 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptiLookUp: An Optical ROM-Based Loop up Table Engine for Photonic Accelerators
May 05, 2026Read-only memory (ROM) provides deterministic access to predefined data mappings. Extending ROM concepts to the optical domain enables high-bandwidth, low-latency, and parallel memory access, but realizing compact and reconfigurable optical ROM remains challenging due to loss, wavelength control, and integration constraints. This work presents a high-speed, reconfigurable photonic ROM architecture implemented using integrated microring resonators (MRRs). The ROM encodes predefined input-output mappings directly in the spectral response of the photonic devices, enabling deterministic lookup-based operation without dynamic computation during readout. To improve scalability and reduce cumulative insertion loss, the architecture employs compact banked sub-arrays that are selectively addressed through an optical decoding mechanism. Reconfigurability is achieved using transistor-based optical selectors, allowing different ROM banks to be activated without physical light rerouting or interferometric structures. The proposed photonic ROM is designed and evaluated using device-level simulations based on the GlobalFoundries 45SPCLO silicon photonics platform. Simulation results demonstrate reliable operation at data rates up to 12.5 GHz, with stable light-to-current transfer characteristics obtained through integrated photodiode readout. The optical ROM can be used to implement nonlinear activation functions utilised in photonic accelerator architectures, including sigmoid, tanh, ReLU, and exponential mappings.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
A Pathway to Near Tissue Computing through Processing-in-CTIA Pixels for Biomedical Applications
Mar 21, 2025Near-tissue computing requires sensor-level processing of high-resolution images, essential for real-time biomedical diagnostics and surgical guidance. To address this need, we introduce a novel Capacitive Transimpedance Amplifier-based In-Pixel Computing (CTIA-IPC) architecture. Our design leverages CTIA pixels that are widely used for biomedical imaging owing to the inherent advantages of excellent linearity, low noise, and robust operation under low-light conditions. We augment CTIA pixels with IPC to enable precise deep learning computations including multi-channel, multi-bit convolution operations along with integrated batch normalization (BN) and Rectified Linear Unit (ReLU) functionalities in the peripheral ADC (Analog to Digital Converters). This design improves the linearity of Multiply and Accumulate (MAC) operations while enhancing computational efficiency. Leveraging 3D integration to embed pixel circuitry and weight storage, CTIA-IPC maintains pixel density comparable to standard CTIA designs. Moreover, our algorithm-circuit co-design approach enables efficient real-time diagnostics and AI-driven medical analysis. Evaluated on the EndoVis tissu dataset (1280x1024), CTIA-IPC achieves approximately 12x reduction in data bandwidth, yielding segmentation IoUs of 75.91% (parts), and 28.58% (instrument)-a minimal accuracy reduction (1.3%-2.5%) compared to baseline methods. Achieving 1.98 GOPS throughput and 3.39 GOPS/W efficiency, our CTIA-IPC architecture offers a promising computational framework tailored specifically for biomedical near-tissue computing.
Mem-elements based Neuromorphic Hardware for Neural Network Application
Mar 05, 2024



The thesis investigates the utilization of memristive and memcapacitive crossbar arrays in low-power machine learning accelerators, offering a comprehensive co-design framework for deep neural networks (DNN). The model, implemented through a hybrid Python and PyTorch approach, accounts for various non-idealities, achieving exceptional training accuracies of 90.02% and 91.03% for the CIFAR-10 dataset with memristive and memcapacitive crossbar arrays on an 8-layer VGG network. Additionally, the thesis introduces a novel approach to emulate meminductor devices using Operational Transconductance Amplifiers (OTA) and capacitors, showcasing adjustable behavior. Transistor-level simulations in 180 nm CMOS technology, operating at 60 MHz, demonstrate the proposed meminductor emulator's viability with a power consumption of 0.337 mW. The design is further validated in neuromorphic circuits and CNN accelerators, achieving training and testing accuracies of 91.04% and 88.82%, respectively. Notably, the exclusive use of MOS transistors ensures the feasibility of monolithic IC fabrication. This research significantly contributes to the exploration of advanced hardware solutions for efficient and high-performance machine-learning applications.
Analysis and Fully Memristor-based Reservoir Computing for Temporal Data Classification
Mar 04, 2024



Reservoir computing (RC) offers a neuromorphic framework that is particularly effective for processing spatiotemporal signals. Known for its temporal processing prowess, RC significantly lowers training costs compared to conventional recurrent neural networks. A key component in its hardware deployment is the ability to generate dynamic reservoir states. Our research introduces a novel dual-memory RC system, integrating a short-term memory via a WOx-based memristor, capable of achieving 16 distinct states encoded over 4 bits, and a long-term memory component using a TiOx-based memristor within the readout layer. We thoroughly examine both memristor types and leverage the RC system to process temporal data sets. The performance of the proposed RC system is validated through two benchmark tasks: isolated spoken digit recognition with incomplete inputs and Mackey-Glass time series prediction. The system delivered an impressive 98.84% accuracy in digit recognition and sustained a low normalized root mean square error (NRMSE) of 0.036 in the time series prediction task, underscoring its capability. This study illuminates the adeptness of memristor-based RC systems in managing intricate temporal challenges, laying the groundwork for further innovations in neuromorphic computing.
Evolving Restricted Boltzmann Machine-Kohonen Network for Online Clustering
Feb 14, 2024



A novel online clustering algorithm is presented where an Evolving Restricted Boltzmann Machine (ERBM) is embedded with a Kohonen Network called ERBM-KNet. The proposed ERBM-KNet efficiently handles streaming data in a single-pass mode using the ERBM, employing a bias-variance strategy for neuron growing and pruning, as well as online clustering based on a cluster update strategy for cluster prediction and cluster center update using KNet. Initially, ERBM evolves its architecture while processing unlabeled image data, effectively disentangling the data distribution in the latent space. Subsequently, the KNet utilizes the feature extracted from ERBM to predict the number of clusters and updates the cluster centers. By overcoming the common challenges associated with clustering algorithms, such as prior initialization of the number of clusters and subpar clustering accuracy, the proposed ERBM-KNet offers significant improvements. Extensive experimental evaluations on four benchmarks and one industry dataset demonstrate the superiority of ERBM-KNet compared to state-of-the-art approaches.
S-REINFORCE: A Neuro-Symbolic Policy Gradient Approach for Interpretable Reinforcement Learning
May 12, 2023



This paper presents a novel RL algorithm, S-REINFORCE, which is designed to generate interpretable policies for dynamic decision-making tasks. The proposed algorithm leverages two types of function approximators, namely Neural Network (NN) and Symbolic Regressor (SR), to produce numerical and symbolic policies, respectively. The NN component learns to generate a numerical probability distribution over the possible actions using a policy gradient, while the SR component captures the functional form that relates the associated states with the action probabilities. The SR-generated policy expressions are then utilized through importance sampling to improve the rewards received during the learning process. We have tested the proposed S-REINFORCE algorithm on various dynamic decision-making problems with low and high dimensional action spaces, and the results demonstrate its effectiveness and impact in achieving interpretable solutions. By leveraging the strengths of both NN and SR, S-REINFORCE produces policies that are not only well-performing but also easy to interpret, making it an ideal choice for real-world applications where transparency and causality are crucial.
Robust Representation Learning with Self-Distillation for Domain Generalization
Feb 14, 2023



Domain generalization is a challenging problem in machine learning, where the goal is to train a model that can generalize well to unseen target domains without prior knowledge of these domains. Despite the recent success of deep neural networks, there remains a lack of effective methods for domain generalization using vision transformers. In this paper, we propose a novel domain generalization technique called Robust Representation Learning with Self-Distillation (RRLD) that utilizes a combination of i) intermediate-block self-distillation and ii) augmentation-guided self-distillation to improve the generalization capabilities of transformer-based models on unseen domains. This approach enables the network to learn robust and general features that are invariant to different augmentations and domain shifts while effectively mitigating overfitting to source domains. To evaluate the effectiveness of our proposed method, we perform extensive experiments on PACS [1] and OfficeHome [2] benchmark datasets, as well as a real-world wafer semiconductor defect dataset [3]. Our results demonstrate that RRLD achieves robust and accurate generalization performance. We observe an improvement in the range of 0.3% to 2.3% over the state-of-the-art on the three datasets.
Semi-Supervised Super-Resolution
Apr 19, 2022
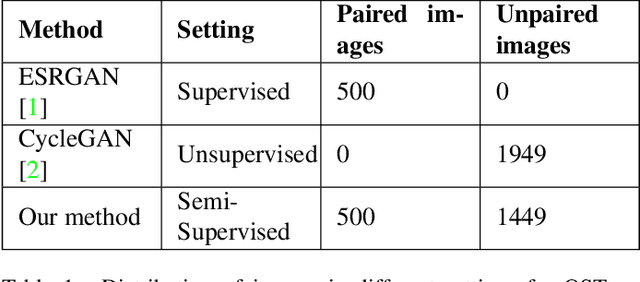
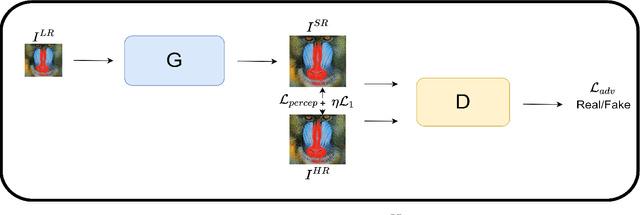
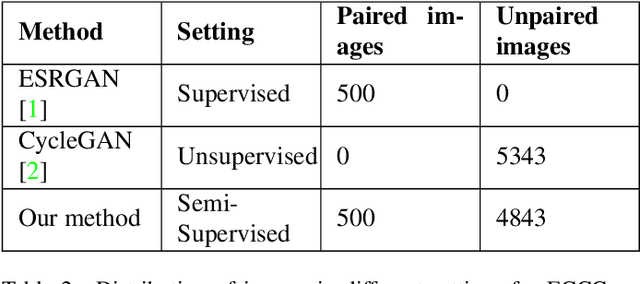
Super-Resolution is the technique to improve the quality of a low-resolution photo by boosting its plausible resolution. The computer vision community has extensively explored the area of Super-Resolution. However, previous Super-Resolution methods require vast amounts of data for training which becomes problematic in domains where very few low-resolution, high-resolution pairs might be available. One such area is statistical downscaling, where super-resolution is increasingly being used to obtain high-resolution climate information from low-resolution data. Acquiring high-resolution climate data is extremely expensive and challenging. To reduce the cost of generating high-resolution climate information, Super-Resolution algorithms should be able to train with a limited number of low-resolution, high-resolution pairs. This paper tries to solve the aforementioned problem by introducing a semi-supervised way to perform super-resolution that can generate sharp, high-resolution images with as few as 500 paired examples. The proposed semi-supervised technique can be used as a plug-and-play module with any supervised GAN-based Super-Resolution method to enhance its performance. We quantitatively and qualitatively analyze the performance of the proposed model and compare it with completely supervised methods as well as other unsupervised techniques. Comprehensive evaluations show the superiority of our method over other methods on different metrics. We also offer the applicability of our approach in statistical downscaling to obtain high-resolution climate images.
CT Image Synthesis Using Weakly Supervised Segmentation and Geometric Inter-Label Relations For COVID Image Analysis
Jun 15, 2021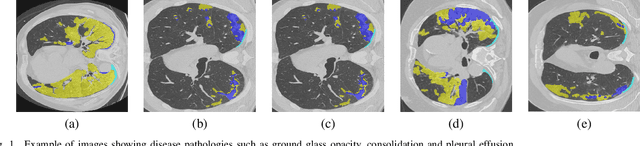
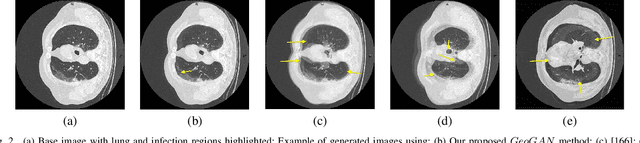
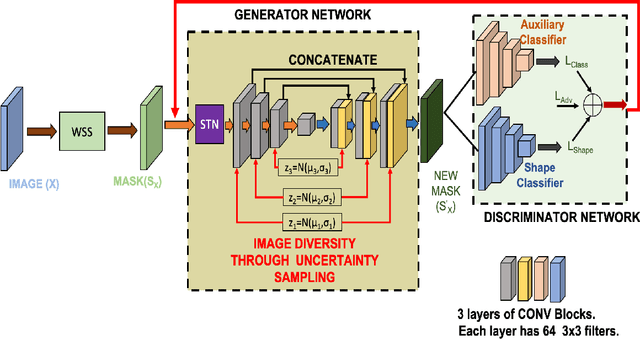
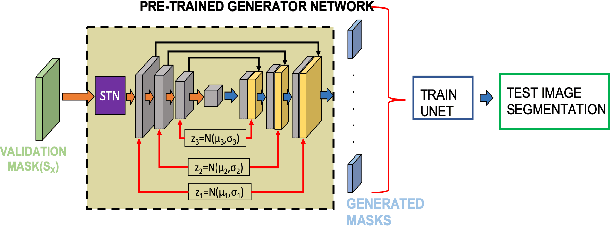
While medical image segmentation is an important task for computer aided diagnosis, the high expertise requirement for pixelwise manual annotations makes it a challenging and time consuming task. Since conventional data augmentations do not fully represent the underlying distribution of the training set, the trained models have varying performance when tested on images captured from different sources. Most prior work on image synthesis for data augmentation ignore the interleaved geometric relationship between different anatomical labels. We propose improvements over previous GAN-based medical image synthesis methods by learning the relationship between different anatomical labels. We use a weakly supervised segmentation method to obtain pixel level semantic label map of images which is used learn the intrinsic relationship of geometry and shape across semantic labels. Latent space variable sampling results in diverse generated images from a base image and improves robustness. We use the synthetic images from our method to train networks for segmenting COVID-19 infected areas from lung CT images. The proposed method outperforms state-of-the-art segmentation methods on a public dataset. Ablation studies also demonstrate benefits of integrating geometry and diversity.