 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Distributional Semantics for Multi-Label Learning
Nov 10, 2017

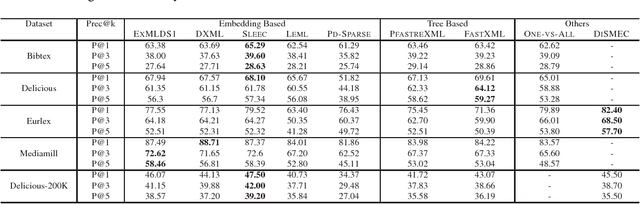
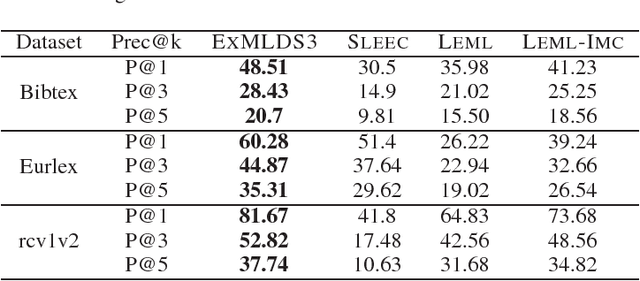
We present a novel and scalable label embedding framework for large-scale multi-label learning a.k.a ExMLDS (Extreme Multi-Label Learning using Distributional Semantics). Our approach draws inspiration from ideas rooted in distributional semantics, specifically the Skip Gram Negative Sampling (SGNS) approach, widely used to learn word embeddings for natural language processing tasks. Learning such embeddings can be reduced to a certain matrix factorization. Our approach is novel in that it highlights interesting connections between label embedding methods used for multi-label learning and paragraph/document embedding methods commonly used for learning representations of text data. The framework can also be easily extended to incorporate auxiliary information such as label-label correlations; this is crucial especially when there are a lot of missing labels in the training data. We demonstrate the effectiveness of our approach through an extensive set of experiments on a variety of benchmark datasets, and show that the proposed learning methods perform favorably compared to several baselines and state-of-the-art methods for large-scale multi-label learning. To facilitate end-to-end learning, we develop a joint learning algorithm that can learn the embeddings as well as a regression model that predicts these embeddings given input features, via efficient gradient-based methods.
User Bias Removal in Review Score Prediction
May 12, 2017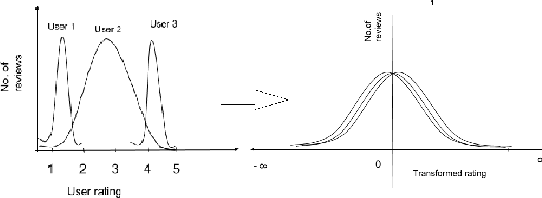
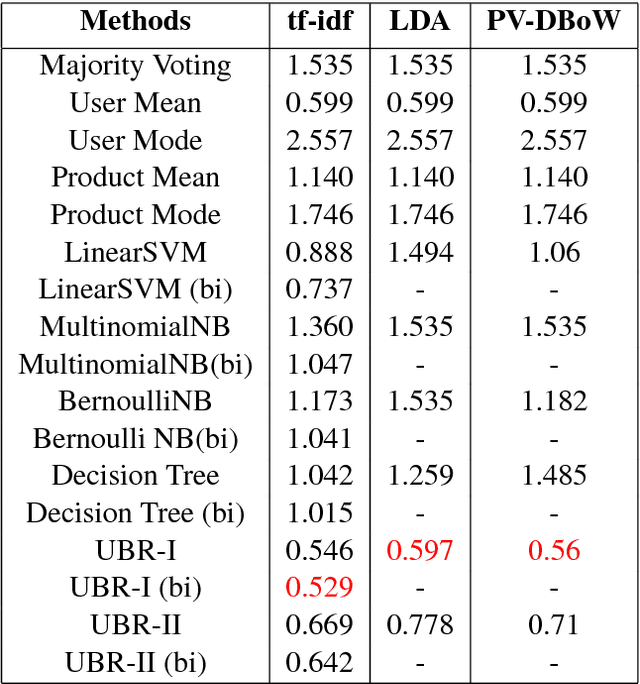
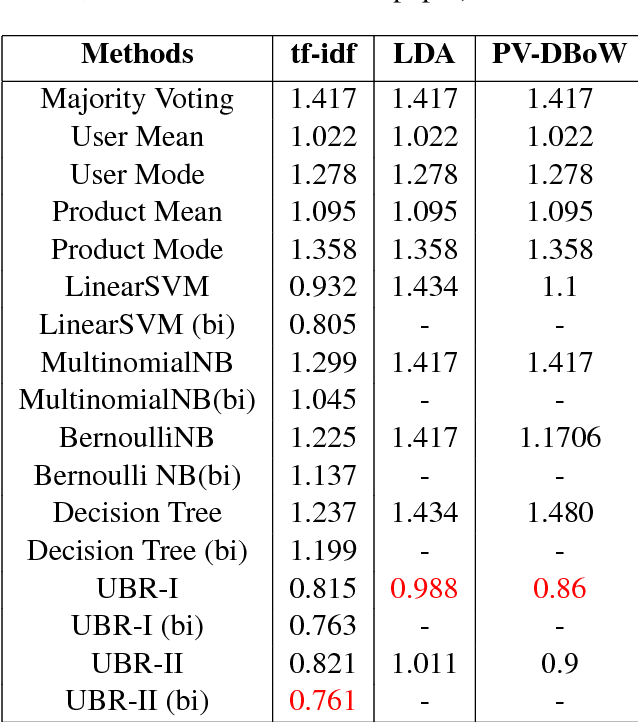
Review score prediction of text reviews has recently gained a lot of attention in recommendation systems. A major problem in models for review score prediction is the presence of noise due to user-bias in review scores. We propose two simple statistical methods to remove such noise and improve review score prediction. Compared to other methods that use multiple classifiers, one for each user, our model uses a single global classifier to predict review scores. We empirically evaluate our methods on two major categories (\textit{Electronics} and \textit{Movies and TV}) of the SNAP published Amazon e-Commerce Reviews data-set and Amazon \textit{Fine Food} reviews data-set. We obtain improved review score prediction for three commonly used text feature representations.