 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: A Novelty Gate for Efficient Memory Evolution in Agentic LLMs
May 29, 2026Agentic LLMs must continuously decide whether newly extracted facts should be added, merged with existing memories, or ignored, yet prior work has focused more on retrieval and storage than on principled write-side control. We frame memory evolution as a novelty-detection problem and propose SAGE, a Spherical Adaptive Gate for memory Evolution that scores candidate facts with a von Mises-Fisher-based density estimator over memory embeddings and routes them with an adaptive threshold that tracks memory-store geometry. SAGE resolves clearly novel facts as ADD, clearly redundant facts as NOOP, and sends only uncertain cases to an LLM merge step, reducing expensive write-time reasoning. On LoCoMo, SAGE achieves the best average token-F1 against Mem0 on all seven open-weight backbone comparisons, while on GPT-4o-mini it reduces add-phase API cost by 3.4$\times$ and add-phase latency by 2.5$\times$ with only a small average judge-score gap. As a drop-in binary gate for A-Mem, SAGE skips roughly 16-18% of LLM calls across five models with minimal quality change on open-weight backbones. These results suggest that novelty-aware write control is a practical lever for improving both memory quality and system efficiency in long-term agentic memory.
A Probabilistic Framework for Lifelong Test-Time Adaptation
Dec 19, 2022



Test-time adaptation is the problem of adapting a source pre-trained model using test inputs from a target domain without access to source domain data. Most of the existing approaches address the setting in which the target domain is stationary. Moreover, these approaches are prone to making erroneous predictions with unreliable uncertainty estimates when distribution shifts occur. Hence, test-time adaptation in the face of non-stationary target domain shift becomes a problem of significant interest. To address these issues, we propose a principled approach, PETAL (Probabilistic lifElong Test-time Adaptation with seLf-training prior), which looks into this problem from a probabilistic perspective using a partly data-dependent prior. A student-teacher framework, where the teacher model is an exponential moving average of the student model naturally emerges from this probabilistic perspective. In addition, the knowledge from the posterior distribution obtained for the source task acts as a regularizer. To handle catastrophic forgetting in the long term, we also propose a data-driven model parameter resetting mechanism based on the Fisher information matrix (FIM). Moreover, improvements in experimental results suggest that FIM based data-driven parameter restoration contributes to reducing the error accumulation and maintaining the knowledge of recent domain by restoring only the irrelevant parameters. In terms of predictive error rate as well as uncertainty based metrics such as Brier score and negative log-likelihood, our method achieves better results than the current state-of-the-art for online lifelong test time adaptation across various benchmarks, such as CIFAR-10C, CIFAR-100C, ImageNetC, and ImageNet3DCC datasets.
Hypernetworks for Continual Semi-Supervised Learning
Oct 05, 2021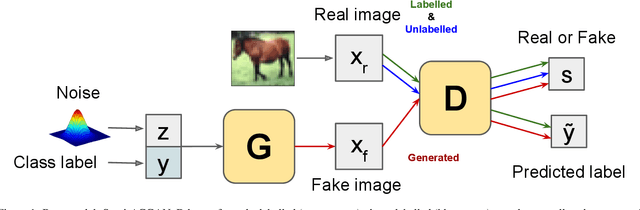


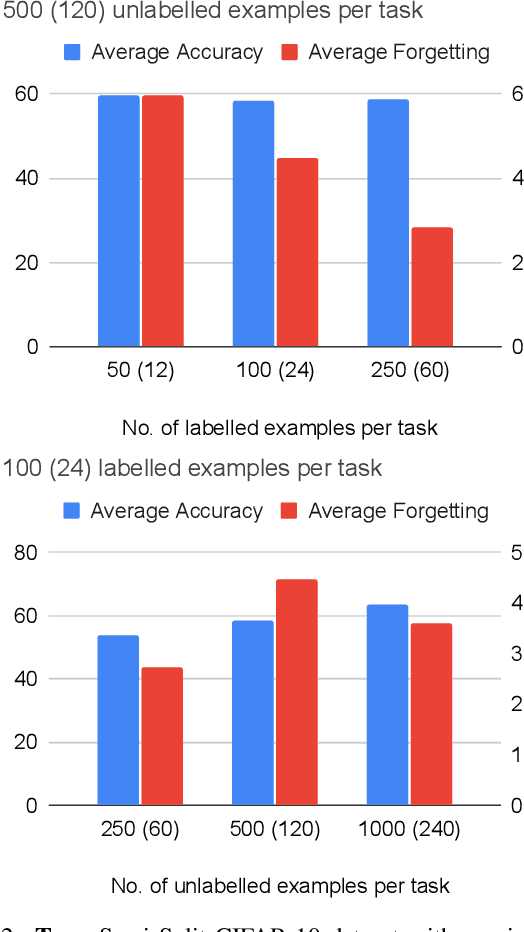
Learning from data sequentially arriving, possibly in a non i.i.d. way, with changing task distribution over time is called continual learning. Much of the work thus far in continual learning focuses on supervised learning and some recent works on unsupervised learning. In many domains, each task contains a mix of labelled (typically very few) and unlabelled (typically plenty) training examples, which necessitates a semi-supervised learning approach. To address this in a continual learning setting, we propose a framework for semi-supervised continual learning called Meta-Consolidation for Continual Semi-Supervised Learning (MCSSL). Our framework has a hypernetwork that learns the meta-distribution that generates the weights of a semi-supervised auxiliary classifier generative adversarial network $(\textit{Semi-ACGAN})$ as the base network. We consolidate the knowledge of sequential tasks in the hypernetwork, and the base network learns the semi-supervised learning task. Further, we present $\textit{Semi-Split CIFAR-10}$, a new benchmark for continual semi-supervised learning, obtained by modifying the $\textit{Split CIFAR-10}$ dataset, in which the tasks with labelled and unlabelled data arrive sequentially. Our proposed model yields significant improvements in the continual semi-supervised learning setting. We compare the performance of several existing continual learning approaches on the proposed continual semi-supervised learning benchmark of the Semi-Split CIFAR-10 dataset.
Fine-Grained Emotion Prediction by Modeling Emotion Definitions
Jul 26, 2021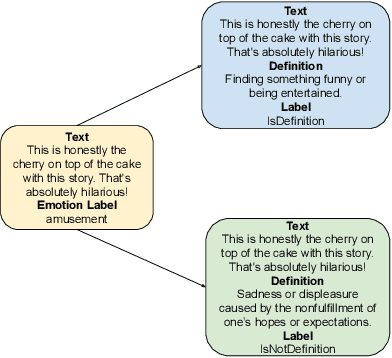
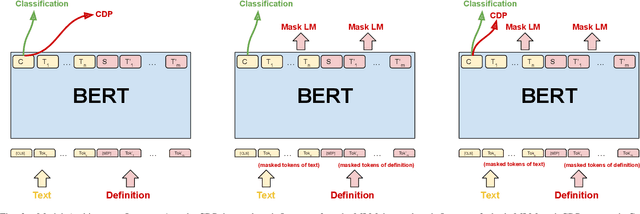
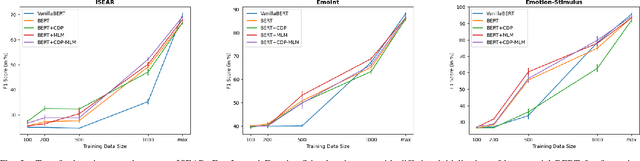

In this paper, we propose a new framework for fine-grained emotion prediction in the text through emotion definition modeling. Our approach involves a multi-task learning framework that models definitions of emotions as an auxiliary task while being trained on the primary task of emotion prediction. We model definitions using masked language modeling and class definition prediction tasks. Our models outperform existing state-of-the-art for fine-grained emotion dataset GoEmotions. We further show that this trained model can be used for transfer learning on other benchmark datasets in emotion prediction with varying emotion label sets, domains, and sizes. The proposed models outperform the baselines on transfer learning experiments demonstrating the generalization capability of the models.
Deep Attentive Ranking Networks for Learning to Order Sentences
Dec 31, 2019
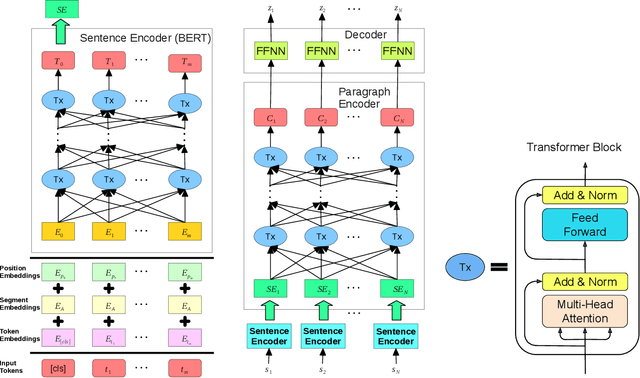
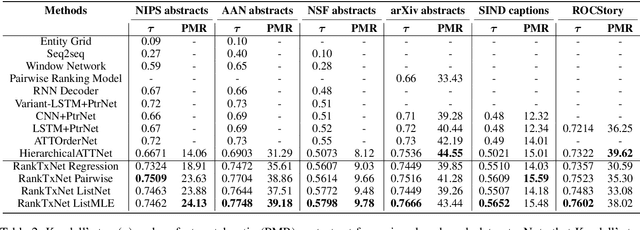

We present an attention-based ranking framework for learning to order sentences given a paragraph. Our framework is built on a bidirectional sentence encoder and a self-attention based transformer network to obtain an input order invariant representation of paragraphs. Moreover, it allows seamless training using a variety of ranking based loss functions, such as pointwise, pairwise, and listwise ranking. We apply our framework on two tasks: Sentence Ordering and Order Discrimination. Our framework outperforms various state-of-the-art methods on these tasks on a variety of evaluation metrics. We also show that it achieves better results when using pairwise and listwise ranking losses, rather than the pointwise ranking loss, which suggests that incorporating relative positions of two or more sentences in the loss function contributes to better learning.
A Meta-Learning Framework for Generalized Zero-Shot Learning
Sep 10, 2019
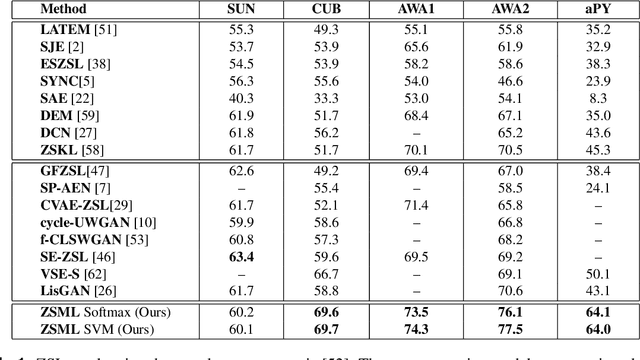
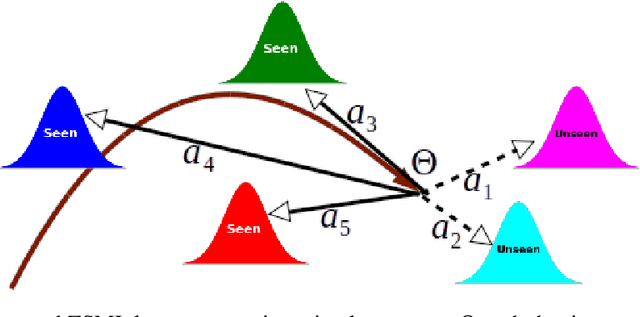

Learning to classify unseen class samples at test time is popularly referred to as zero-shot learning (ZSL). If test samples can be from training (seen) as well as unseen classes, it is a more challenging problem due to the existence of strong bias towards seen classes. This problem is generally known as \emph{generalized} zero-shot learning (GZSL). Thanks to the recent advances in generative models such as VAEs and GANs, sample synthesis based approaches have gained considerable attention for solving this problem. These approaches are able to handle the problem of class bias by synthesizing unseen class samples. However, these ZSL/GZSL models suffer due to the following key limitations: $(i)$ Their training stage learns a class-conditioned generator using only \emph{seen} class data and the training stage does not \emph{explicitly} learn to generate the unseen class samples; $(ii)$ They do not learn a generic optimal parameter which can easily generalize for both seen and unseen class generation; and $(iii)$ If we only have access to a very few samples per seen class, these models tend to perform poorly. In this paper, we propose a meta-learning based generative model that naturally handles these limitations. The proposed model is based on integrating model-agnostic meta learning with a Wasserstein GAN (WGAN) to handle $(i)$ and $(iii)$, and uses a novel task distribution to handle $(ii)$. Our proposed model yields significant improvements on standard ZSL as well as more challenging GZSL setting. In ZSL setting, our model yields 4.5\%, 6.0\%, 9.8\%, and 27.9\% relative improvements over the current state-of-the-art on CUB, AWA1, AWA2, and aPY datasets, respectively.