 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Attentive Ranking Networks for Learning to Order Sentences
Dec 31, 2019
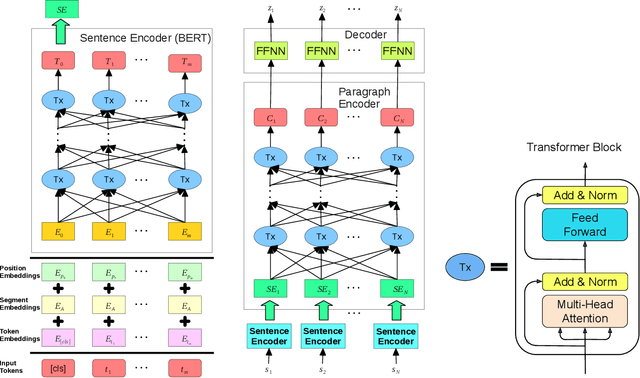
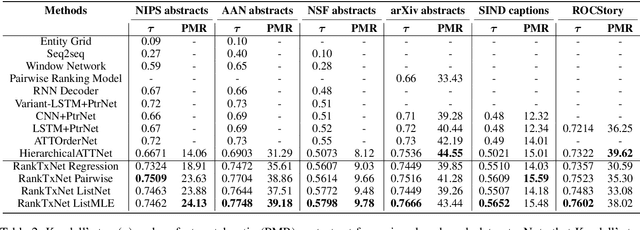

We present an attention-based ranking framework for learning to order sentences given a paragraph. Our framework is built on a bidirectional sentence encoder and a self-attention based transformer network to obtain an input order invariant representation of paragraphs. Moreover, it allows seamless training using a variety of ranking based loss functions, such as pointwise, pairwise, and listwise ranking. We apply our framework on two tasks: Sentence Ordering and Order Discrimination. Our framework outperforms various state-of-the-art methods on these tasks on a variety of evaluation metrics. We also show that it achieves better results when using pairwise and listwise ranking losses, rather than the pointwise ranking loss, which suggests that incorporating relative positions of two or more sentences in the loss function contributes to better learning.
Video Colorization using CNNs and Keyframes extraction: An application in saving bandwidth
Dec 18, 2018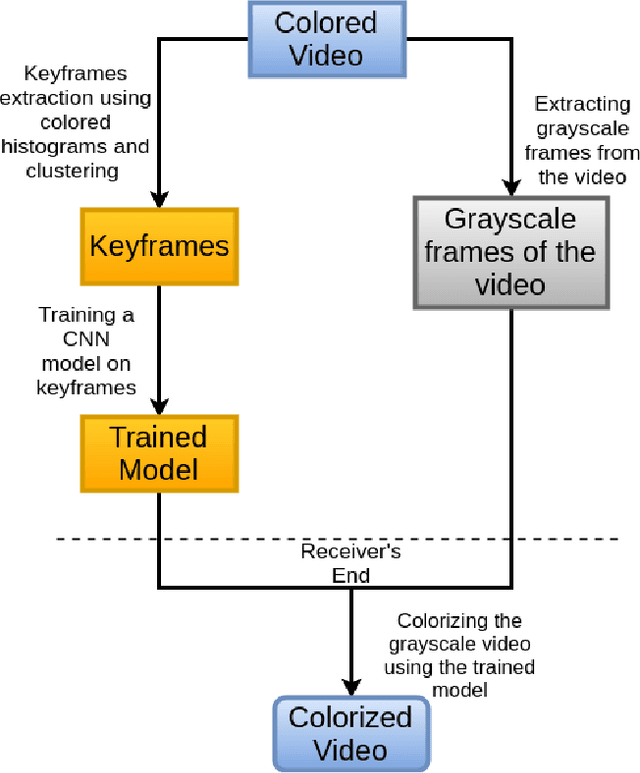


In this paper, we tackle the problem of colorization of grayscale videos to reduce bandwidth usage. For this task, we use some colored keyframes as reference images from the colored version of the grayscale video. We propose a model that extracts keyframes from a colored video and trains a Convolutional Neural Network from scratch on these colored frames. Through the extracted keyframes we get a good knowledge of the colors that have been used in the video which helps us in colorizing the grayscale version of the video efficiently. An application of the technique that we propose in this paper, is in saving bandwidth while sending raw colored videos that haven't gone through any compression. A raw colored video takes up around three times more memory size than its grayscale version. We can exploit this fact and send a grayscale video along with out trained model instead of a colored video. Later on, in this paper we show how this technique can help to save bandwidth usage to upto three times while transmitting raw colored videos.
Bayes-optimal Hierarchical Classification over Asymmetric Tree-Distance Loss
Feb 17, 2018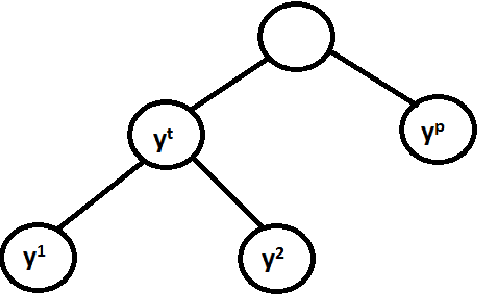
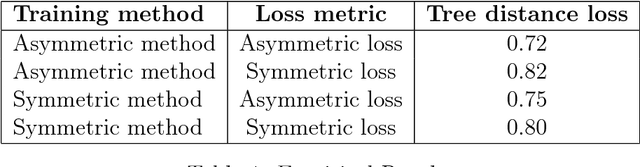
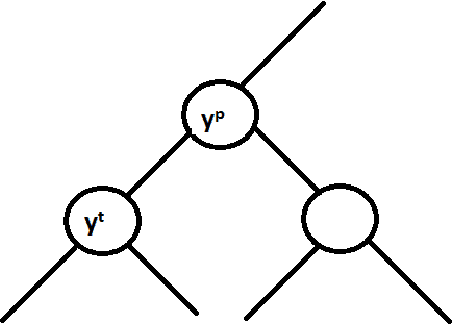
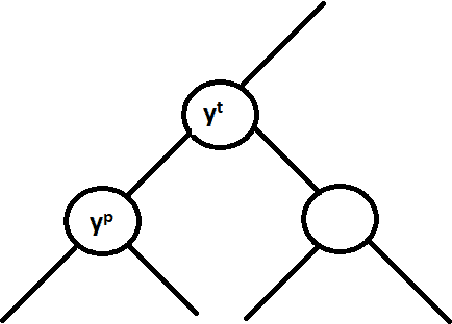
Hierarchical classification is supervised multi-class classification problem over the set of class labels organized according to a hierarchy. In this report, we study the work by Ramaswamy et. al. on hierarchical classification over symmetric tree distance loss. We extend the consistency of hierarchical classification algorithm over asymmetric tree distance loss. We design a $\mathcal{O}(nk\log{}n)$ algorithm to find Bayes optimal classification for a k-ary tree as a hierarchy. We show that under reasonable assumptions over asymmetric loss function, the Bayes optimal classification over this asymmetric loss can be found in $\mathcal{O}(k\log{}n)$. We exploit this insight and attempt to extend the Ova-Cascade algorithm \citet{ramaswamy2015convex} for hierarchical classification over the asymmetric loss.
Leveraging Distributional Semantics for Multi-Label Learning
Nov 10, 2017

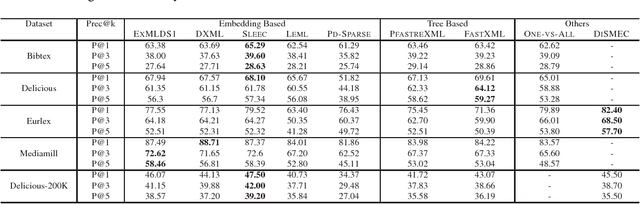
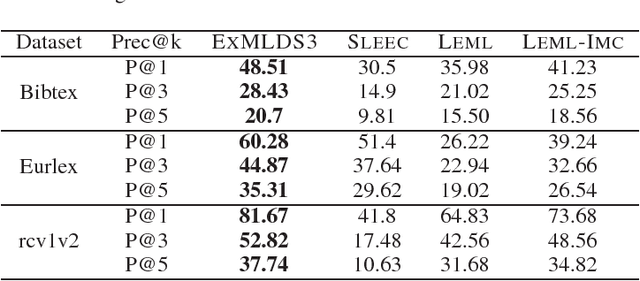
We present a novel and scalable label embedding framework for large-scale multi-label learning a.k.a ExMLDS (Extreme Multi-Label Learning using Distributional Semantics). Our approach draws inspiration from ideas rooted in distributional semantics, specifically the Skip Gram Negative Sampling (SGNS) approach, widely used to learn word embeddings for natural language processing tasks. Learning such embeddings can be reduced to a certain matrix factorization. Our approach is novel in that it highlights interesting connections between label embedding methods used for multi-label learning and paragraph/document embedding methods commonly used for learning representations of text data. The framework can also be easily extended to incorporate auxiliary information such as label-label correlations; this is crucial especially when there are a lot of missing labels in the training data. We demonstrate the effectiveness of our approach through an extensive set of experiments on a variety of benchmark datasets, and show that the proposed learning methods perform favorably compared to several baselines and state-of-the-art methods for large-scale multi-label learning. To facilitate end-to-end learning, we develop a joint learning algorithm that can learn the embeddings as well as a regression model that predicts these embeddings given input features, via efficient gradient-based methods.
Text Summarization using Abstract Meaning Representation
Jul 17, 2017

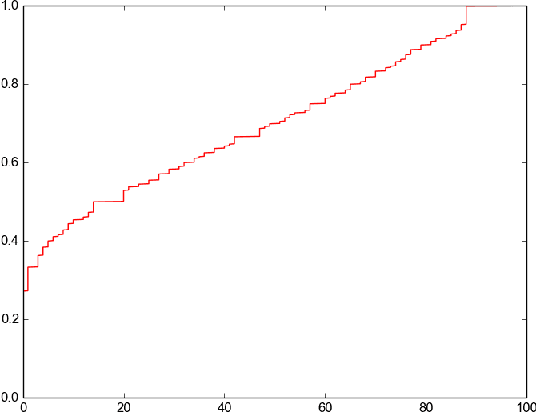

With an ever increasing size of text present on the Internet, automatic summary generation remains an important problem for natural language understanding. In this work we explore a novel full-fledged pipeline for text summarization with an intermediate step of Abstract Meaning Representation (AMR). The pipeline proposed by us first generates an AMR graph of an input story, through which it extracts a summary graph and finally, generate summary sentences from this summary graph. Our proposed method achieves state-of-the-art results compared to the other text summarization routines based on AMR. We also point out some significant problems in the existing evaluation methods, which make them unsuitable for evaluating summary quality.
User Bias Removal in Review Score Prediction
May 12, 2017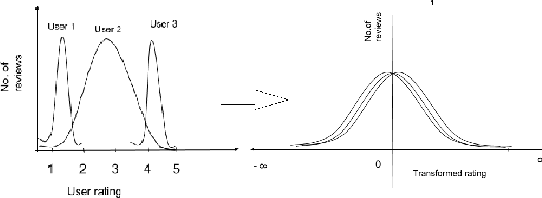
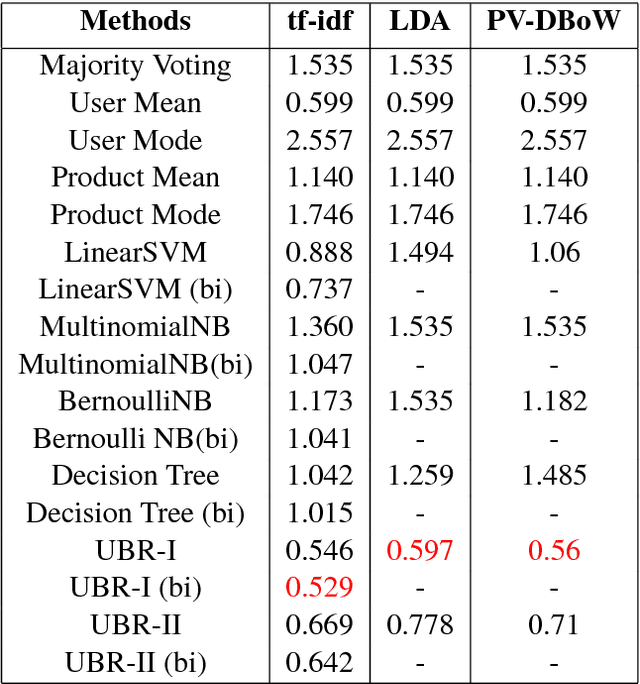
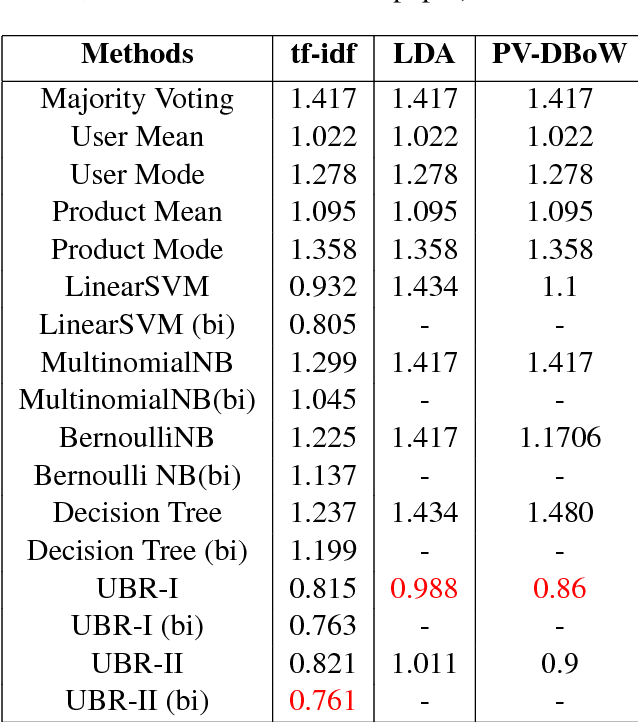
Review score prediction of text reviews has recently gained a lot of attention in recommendation systems. A major problem in models for review score prediction is the presence of noise due to user-bias in review scores. We propose two simple statistical methods to remove such noise and improve review score prediction. Compared to other methods that use multiple classifiers, one for each user, our model uses a single global classifier to predict review scores. We empirically evaluate our methods on two major categories (\textit{Electronics} and \textit{Movies and TV}) of the SNAP published Amazon e-Commerce Reviews data-set and Amazon \textit{Fine Food} reviews data-set. We obtain improved review score prediction for three commonly used text feature representations.
SCDV : Sparse Composite Document Vectors using soft clustering over distributional representations
May 12, 2017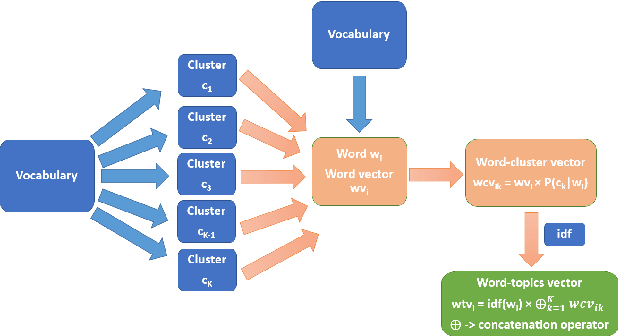
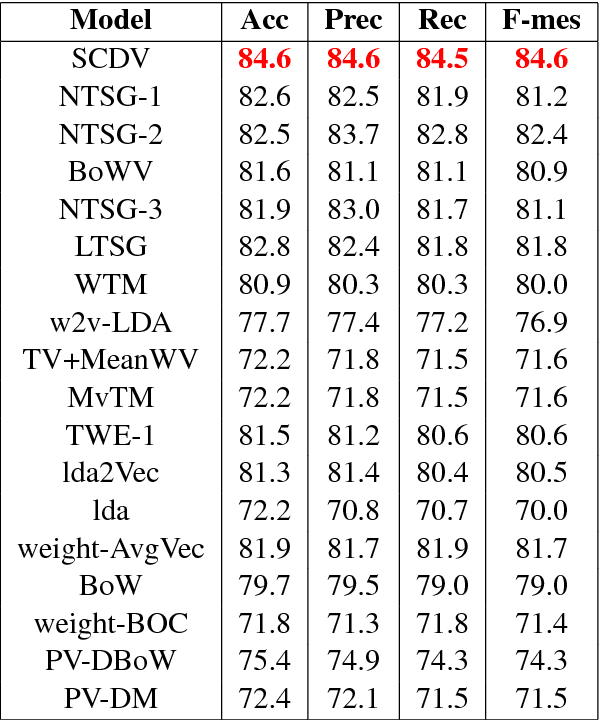
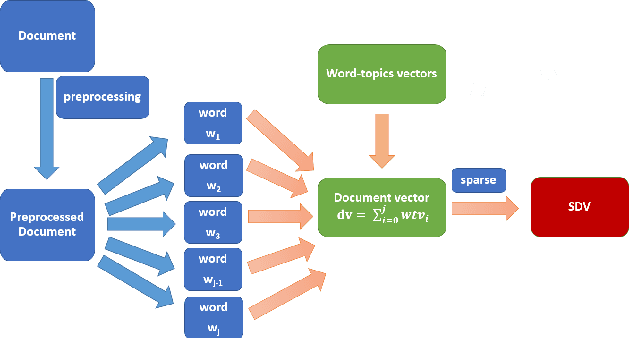
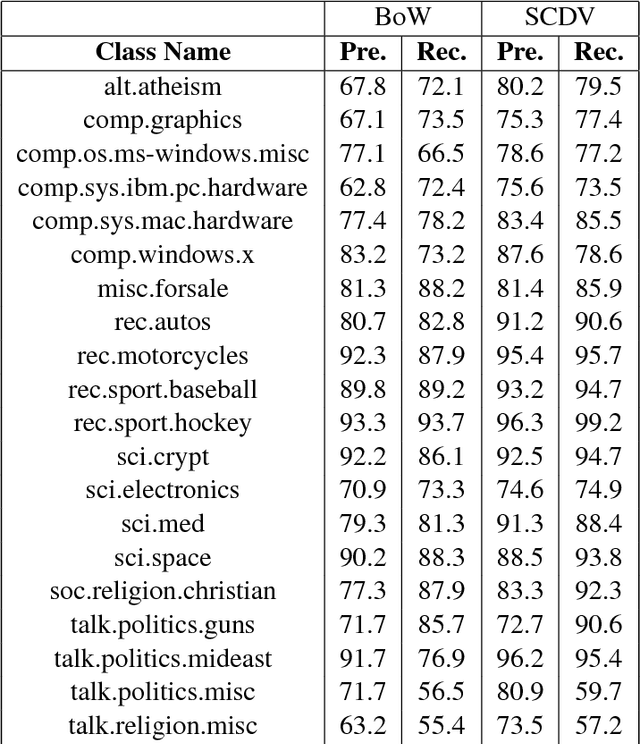
We present a feature vector formation technique for documents - Sparse Composite Document Vector (SCDV) - which overcomes several shortcomings of the current distributional paragraph vector representations that are widely used for text representation. In SCDV, word embedding's are clustered to capture multiple semantic contexts in which words occur. They are then chained together to form document topic-vectors that can express complex, multi-topic documents. Through extensive experiments on multi-class and multi-label classification tasks, we outperform the previous state-of-the-art method, NTSG (Liu et al., 2015a). We also show that SCDV embedding's perform well on heterogeneous tasks like Topic Coherence, context-sensitive Learning and Information Retrieval. Moreover, we achieve significant reduction in training and prediction times compared to other representation methods. SCDV achieves best of both worlds - better performance with lower time and space complexity.
Product Classification in E-Commerce using Distributional Semantics
Jul 25, 2016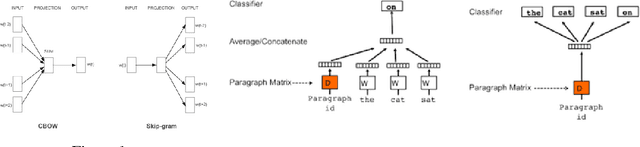

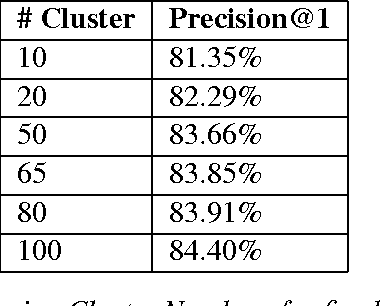
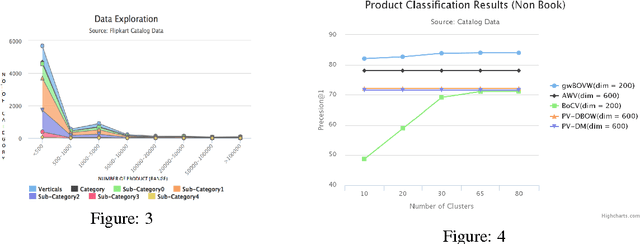
Product classification is the task of automatically predicting a taxonomy path for a product in a predefined taxonomy hierarchy given a textual product description or title. For efficient product classification we require a suitable representation for a document (the textual description of a product) feature vector and efficient and fast algorithms for prediction. To address the above challenges, we propose a new distributional semantics representation for document vector formation. We also develop a new two-level ensemble approach utilizing (with respect to the taxonomy tree) a path-wise, node-wise and depth-wise classifiers for error reduction in the final product classification. Our experiments show the effectiveness of the distributional representation and the ensemble approach on data sets from a leading e-commerce platform and achieve better results on various evaluation metrics compared to earlier approaches.
On Translation Invariant Kernels and Screw Functions
Feb 18, 2013We explore the connection between Hilbertian metrics and positive definite kernels on the real line. In particular, we look at a well-known characterization of translation invariant Hilbertian metrics on the real line by von Neumann and Schoenberg (1941). Using this result we are able to give an alternate proof of Bochner's theorem for translation invariant positive definite kernels on the real line (Rudin, 1962).
Random Feature Maps for Dot Product Kernels
Mar 26, 2012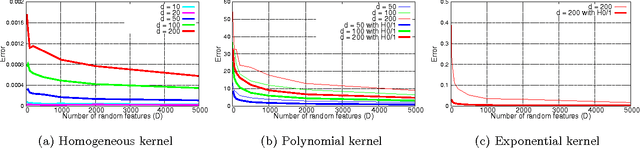
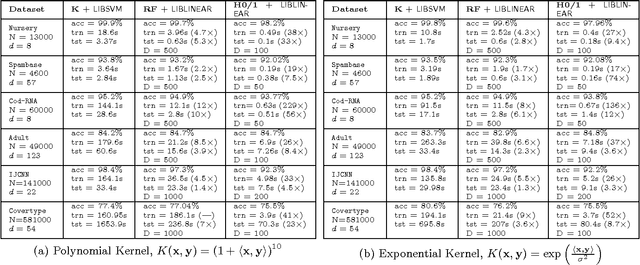
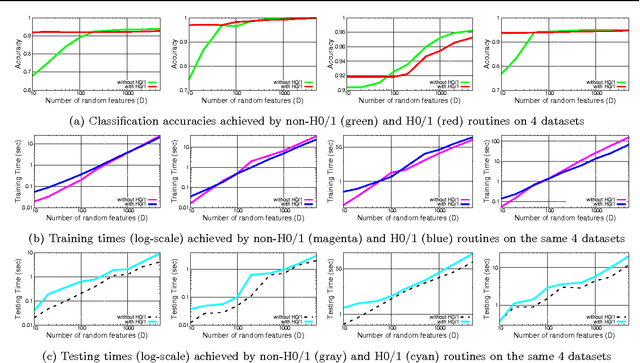
Approximating non-linear kernels using feature maps has gained a lot of interest in recent years due to applications in reducing training and testing times of SVM classifiers and other kernel based learning algorithms. We extend this line of work and present low distortion embeddings for dot product kernels into linear Euclidean spaces. We base our results on a classical result in harmonic analysis characterizing all dot product kernels and use it to define randomized feature maps into explicit low dimensional Euclidean spaces in which the native dot product provides an approximation to the dot product kernel with high confidence.
* To appear in the proceedings of the 15th International Conference on Artificial Intelligence and Statistics (AISTATS 2012). This version corrects a minor error with Lemma 10. Acknowledgements : Devanshu Bhimwal