 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair in Mind, Fair in Action? A Synchronous Benchmark for Understanding and Generation in UMLLMs
Feb 28, 2026As artificial intelligence (AI) is increasingly deployed across domains, ensuring fairness has become a core challenge. However, the field faces a "Tower of Babel'' dilemma: fairness metrics abound, yet their underlying philosophical assumptions often conflict, hindering unified paradigms-particularly in unified Multimodal Large Language Models (UMLLMs), where biases propagate systemically across tasks. To address this, we introduce the IRIS Benchmark, to our knowledge the first benchmark designed to synchronously evaluate the fairness of both understanding and generation tasks in UMLLMs. Enabled by our demographic classifier, ARES, and four supporting large-scale datasets, the benchmark is designed to normalize and aggregate arbitrary metrics into a high-dimensional "fairness space'', integrating 60 granular metrics across three dimensions-Ideal Fairness, Real-world Fidelity, and Bias Inertia & Steerability (IRIS). Through this benchmark, our evaluation of leading UMLLMs uncovers systemic phenomena such as the "generation gap'', individual inconsistencies like "personality splits'', and the "counter-stereotype reward'', while offering diagnostics to guide the optimization of their fairness capabilities. With its novel and extensible framework, the IRIS benchmark is capable of integrating evolving fairness metrics, ultimately helping to resolve the "Tower of Babel'' impasse. Project Page: https://iris-benchmark-web.vercel.app/
Jailbreaking Commercial Black-Box LLMs with Explicitly Harmful Prompts
Aug 14, 2025Evaluating jailbreak attacks is challenging when prompts are not overtly harmful or fail to induce harmful outputs. Unfortunately, many existing red-teaming datasets contain such unsuitable prompts. To evaluate attacks accurately, these datasets need to be assessed and cleaned for maliciousness. However, existing malicious content detection methods rely on either manual annotation, which is labor-intensive, or large language models (LLMs), which have inconsistent accuracy in harmful types. To balance accuracy and efficiency, we propose a hybrid evaluation framework named MDH (Malicious content Detection based on LLMs with Human assistance) that combines LLM-based annotation with minimal human oversight, and apply it to dataset cleaning and detection of jailbroken responses. Furthermore, we find that well-crafted developer messages can significantly boost jailbreak success, leading us to propose two new strategies: D-Attack, which leverages context simulation, and DH-CoT, which incorporates hijacked chains of thought. The Codes, datasets, judgements, and detection results will be released in github repository: https://github.com/AlienZhang1996/DH-CoT.
GADT: Enhancing Transferable Adversarial Attacks through Gradient-guided Adversarial Data Transformation
Oct 24, 2024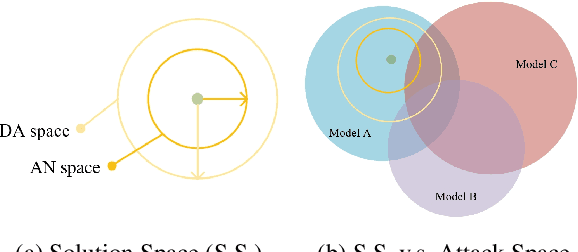
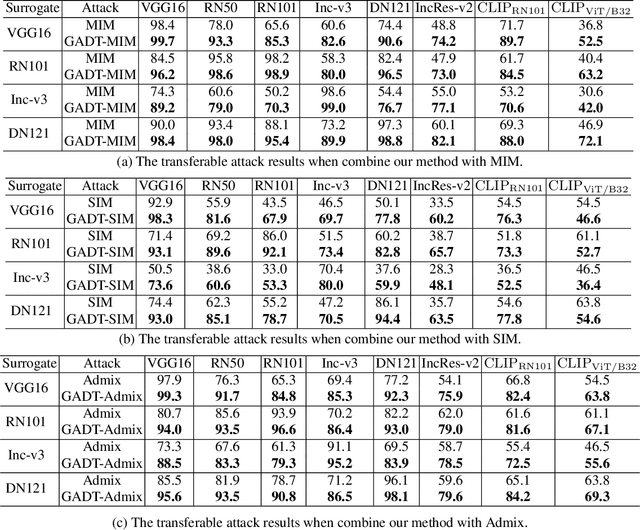
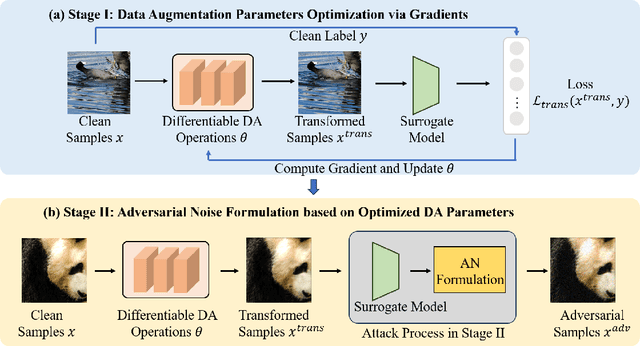

Current Transferable Adversarial Examples (TAE) are primarily generated by adding Adversarial Noise (AN). Recent studies emphasize the importance of optimizing Data Augmentation (DA) parameters along with AN, which poses a greater threat to real-world AI applications. However, existing DA-based strategies often struggle to find optimal solutions due to the challenging DA search procedure without proper guidance. In this work, we propose a novel DA-based attack algorithm, GADT. GADT identifies suitable DA parameters through iterative antagonism and uses posterior estimates to update AN based on these parameters. We uniquely employ a differentiable DA operation library to identify adversarial DA parameters and introduce a new loss function as a metric during DA optimization. This loss term enhances adversarial effects while preserving the original image content, maintaining attack crypticity. Extensive experiments on public datasets with various networks demonstrate that GADT can be integrated with existing transferable attack methods, updating their DA parameters effectively while retaining their AN formulation strategies. Furthermore, GADT can be utilized in other black-box attack scenarios, e.g., query-based attacks, offering a new avenue to enhance attacks on real-world AI applications in both research and industrial contexts.
SSL-OTA: Unveiling Backdoor Threats in Self-Supervised Learning for Object Detection
Dec 30, 2023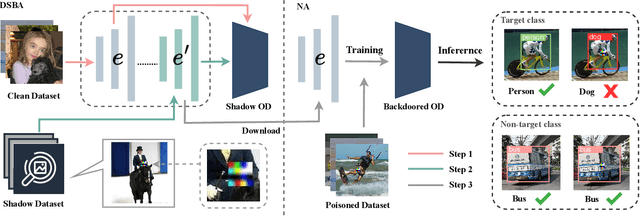

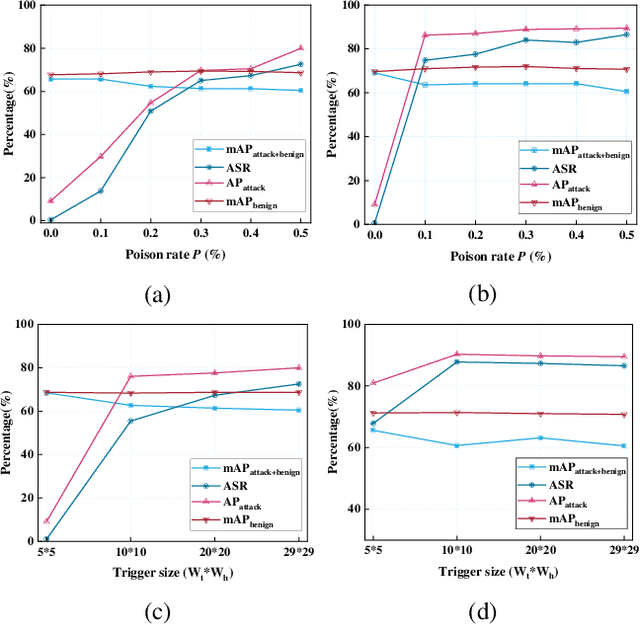
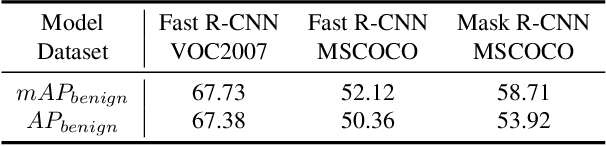
The extensive adoption of Self-supervised learning (SSL) has led to an increased security threat from backdoor attacks. While existing research has mainly focused on backdoor attacks in image classification, there has been limited exploration into their implications for object detection. In this work, we propose the first backdoor attack designed for object detection tasks in SSL scenarios, termed Object Transform Attack (SSL-OTA). SSL-OTA employs a trigger capable of altering predictions of the target object to the desired category, encompassing two attacks: Data Poisoning Attack (NA) and Dual-Source Blending Attack (DSBA). NA conducts data poisoning during downstream fine-tuning of the object detector, while DSBA additionally injects backdoors into the pre-trained encoder. We establish appropriate metrics and conduct extensive experiments on benchmark datasets, demonstrating the effectiveness and utility of our proposed attack. Notably, both NA and DSBA achieve high attack success rates (ASR) at extremely low poisoning rates (0.5%). The results underscore the importance of considering backdoor threats in SSL-based object detection and contribute a novel perspective to the field.
GhostEncoder: Stealthy Backdoor Attacks with Dynamic Triggers to Pre-trained Encoders in Self-supervised Learning
Oct 01, 2023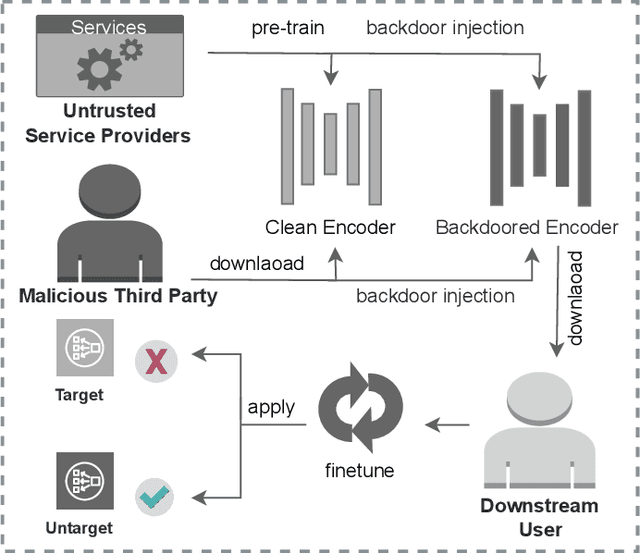

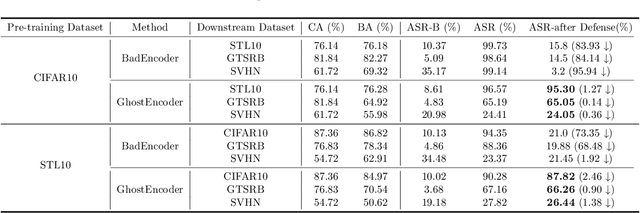
Within the realm of computer vision, self-supervised learning (SSL) pertains to training pre-trained image encoders utilizing a substantial quantity of unlabeled images. Pre-trained image encoders can serve as feature extractors, facilitating the construction of downstream classifiers for various tasks. However, the use of SSL has led to an increase in security research related to various backdoor attacks. Currently, the trigger patterns used in backdoor attacks on SSL are mostly visible or static (sample-agnostic), making backdoors less covert and significantly affecting the attack performance. In this work, we propose GhostEncoder, the first dynamic invisible backdoor attack on SSL. Unlike existing backdoor attacks on SSL, which use visible or static trigger patterns, GhostEncoder utilizes image steganography techniques to encode hidden information into benign images and generate backdoor samples. We then fine-tune the pre-trained image encoder on a manipulation dataset to inject the backdoor, enabling downstream classifiers built upon the backdoored encoder to inherit the backdoor behavior for target downstream tasks. We evaluate GhostEncoder on three downstream tasks and results demonstrate that GhostEncoder provides practical stealthiness on images and deceives the victim model with a high attack success rate without compromising its utility. Furthermore, GhostEncoder withstands state-of-the-art defenses, including STRIP, STRIP-Cl, and SSL-Cleanse.
SSL-Auth: An Authentication Framework by Fragile Watermarking for Pre-trained Encoders in Self-supervised Learning
Aug 16, 2023



Self-supervised learning (SSL), utilizing unlabeled datasets for training powerful encoders, has achieved significant success recently. These encoders serve as feature extractors for downstream tasks, requiring substantial resources. However, the challenge of protecting the intellectual property of encoder trainers and ensuring the trustworthiness of deployed encoders remains a significant gap in SSL. Moreover, recent researches highlight threats to pre-trained encoders, such as backdoor and adversarial attacks. To address these gaps, we propose SSL-Auth, the first authentication framework designed specifically for pre-trained encoders. In particular, SSL-Auth utilizes selected key samples as watermark information and trains a verification network to reconstruct the watermark information, thereby verifying the integrity of the encoder without compromising model performance. By comparing the reconstruction results of the key samples, malicious alterations can be detected, as modified encoders won't mimic the original reconstruction. Comprehensive evaluations on various encoders and diverse downstream tasks demonstrate the effectiveness and fragility of our proposed SSL-Auth.
Hard Adversarial Example Mining for Improving Robust Fairness
Aug 03, 2023



Adversarial training (AT) is widely considered the state-of-the-art technique for improving the robustness of deep neural networks (DNNs) against adversarial examples (AE). Nevertheless, recent studies have revealed that adversarially trained models are prone to unfairness problems, restricting their applicability. In this paper, we empirically observe that this limitation may be attributed to serious adversarial confidence overfitting, i.e., certain adversarial examples with overconfidence. To alleviate this problem, we propose HAM, a straightforward yet effective framework via adaptive Hard Adversarial example Mining.HAM concentrates on mining hard adversarial examples while discarding the easy ones in an adaptive fashion. Specifically, HAM identifies hard AEs in terms of their step sizes needed to cross the decision boundary when calculating loss value. Besides, an early-dropping mechanism is incorporated to discard the easy examples at the initial stages of AE generation, resulting in efficient AT. Extensive experimental results on CIFAR-10, SVHN, and Imagenette demonstrate that HAM achieves significant improvement in robust fairness while reducing computational cost compared to several state-of-the-art adversarial training methods. The code will be made publicly available.
What can Discriminator do? Towards Box-free Ownership Verification of Generative Adversarial Network
Jul 29, 2023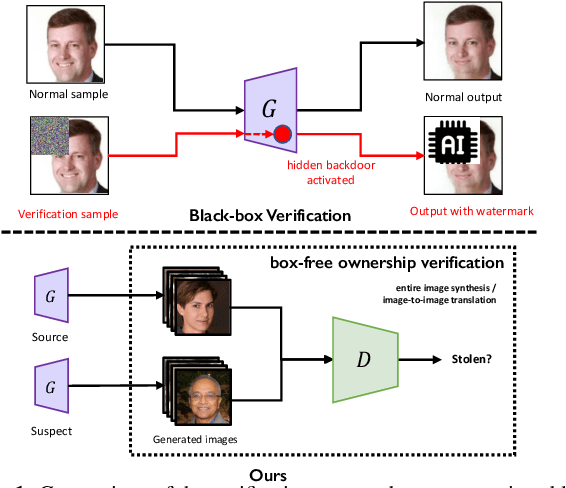
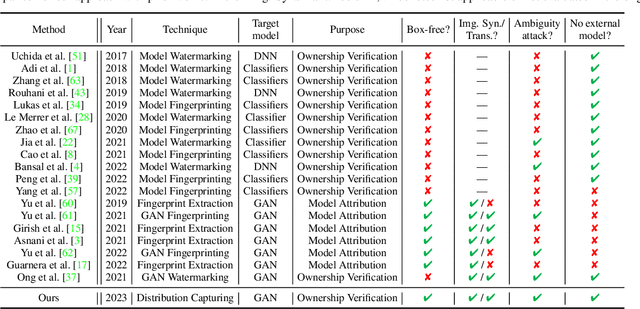
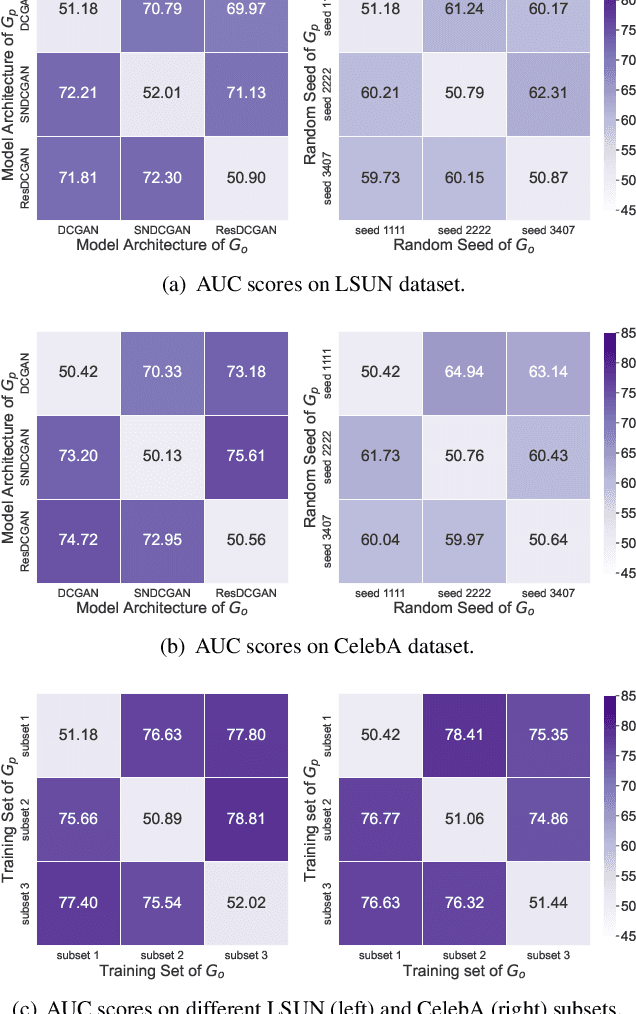

In recent decades, Generative Adversarial Network (GAN) and its variants have achieved unprecedented success in image synthesis. However, well-trained GANs are under the threat of illegal steal or leakage. The prior studies on remote ownership verification assume a black-box setting where the defender can query the suspicious model with specific inputs, which we identify is not enough for generation tasks. To this end, in this paper, we propose a novel IP protection scheme for GANs where ownership verification can be done by checking outputs only, without choosing the inputs (i.e., box-free setting). Specifically, we make use of the unexploited potential of the discriminator to learn a hypersphere that captures the unique distribution learned by the paired generator. Extensive evaluations on two popular GAN tasks and more than 10 GAN architectures demonstrate our proposed scheme to effectively verify the ownership. Our proposed scheme shown to be immune to popular input-based removal attacks and robust against other existing attacks. The source code and models are available at https://github.com/AbstractTeen/gan_ownership_verification
Efficient and Low Overhead Website Fingerprinting Attacks and Defenses based on TCP/IP Traffic
Feb 27, 2023

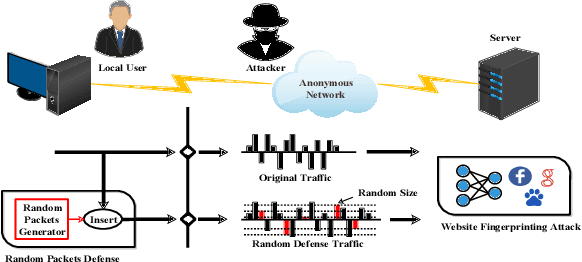

Website fingerprinting attack is an extensively studied technique used in a web browser to analyze traffic patterns and thus infer confidential information about users. Several website fingerprinting attacks based on machine learning and deep learning tend to use the most typical features to achieve a satisfactory performance of attacking rate. However, these attacks suffer from several practical implementation factors, such as a skillfully pre-processing step or a clean dataset. To defend against such attacks, random packet defense (RPD) with a high cost of excessive network overhead is usually applied. In this work, we first propose a practical filter-assisted attack against RPD, which can filter out the injected noises using the statistical characteristics of TCP/IP traffic. Then, we propose a list-assisted defensive mechanism to defend the proposed attack method. To achieve a configurable trade-off between the defense and the network overhead, we further improve the list-based defense by a traffic splitting mechanism, which can combat the mentioned attacks as well as save a considerable amount of network overhead. In the experiments, we collect real-life traffic patterns using three mainstream browsers, i.e., Microsoft Edge, Google Chrome, and Mozilla Firefox, and extensive results conducted on the closed and open-world datasets show the effectiveness of the proposed algorithms in terms of defense accuracy and network efficiency.
Cluster-guided Contrastive Graph Clustering Network
Jan 03, 2023


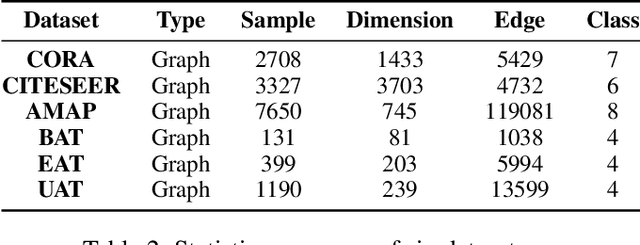
Benefiting from the intrinsic supervision information exploitation capability, contrastive learning has achieved promising performance in the field of deep graph clustering recently. However, we observe that two drawbacks of the positive and negative sample construction mechanisms limit the performance of existing algorithms from further improvement. 1) The quality of positive samples heavily depends on the carefully designed data augmentations, while inappropriate data augmentations would easily lead to the semantic drift and indiscriminative positive samples. 2) The constructed negative samples are not reliable for ignoring important clustering information. To solve these problems, we propose a Cluster-guided Contrastive deep Graph Clustering network (CCGC) by mining the intrinsic supervision information in the high-confidence clustering results. Specifically, instead of conducting complex node or edge perturbation, we construct two views of the graph by designing special Siamese encoders whose weights are not shared between the sibling sub-networks. Then, guided by the high-confidence clustering information, we carefully select and construct the positive samples from the same high-confidence cluster in two views. Moreover, to construct semantic meaningful negative sample pairs, we regard the centers of different high-confidence clusters as negative samples, thus improving the discriminative capability and reliability of the constructed sample pairs. Lastly, we design an objective function to pull close the samples from the same cluster while pushing away those from other clusters by maximizing and minimizing the cross-view cosine similarity between positive and negative samples. Extensive experimental results on six datasets demonstrate the effectiveness of CCGC compared with the existing state-of-the-art algorithms.