 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoBrain: Learning Adaptive Frame Sampling for Long Video Understanding
Feb 04, 2026Long-form video understanding remains challenging for Vision-Language Models (VLMs) due to the inherent tension between computational constraints and the need to capture information distributed across thousands of frames. Existing approaches either sample frames uniformly (risking information loss) or select keyframes in a single pass (with no recovery from poor choices). We propose VideoBrain, an end-to-end framework that enables VLMs to adaptively acquire visual information through learned sampling policies. Our approach features dual complementary agents: a CLIP-based agent for semantic retrieval across the video and a Uniform agent for dense temporal sampling within intervals. Unlike prior agent-based methods that rely on text-only LLMs orchestrating visual tools, our VLM directly perceives frames and reasons about information sufficiency. To prevent models from invoking agents indiscriminately to maximize rewards, we introduce a behavior-aware reward function coupled with a data classification pipeline that teaches the model when agent invocation is genuinely beneficial. Experiments on four long video benchmarks demonstrate that VideoBrain achieves +3.5% to +9.0% improvement over the baseline while using 30-40% fewer frames, with strong cross-dataset generalization to short video benchmarks.
CoMA: Compositional Human Motion Generation with Multi-modal Agents
Dec 10, 2024



3D human motion generation has seen substantial advancement in recent years. While state-of-the-art approaches have improved performance significantly, they still struggle with complex and detailed motions unseen in training data, largely due to the scarcity of motion datasets and the prohibitive cost of generating new training examples. To address these challenges, we introduce CoMA, an agent-based solution for complex human motion generation, editing, and comprehension. CoMA leverages multiple collaborative agents powered by large language and vision models, alongside a mask transformer-based motion generator featuring body part-specific encoders and codebooks for fine-grained control. Our framework enables generation of both short and long motion sequences with detailed instructions, text-guided motion editing, and self-correction for improved quality. Evaluations on the HumanML3D dataset demonstrate competitive performance against state-of-the-art methods. Additionally, we create a set of context-rich, compositional, and long text prompts, where user studies show our method significantly outperforms existing approaches.
What can Discriminator do? Towards Box-free Ownership Verification of Generative Adversarial Network
Jul 29, 2023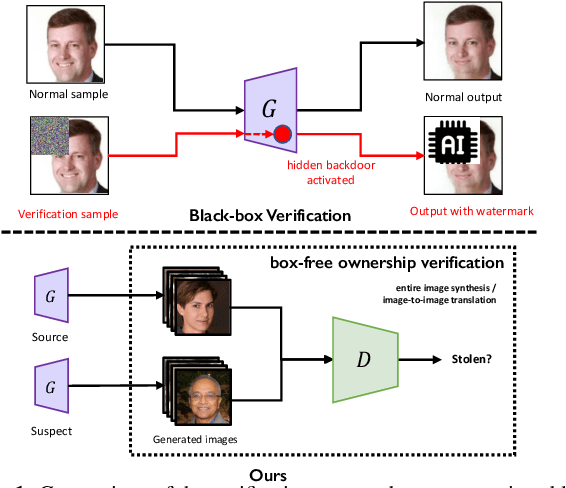
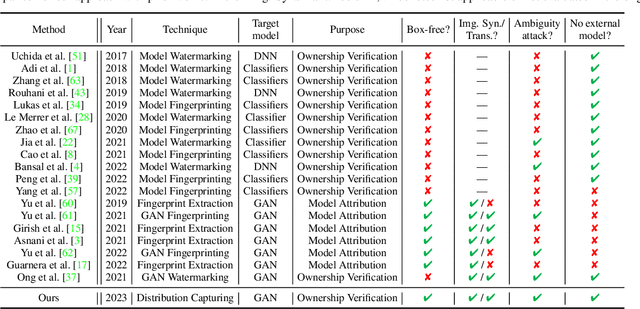
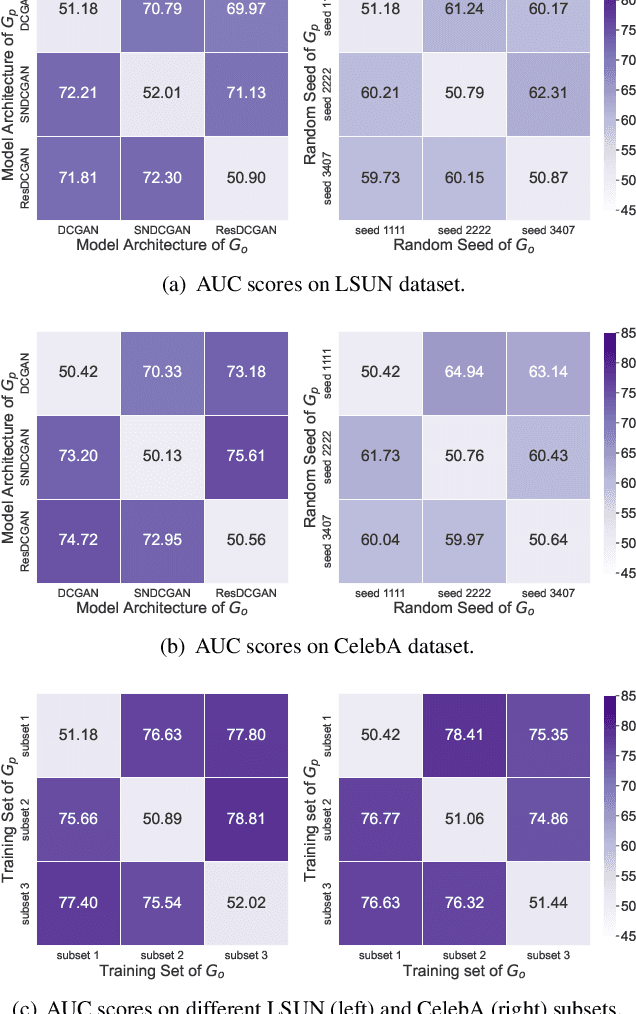

In recent decades, Generative Adversarial Network (GAN) and its variants have achieved unprecedented success in image synthesis. However, well-trained GANs are under the threat of illegal steal or leakage. The prior studies on remote ownership verification assume a black-box setting where the defender can query the suspicious model with specific inputs, which we identify is not enough for generation tasks. To this end, in this paper, we propose a novel IP protection scheme for GANs where ownership verification can be done by checking outputs only, without choosing the inputs (i.e., box-free setting). Specifically, we make use of the unexploited potential of the discriminator to learn a hypersphere that captures the unique distribution learned by the paired generator. Extensive evaluations on two popular GAN tasks and more than 10 GAN architectures demonstrate our proposed scheme to effectively verify the ownership. Our proposed scheme shown to be immune to popular input-based removal attacks and robust against other existing attacks. The source code and models are available at https://github.com/AbstractTeen/gan_ownership_verification