 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-evolving Autoencoder Embedded Q-Network
Feb 18, 2024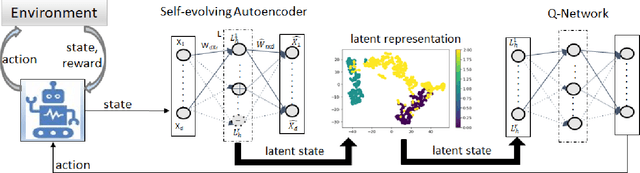

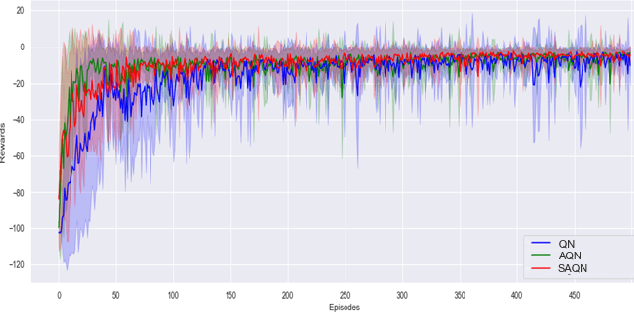
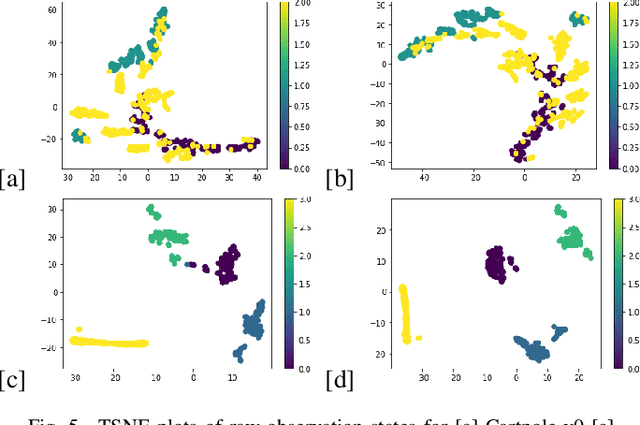
In the realm of sequential decision-making tasks, the exploration capability of a reinforcement learning (RL) agent is paramount for achieving high rewards through interactions with the environment. To enhance this crucial ability, we propose SAQN, a novel approach wherein a self-evolving autoencoder (SA) is embedded with a Q-Network (QN). In SAQN, the self-evolving autoencoder architecture adapts and evolves as the agent explores the environment. This evolution enables the autoencoder to capture a diverse range of raw observations and represent them effectively in its latent space. By leveraging the disentangled states extracted from the encoder generated latent space, the QN is trained to determine optimal actions that improve rewards. During the evolution of the autoencoder architecture, a bias-variance regulatory strategy is employed to elicit the optimal response from the RL agent. This strategy involves two key components: (i) fostering the growth of nodes to retain previously acquired knowledge, ensuring a rich representation of the environment, and (ii) pruning the least contributing nodes to maintain a more manageable and tractable latent space. Extensive experimental evaluations conducted on three distinct benchmark environments and a real-world molecular environment demonstrate that the proposed SAQN significantly outperforms state-of-the-art counterparts. The results highlight the effectiveness of the self-evolving autoencoder and its collaboration with the Q-Network in tackling sequential decision-making tasks.
S-REINFORCE: A Neuro-Symbolic Policy Gradient Approach for Interpretable Reinforcement Learning
May 12, 2023



This paper presents a novel RL algorithm, S-REINFORCE, which is designed to generate interpretable policies for dynamic decision-making tasks. The proposed algorithm leverages two types of function approximators, namely Neural Network (NN) and Symbolic Regressor (SR), to produce numerical and symbolic policies, respectively. The NN component learns to generate a numerical probability distribution over the possible actions using a policy gradient, while the SR component captures the functional form that relates the associated states with the action probabilities. The SR-generated policy expressions are then utilized through importance sampling to improve the rewards received during the learning process. We have tested the proposed S-REINFORCE algorithm on various dynamic decision-making problems with low and high dimensional action spaces, and the results demonstrate its effectiveness and impact in achieving interpretable solutions. By leveraging the strengths of both NN and SR, S-REINFORCE produces policies that are not only well-performing but also easy to interpret, making it an ideal choice for real-world applications where transparency and causality are crucial.