalize well to both unseen views and poses, surpassing the performance of existing methods. The code and data will be publicly available.
Domain Adaptation on Point Clouds via Geometry-Aware Implicits
Dec 17, 2021

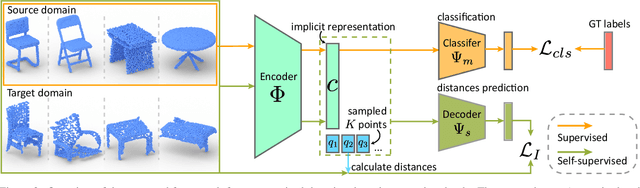

As a popular geometric representation, point clouds have attracted much attention in 3D vision, leading to many applications in autonomous driving and robotics. One important yet unsolved issue for learning on point cloud is that point clouds of the same object can have significant geometric variations if generated using different procedures or captured using different sensors. These inconsistencies induce domain gaps such that neural networks trained on one domain may fail to generalize on others. A typical technique to reduce the domain gap is to perform adversarial training so that point clouds in the feature space can align. However, adversarial training is easy to fall into degenerated local minima, resulting in negative adaptation gains. Here we propose a simple yet effective method for unsupervised domain adaptation on point clouds by employing a self-supervised task of learning geometry-aware implicits, which plays two critical roles in one shot. First, the geometric information in the point clouds is preserved through the implicit representations for downstream tasks. More importantly, the domain-specific variations can be effectively learned away in the implicit space. We also propose an adaptive strategy to compute unsigned distance fields for arbitrary point clouds due to the lack of shape models in practice. When combined with a task loss, the proposed outperforms state-of-the-art unsupervised domain adaptation methods that rely on adversarial domain alignment and more complicated self-supervised tasks. Our method is evaluated on both PointDA-10 and GraspNet datasets. The code and trained models will be publicly available.
DCL: Differential Contrastive Learning for Geometry-Aware Depth Synthesis
Jul 27, 2021

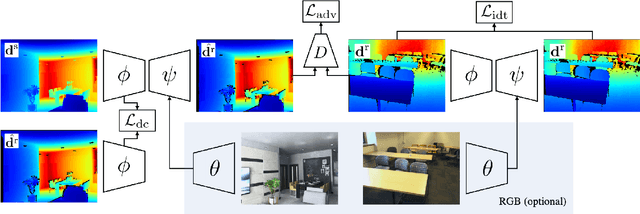

We describe a method for realistic depth synthesis that learns diverse variations from the real depth scans and ensures geometric consistency for effective synthetic-to-real transfer. Unlike general image synthesis pipelines, where geometries are mostly ignored, we treat geometries carried by the depth based on their own existence. We propose differential contrastive learning that explicitly enforces the underlying geometric properties to be invariant regarding the real variations been learned. The resulting depth synthesis method is task-agnostic and can be used for training any task-specific networks with synthetic labels. We demonstrate the effectiveness of the proposed method by extensive evaluations on downstream real-world geometric reasoning tasks. We show our method achieves better synthetic-to-real transfer performance than the other state-of-the-art. When fine-tuned on a small number of real-world annotations, our method can even surpass the fully supervised baselines.