 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceScope: Interactive URL Triage via Decoupled Checklist Adjudication
Apr 23, 2026Modern phishing campaigns increasingly evade snapshot-based URL classifiers using interaction gates (e.g., checkbox/slider challenges), delayed content rendering, and logo-less credential harvesters. This shifts URL triage from static classification toward an interactive forensics task: an analyst must actively navigate the page while isolating themselves from potential runtime exploits. We present TraceScope, a decoupled triage pipeline that operationalizes this workflow at scale. To prevent the observer effect and ensure safety, a sandboxed operator agent drives a real GUI browser guided by visual motivation to elicit page behavior, freezing the session into an immutable evidence bundle. Separately, an adjudicator agent circumvents LLM context limitations by querying evidence on demand to verify a MITRE ATT&CK checklist, and generates an audit-ready report with extracted indicators of compromise (IOCs) and a final verdict. Evaluated on 708 reachable URLs from existing dataset (241 verified phishing from PhishTank and 467 benign from Tranco-derived crawling), TraceScope achieves 0.94 precision and 0.78 recall, substantially improving recall over three prior visual/reference-based classifiers while producing reproducible, analyst-grade evidence suitable for review. More importantly, we manually curated a dataset of real-world phishing emails to evaluate our system in a practical setting. Our evaluation reveals that TraceScope demonstrates superior performance in a real-world scenario as well, successfully detecting sophisticated phishing attempts that current state-of-the-art defenses fail to identify.
A Systematic Taxonomy of Security Vulnerabilities in the OpenClaw AI Agent Framework
Mar 29, 2026AI agent frameworks connecting large language model (LLM) reasoning to host execution surfaces--shell, filesystem, containers, and messaging--introduce security challenges structurally distinct from conventional software. We present a systematic taxonomy of 190 advisories filed against OpenClaw, an open-source AI agent runtime, organized by architectural layer and trust-violation type. Vulnerabilities cluster along two orthogonal axes: (1) the system axis, reflecting the architectural layer (exec policy, gateway, channel, sandbox, browser, plugin, agent/prompt); and (2) the attack axis, reflecting adversarial techniques (identity spoofing, policy bypass, cross-layer composition, prompt injection, supply-chain escalation). Patch-differential evidence yields three principal findings. First, three Moderate- or High-severity advisories in the Gateway and Node-Host subsystems compose into a complete unauthenticated remote code execution (RCE) path--spanning delivery, exploitation, and command-and-control--from an LLM tool call to the host process. Second, the exec allowlist, the primary command-filtering mechanism, relies on a closed-world assumption that command identity is recoverable via lexical parsing. This is invalidated by shell line continuation, busybox multiplexing, and GNU option abbreviation. Third, a malicious skill distributed via the plugin channel executed a two-stage dropper within the LLM context, bypassing the exec pipeline and demonstrating that the skill distribution surface lacks runtime policy enforcement. The dominant structural weakness is per-layer trust enforcement rather than unified policy boundaries, making cross-layer attacks resilient to local remediation.
LLMs in Software Security: A Survey of Vulnerability Detection Techniques and Insights
Feb 12, 2025Large Language Models (LLMs) are emerging as transformative tools for software vulnerability detection, addressing critical challenges in the security domain. Traditional methods, such as static and dynamic analysis, often falter due to inefficiencies, high false positive rates, and the growing complexity of modern software systems. By leveraging their ability to analyze code structures, identify patterns, and generate repair sugges- tions, LLMs, exemplified by models like GPT, BERT, and CodeBERT, present a novel and scalable approach to mitigating vulnerabilities. This paper provides a detailed survey of LLMs in vulnerability detection. It examines key aspects, including model architectures, application methods, target languages, fine-tuning strategies, datasets, and evaluation metrics. We also analyze the scope of current research problems, highlighting the strengths and weaknesses of existing approaches. Further, we address challenges such as cross-language vulnerability detection, multimodal data integration, and repository-level analysis. Based on these findings, we propose solutions for issues like dataset scalability, model interpretability, and applications in low-resource scenarios. Our contributions are threefold: (1) a systematic review of how LLMs are applied in vulnerability detection; (2) an analysis of shared patterns and differences across studies, with a unified framework for understanding the field; and (3) a summary of key challenges and future research directions. This work provides valuable insights for advancing LLM-based vulnerability detection. We also maintain and regularly update latest selected paper on https://github.com/OwenSanzas/LLM-For-Vulnerability-Detection
Large Language Models in Software Security: A Survey of Vulnerability Detection Techniques and Insights
Feb 10, 2025Large Language Models (LLMs) are emerging as transformative tools for software vulnerability detection, addressing critical challenges in the security domain. Traditional methods, such as static and dynamic analysis, often falter due to inefficiencies, high false positive rates, and the growing complexity of modern software systems. By leveraging their ability to analyze code structures, identify patterns, and generate repair sugges- tions, LLMs, exemplified by models like GPT, BERT, and CodeBERT, present a novel and scalable approach to mitigating vulnerabilities. This paper provides a detailed survey of LLMs in vulnerability detection. It examines key aspects, including model architectures, application methods, target languages, fine-tuning strategies, datasets, and evaluation metrics. We also analyze the scope of current research problems, highlighting the strengths and weaknesses of existing approaches. Further, we address challenges such as cross-language vulnerability detection, multimodal data integration, and repository-level analysis. Based on these findings, we propose solutions for issues like dataset scalability, model interpretability, and applications in low-resource scenarios. Our contributions are threefold: (1) a systematic review of how LLMs are applied in vulnerability detection; (2) an analysis of shared patterns and differences across studies, with a unified framework for understanding the field; and (3) a summary of key challenges and future research directions. This work provides valuable insights for advancing LLM-based vulnerability detection. We also maintain and regularly update latest selected paper on https://github.com/OwenSanzas/LLM-For-Vulnerability-Detection
ExAD: An Ensemble Approach for Explanation-based Adversarial Detection
Mar 22, 2021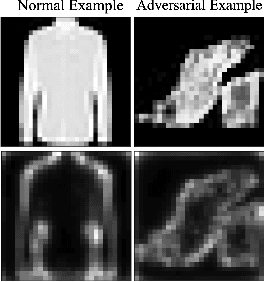
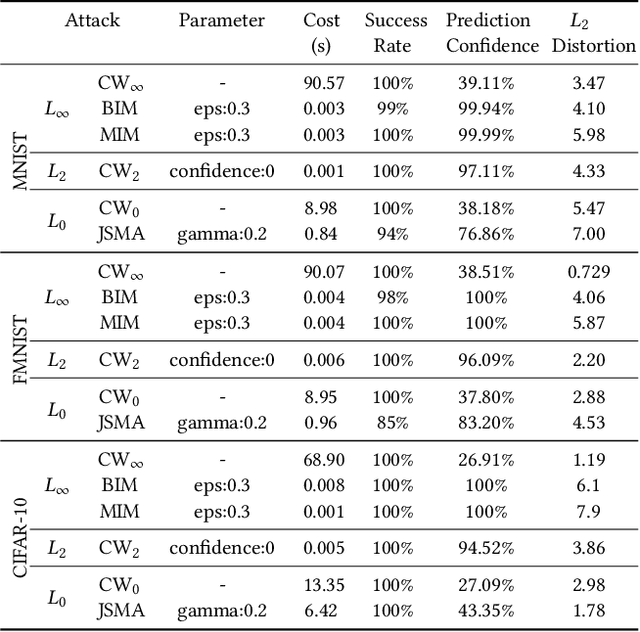
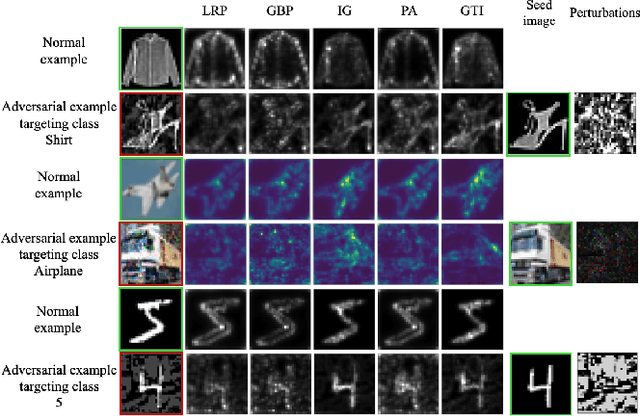
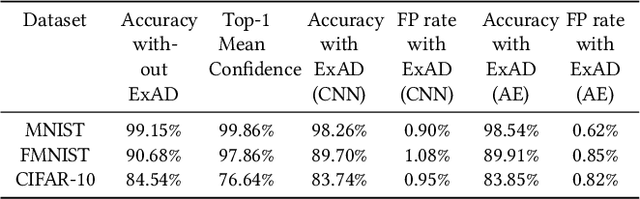
Recent research has shown Deep Neural Networks (DNNs) to be vulnerable to adversarial examples that induce desired misclassifications in the models. Such risks impede the application of machine learning in security-sensitive domains. Several defense methods have been proposed against adversarial attacks to detect adversarial examples at test time or to make machine learning models more robust. However, while existing methods are quite effective under blackbox threat model, where the attacker is not aware of the defense, they are relatively ineffective under whitebox threat model, where the attacker has full knowledge of the defense. In this paper, we propose ExAD, a framework to detect adversarial examples using an ensemble of explanation techniques. Each explanation technique in ExAD produces an explanation map identifying the relevance of input variables for the model's classification. For every class in a dataset, the system includes a detector network, corresponding to each explanation technique, which is trained to distinguish between normal and abnormal explanation maps. At test time, if the explanation map of an input is detected as abnormal by any detector model of the classified class, then we consider the input to be an adversarial example. We evaluate our approach using six state-of-the-art adversarial attacks on three image datasets. Our extensive evaluation shows that our mechanism can effectively detect these attacks under blackbox threat model with limited false-positives. Furthermore, we find that our approach achieves promising results in limiting the success rate of whitebox attacks.
Practical Speech Re-use Prevention in Voice-driven Services
Jan 12, 2021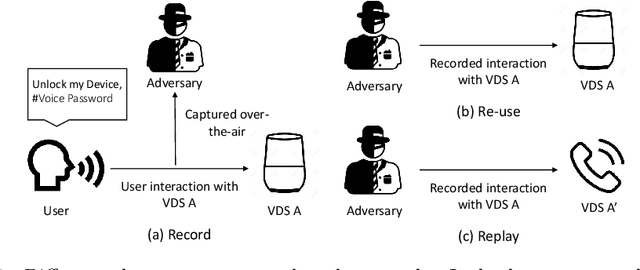



Voice-driven services (VDS) are being used in a variety of applications ranging from smart home control to payments using digital assistants. The input to such services is often captured via an open voice channel, e.g., using a microphone, in an unsupervised setting. One of the key operational security requirements in such setting is the freshness of the input speech. We present AEOLUS, a security overlay that proactively embeds a dynamic acoustic nonce at the time of user interaction, and detects the presence of the embedded nonce in the recorded speech to ensure freshness. We demonstrate that acoustic nonce can (i) be reliably embedded and retrieved, and (ii) be non-disruptive (and even imperceptible) to a VDS user. Optimal parameters (acoustic nonce's operating frequency, amplitude, and bitrate) are determined for (i) and (ii) from a practical perspective. Experimental results show that AEOLUS yields 0.5% FRR at 0% FAR for speech re-use prevention upto a distance of 4 meters in three real-world environments with different background noise levels. We also conduct a user study with 120 participants, which shows that the acoustic nonce does not degrade overall user experience for 94.16% of speech samples, on average, in these environments. AEOLUS can therefore be used in practice to prevent speech re-use and ensure the freshness of speech input.