 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hypertoroidal Covering for Perfect Color Equivariance
Mar 04, 2026When the color distribution of input images changes at inference, the performance of conventional neural network architectures drops considerably. A few researchers have begun to incorporate prior knowledge of color geometry in neural network design. These color equivariant architectures have modeled hue variation with 2D rotations, and saturation and luminance transformations as 1D translations. While this approach improves neural network robustness to color variations in a number of contexts, we find that approximating saturation and luminance (interval valued quantities) as 1D translations introduces appreciable artifacts. In this paper, we introduce a color equivariant architecture that is truly equivariant. Instead of approximating the interval with the real line, we lift values on the interval to values on the circle (a double-cover) and build equivariant representations there. Our approach resolves the approximation artifacts of previous methods, improves interpretability and generalizability, and achieves better predictive performance than conventional and equivariant baselines on tasks such as fine-grained classification and medical imaging tasks. Going beyond the context of color, we show that our proposed lifting can also extend to geometric transformations such as scale.
The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
Understanding Oversmoothing in GNNs as Consensus in Opinion Dynamics
Jan 31, 2025In contrast to classes of neural networks where the learned representations become increasingly expressive with network depth, the learned representations in graph neural networks (GNNs), tend to become increasingly similar. This phenomena, known as oversmoothing, is characterized by learned representations that cannot be reliably differentiated leading to reduced predictive performance. In this paper, we propose an analogy between oversmoothing in GNNs and consensus or agreement in opinion dynamics. Through this analogy, we show that the message passing structure of recent continuous-depth GNNs is equivalent to a special case of opinion dynamics (i.e., linear consensus models) which has been theoretically proven to converge to consensus (i.e., oversmoothing) for all inputs. Using the understanding developed through this analogy, we design a new continuous-depth GNN model based on nonlinear opinion dynamics and prove that our model, which we call behavior-inspired message passing neural network (BIMP) circumvents oversmoothing for general inputs. Through extensive experiments, we show that BIMP is robust to oversmoothing and adversarial attack, and consistently outperforms competitive baselines on numerous benchmarks.
Relational Reasoning On Graphs Using Opinion Dynamics
Jun 20, 2024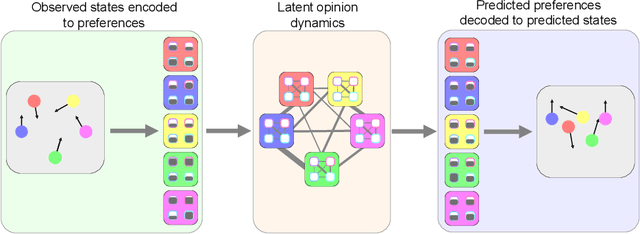


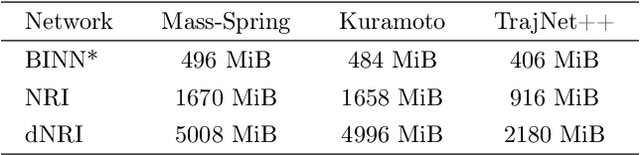
From pedestrians to Kuramoto oscillators, interactions between agents govern how a multitude of dynamical systems evolve in space and time. Discovering how these agents relate to each other can improve our understanding of the often complex dynamics that underlie these systems. Recent works learn to categorize relationships between agents based on observations of their physical behavior. These approaches are limited in that the relationship categories are modelled as independent and mutually exclusive, when in real world systems categories are often interacting. In this work, we introduce a level of abstraction between the physical behavior of agents and the categories that define their behavior. To do this, we learn a mapping from the agents' states to their affinities for each category in a graph neural network. We integrate the physical proximity of agents and their affinities in a nonlinear opinion dynamics model which provides a mechanism to identify mutually exclusive categories, predict an agent's evolution in time, and control an agent's behavior. We demonstrate the utility of our model for learning interpretable categories for mechanical systems, and demonstrate its efficacy on several long-horizon trajectory prediction benchmarks where we consistently out perform existing methods.
Color Equivariant Network
Jun 13, 2024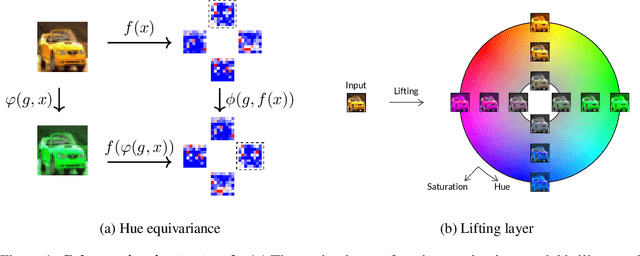

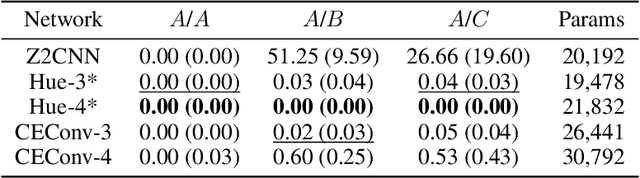
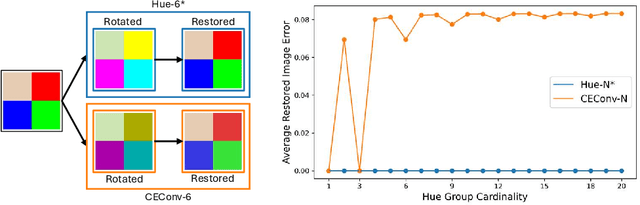
Group equivariant convolutional neural networks have been designed for a variety of geometric transformations from 2D and 3D rotation groups, to semi-groups such as scale. Despite the improved interpretability, accuracy and generalizability afforded by these architectures, group equivariant networks have seen limited application in the context of perceptual quantities such as hue and saturation, even though their variation can lead to significant reductions in classification performance. In this paper, we introduce convolutional neural networks equivariant to variations in hue and saturation by design. To achieve this, we leverage the observation that hue and saturation transformations can be identified with the 2D rotation and 1D translation groups respectively. Our hue-, saturation-, and fully color-equivariant networks achieve equivariance to these perceptual transformations without an increase in network parameters. We demonstrate the utility of our networks on synthetic and real world datasets where color and lighting variations are commonplace.
Towards Deep Learning Models Resistant to Transfer-based Adversarial Attacks via Data-centric Robust Learning
Oct 15, 2023Transfer-based adversarial attacks raise a severe threat to real-world deep learning systems since they do not require access to target models. Adversarial training (AT), which is recognized as the strongest defense against white-box attacks, has also guaranteed high robustness to (black-box) transfer-based attacks. However, AT suffers from heavy computational overhead since it optimizes the adversarial examples during the whole training process. In this paper, we demonstrate that such heavy optimization is not necessary for AT against transfer-based attacks. Instead, a one-shot adversarial augmentation prior to training is sufficient, and we name this new defense paradigm Data-centric Robust Learning (DRL). Our experimental results show that DRL outperforms widely-used AT techniques (e.g., PGD-AT, TRADES, EAT, and FAT) in terms of black-box robustness and even surpasses the top-1 defense on RobustBench when combined with diverse data augmentations and loss regularizations. We also identify other benefits of DRL, for instance, the model generalization capability and robust fairness.
Hard Adversarial Example Mining for Improving Robust Fairness
Aug 03, 2023



Adversarial training (AT) is widely considered the state-of-the-art technique for improving the robustness of deep neural networks (DNNs) against adversarial examples (AE). Nevertheless, recent studies have revealed that adversarially trained models are prone to unfairness problems, restricting their applicability. In this paper, we empirically observe that this limitation may be attributed to serious adversarial confidence overfitting, i.e., certain adversarial examples with overconfidence. To alleviate this problem, we propose HAM, a straightforward yet effective framework via adaptive Hard Adversarial example Mining.HAM concentrates on mining hard adversarial examples while discarding the easy ones in an adaptive fashion. Specifically, HAM identifies hard AEs in terms of their step sizes needed to cross the decision boundary when calculating loss value. Besides, an early-dropping mechanism is incorporated to discard the easy examples at the initial stages of AE generation, resulting in efficient AT. Extensive experimental results on CIFAR-10, SVHN, and Imagenette demonstrate that HAM achieves significant improvement in robust fairness while reducing computational cost compared to several state-of-the-art adversarial training methods. The code will be made publicly available.