 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-evolving Autoencoder Embedded Q-Network
Paper and Code
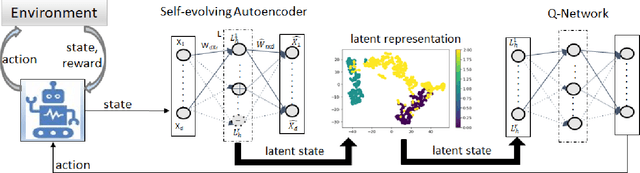

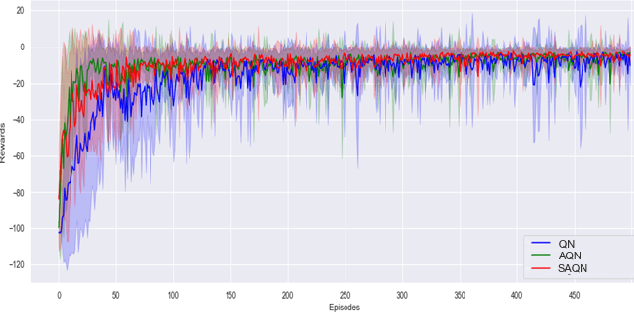
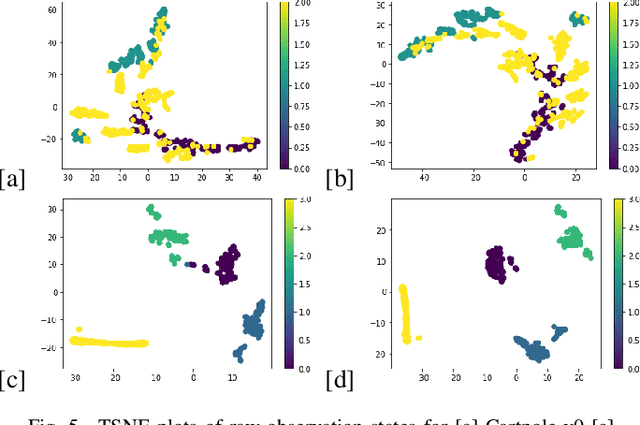
In the realm of sequential decision-making tasks, the exploration capability of a reinforcement learning (RL) agent is paramount for achieving high rewards through interactions with the environment. To enhance this crucial ability, we propose SAQN, a novel approach wherein a self-evolving autoencoder (SA) is embedded with a Q-Network (QN). In SAQN, the self-evolving autoencoder architecture adapts and evolves as the agent explores the environment. This evolution enables the autoencoder to capture a diverse range of raw observations and represent them effectively in its latent space. By leveraging the disentangled states extracted from the encoder generated latent space, the QN is trained to determine optimal actions that improve rewards. During the evolution of the autoencoder architecture, a bias-variance regulatory strategy is employed to elicit the optimal response from the RL agent. This strategy involves two key components: (i) fostering the growth of nodes to retain previously acquired knowledge, ensuring a rich representation of the environment, and (ii) pruning the least contributing nodes to maintain a more manageable and tractable latent space. Extensive experimental evaluations conducted on three distinct benchmark environments and a real-world molecular environment demonstrate that the proposed SAQN significantly outperforms state-of-the-art counterparts. The results highlight the effectiveness of the self-evolving autoencoder and its collaboration with the Q-Network in tackling sequential decision-making tasks.