 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Data Poisoning in Code Generation LLMs via Black-Box, Vulnerability-Oriented Scanning
Mar 17, 2026Code generation large language models (LLMs) are increasingly integrated into modern software development workflows. Recent work has shown that these models are vulnerable to backdoor and poisoning attacks that induce the generation of insecure code, yet effective defenses remain limited. Existing scanning approaches rely on token-level generation consistency to invert attack targets, which is ineffective for source code where identical semantics can appear in diverse syntactic forms. We present CodeScan, which, to the best of our knowledge, is the first poisoning-scanning framework tailored to code generation models. CodeScan identifies attack targets by analyzing structural similarities across multiple generations conditioned on different clean prompts. It combines iterative divergence analysis with abstract syntax tree (AST)-based normalization to abstract away surface-level variation and unify semantically equivalent code, isolating structures that recur consistently across generations. CodeScan then applies LLM-based vulnerability analysis to determine whether the extracted structures contain security vulnerabilities and flags the model as compromised when such a structure is found. We evaluate CodeScan against four representative attacks under both backdoor and poisoning settings across three real-world vulnerability classes. Experiments on 108 models spanning three architectures and multiple model sizes demonstrate 97%+ detection accuracy with substantially lower false positives than prior methods.
Compact: Approximating Complex Activation Functions for Secure Computation
Sep 09, 2023



Secure multi-party computation (MPC) techniques can be used to provide data privacy when users query deep neural network (DNN) models hosted on a public cloud. State-of-the-art MPC techniques can be directly leveraged for DNN models that use simple activation functions (AFs) such as ReLU. However, DNN model architectures designed for cutting-edge applications often use complex and highly non-linear AFs. Designing efficient MPC techniques for such complex AFs is an open problem. Towards this, we propose Compact, which produces piece-wise polynomial approximations of complex AFs to enable their efficient use with state-of-the-art MPC techniques. Compact neither requires nor imposes any restriction on model training and results in near-identical model accuracy. We extensively evaluate Compact on four different machine-learning tasks with DNN architectures that use popular complex AFs SiLU, GeLU, and Mish. Our experimental results show that Compact incurs negligible accuracy loss compared to DNN-specific approaches for handling complex non-linear AFs. We also incorporate Compact in two state-of-the-art MPC libraries for privacy-preserving inference and demonstrate that Compact provides 2x-5x speedup in computation compared to the state-of-the-art approximation approach for non-linear functions -- while providing similar or better accuracy for DNN models with large number of hidden layers
Practical Speech Re-use Prevention in Voice-driven Services
Jan 12, 2021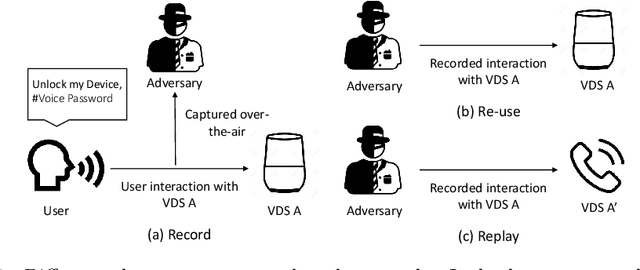



Voice-driven services (VDS) are being used in a variety of applications ranging from smart home control to payments using digital assistants. The input to such services is often captured via an open voice channel, e.g., using a microphone, in an unsupervised setting. One of the key operational security requirements in such setting is the freshness of the input speech. We present AEOLUS, a security overlay that proactively embeds a dynamic acoustic nonce at the time of user interaction, and detects the presence of the embedded nonce in the recorded speech to ensure freshness. We demonstrate that acoustic nonce can (i) be reliably embedded and retrieved, and (ii) be non-disruptive (and even imperceptible) to a VDS user. Optimal parameters (acoustic nonce's operating frequency, amplitude, and bitrate) are determined for (i) and (ii) from a practical perspective. Experimental results show that AEOLUS yields 0.5% FRR at 0% FAR for speech re-use prevention upto a distance of 4 meters in three real-world environments with different background noise levels. We also conduct a user study with 120 participants, which shows that the acoustic nonce does not degrade overall user experience for 94.16% of speech samples, on average, in these environments. AEOLUS can therefore be used in practice to prevent speech re-use and ensure the freshness of speech input.
Beating Attackers At Their Own Games: Adversarial Example Detection Using Adversarial Gradient Directions
Dec 31, 2020

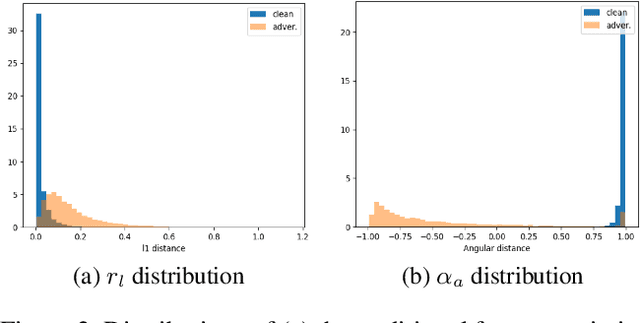

Adversarial examples are input examples that are specifically crafted to deceive machine learning classifiers. State-of-the-art adversarial example detection methods characterize an input example as adversarial either by quantifying the magnitude of feature variations under multiple perturbations or by measuring its distance from estimated benign example distribution. Instead of using such metrics, the proposed method is based on the observation that the directions of adversarial gradients when crafting (new) adversarial examples play a key role in characterizing the adversarial space. Compared to detection methods that use multiple perturbations, the proposed method is efficient as it only applies a single random perturbation on the input example. Experiments conducted on two different databases, CIFAR-10 and ImageNet, show that the proposed detection method achieves, respectively, 97.9% and 98.6% AUC-ROC (on average) on five different adversarial attacks, and outperforms multiple state-of-the-art detection methods. Results demonstrate the effectiveness of using adversarial gradient directions for adversarial example detection.
Adversarial Light Projection Attacks on Face Recognition Systems: A Feasibility Study
Apr 17, 2020
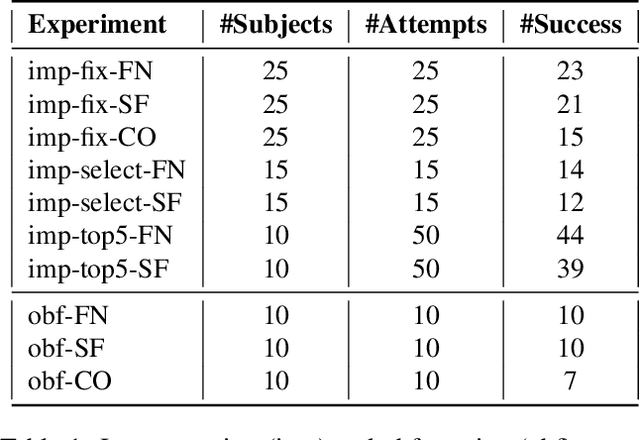

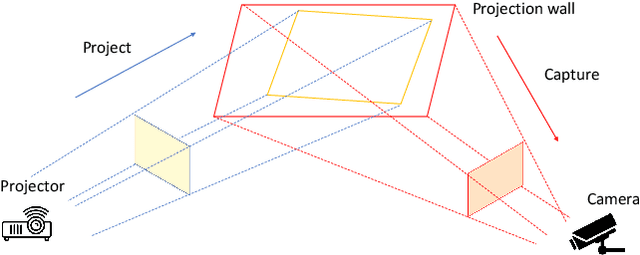
Deep learning-based systems have been shown to be vulnerable to adversarial attacks in both digital and physical domains. While feasible, digital attacks have limited applicability in attacking deployed systems, including face recognition systems, where an adversary typically has access to the input and not the transmission channel. In such setting, physical attacks that directly provide a malicious input through the input channel pose a bigger threat. We investigate the feasibility of conducting real-time physical attacks on face recognition systems using adversarial light projections. A setup comprising a commercially available web camera and a projector is used to conduct the attack. The adversary uses a transformation-invariant adversarial pattern generation method to generate a digital adversarial pattern using one or more images of the target available to the adversary. The digital adversarial pattern is then projected onto the adversary's face in the physical domain to either impersonate a target (impersonation) or evade recognition (obfuscation). We conduct preliminary experiments using two open-source and one commercial face recognition system on a pool of 50 subjects. Our experimental results demonstrate the vulnerability of face recognition systems to light projection attacks in both white-box and black-box attack settings.
DashCam Pay: A System for In-vehicle Payments Using Face and Voice
Apr 08, 2020
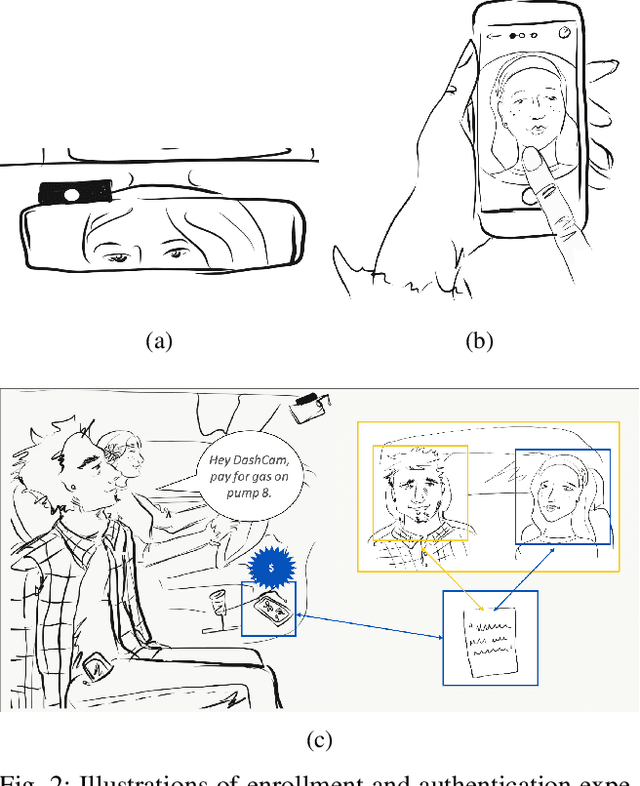

We present an open loop system, called DashCam Pay, that enables in-vehicle payments using face and voice biometrics. The system uses a plug-and-play device (dashcam) mounted in the vehicle to capture face images and voice commands of passengers. The dashcam is connected to mobile devices of passengers sitting in the vehicle, and uses privacy-preserving biometric comparison techniques to compare the biometric data captured by the dashcam with the biometric data enrolled on the users' mobile devices to determine the payer. Once the payer is verified, payment is initiated via the mobile device of the payer. For initial feasibility analysis, we collected data from 20 different subjects at two different sites using a commercially available dashcam, and evaluated open-source biometric algorithms on the collected data. Subsequently, we built an android prototype of the proposed system using open-source software packages to demonstrate the utility of the proposed system in facilitating secure in-vehicle payments. DashCam Pay can be integrated either by dashcam or vehicle manufacturers to enable open loop in-vehicle payments. We also discuss the applicability of the system to other payments scenarios, such as in-store payments.
Universal 3D Wearable Fingerprint Targets: Advancing Fingerprint Reader Evaluations
May 22, 2017
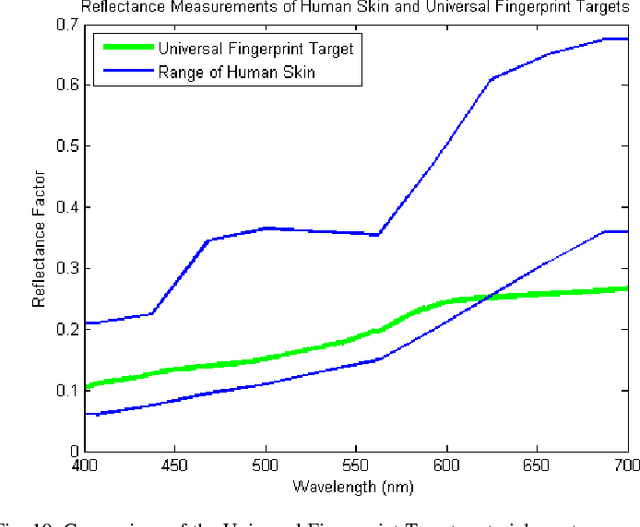


We present the design and manufacturing of high fidelity universal 3D fingerprint targets, which can be imaged on a variety of fingerprint sensing technologies, namely capacitive, contact-optical, and contactless-optical. Universal 3D fingerprint targets enable, for the first time, not only a repeatable and controlled evaluation of fingerprint readers, but also the ability to conduct fingerprint reader interoperability studies. Fingerprint reader interoperability refers to how robust fingerprint recognition systems are to variations in the images acquired by different types of fingerprint readers. To build universal 3D fingerprint targets, we adopt a molding and casting framework consisting of (i) digital mapping of fingerprint images to a negative mold, (ii) CAD modeling a scaffolding system to hold the negative mold, (iii) fabricating the mold and scaffolding system with a high resolution 3D printer, (iv) producing or mixing a material with similar electrical, optical, and mechanical properties to that of the human finger, and (v) fabricating a 3D fingerprint target using controlled casting. Our experiments conducted with PIV and Appendix F certified optical (contact and contactless) and capacitive fingerprint readers demonstrate the usefulness of universal 3D fingerprint targets for controlled and repeatable fingerprint reader evaluations and also fingerprint reader interoperability studies.
Biometrics for Child Vaccination and Welfare: Persistence of Fingerprint Recognition for Infants and Toddlers
Apr 17, 2015
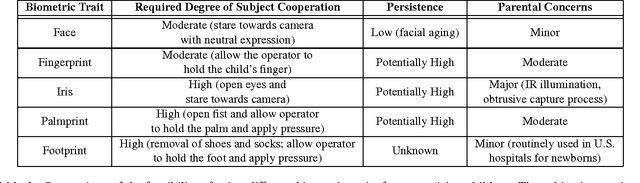

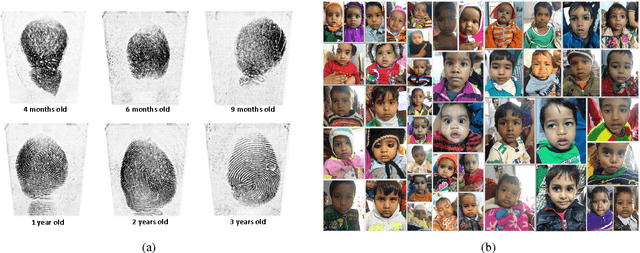
With a number of emerging applications requiring biometric recognition of children (e.g., tracking child vaccination schedules, identifying missing children and preventing newborn baby swaps in hospitals), investigating the temporal stability of biometric recognition accuracy for children is important. The persistence of recognition accuracy of three of the most commonly used biometric traits (fingerprints, face and iris) has been investigated for adults. However, persistence of biometric recognition accuracy has not been studied systematically for children in the age group of 0-4 years. Given that very young children are often uncooperative and do not comprehend or follow instructions, in our opinion, among all biometric modalities, fingerprints are the most viable for recognizing children. This is primarily because it is easier to capture fingerprints of young children compared to other biometric traits, e.g., iris, where a child needs to stare directly towards the camera to initiate iris capture. In this report, we detail our initiative to investigate the persistence of fingerprint recognition for children in the age group of 0-4 years. Based on preliminary results obtained for the data collected in the first phase of our study, use of fingerprints for recognition of 0-4 year-old children appears promising.