 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVC-LLM: Automated Advertisement Video Creation from Raw Footage using Multi-modal LLMs
Apr 08, 2025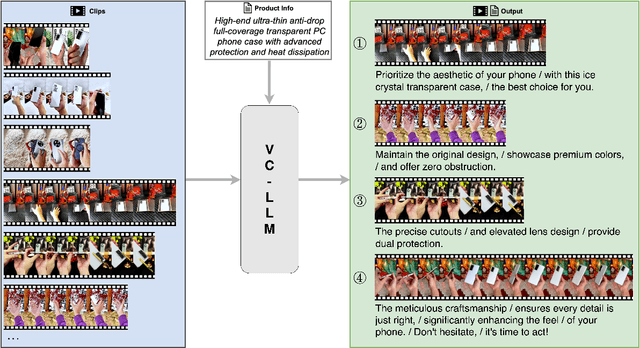
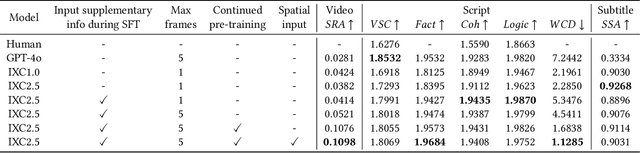
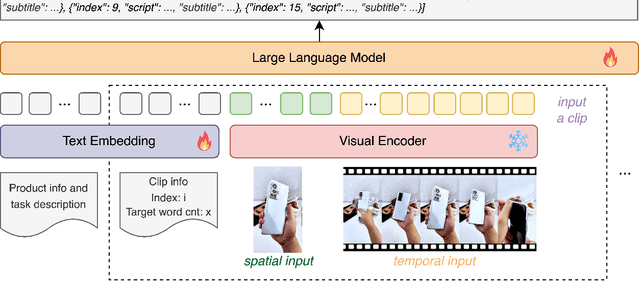

As short videos have risen in popularity, the role of video content in advertising has become increasingly significant. Typically, advertisers record a large amount of raw footage about the product and then create numerous different short-form advertisement videos based on this raw footage. Creating such videos mainly involves editing raw footage and writing advertisement scripts, which requires a certain level of creative ability. It is usually challenging to create many different video contents for the same product, and manual efficiency is often low. In this paper, we present VC-LLM, a framework powered by Large Language Models for the automatic creation of high-quality short-form advertisement videos. Our approach leverages high-resolution spatial input and low-resolution temporal input to represent video clips more effectively, capturing both fine-grained visual details and broader temporal dynamics. In addition, during training, we incorporate supplementary information generated by rewriting the ground truth text, ensuring that all key output information can be directly traced back to the input, thereby reducing model hallucinations. We also designed a benchmark to evaluate the quality of the created videos. Experiments show that VC-LLM based on GPT-4o can produce videos comparable to those created by humans. Furthermore, we collected numerous high-quality short advertisement videos to create a pre-training dataset and manually cleaned a portion of the data to construct a high-quality fine-tuning dataset. Experiments indicate that, on the benchmark, the VC-LLM based on fine-tuned LLM can produce videos with superior narrative logic compared to those created by the VC-LLM based on GPT-4o.