 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn overview on the evaluated video retrieval tasks at TRECVID 2022
Jun 22, 2023



The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, tasks-based evaluation supported by metrology. Over the last twenty-one years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2022 planned for the following six tasks: Ad-hoc video search, Video to text captioning, Disaster scene description and indexing, Activity in extended videos, deep video understanding, and movie summarization. In total, 35 teams from various research organizations worldwide signed up to join the evaluation campaign this year. This paper introduces the tasks, datasets used, evaluation frameworks and metrics, as well as a high-level results overview.
TRECVID 2020: A comprehensive campaign for evaluating video retrieval tasks across multiple application domains
Apr 27, 2021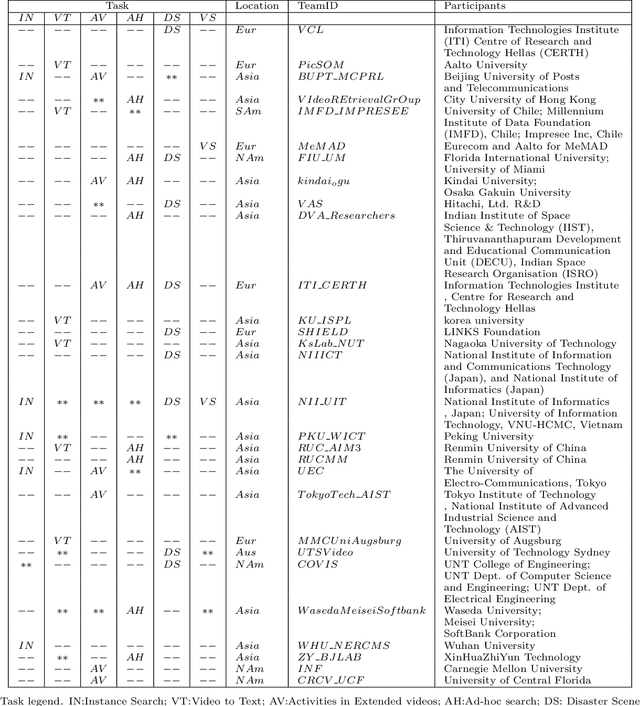

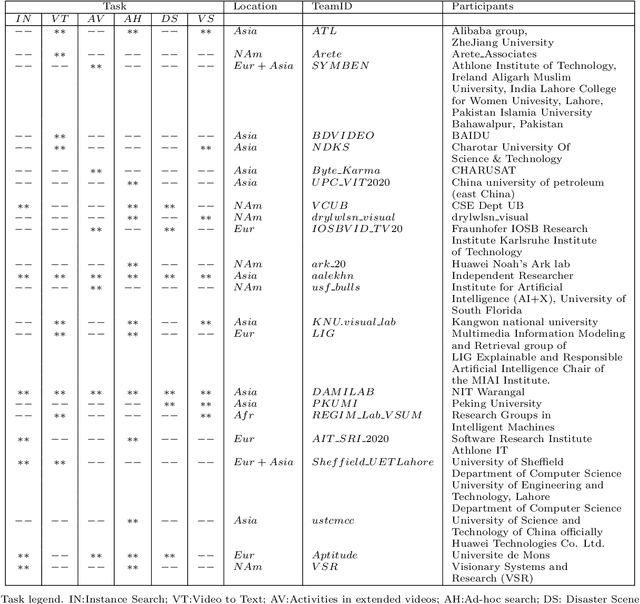
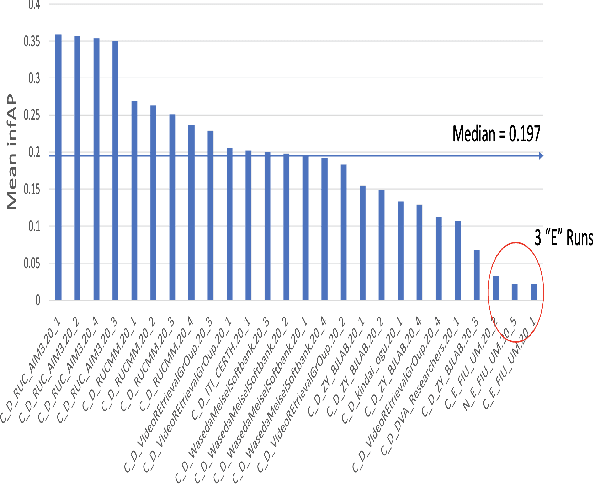
The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, metrics-based evaluation. Over the last twenty years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2020 represented a continuation of four tasks and the addition of two new tasks. In total, 29 teams from various research organizations worldwide completed one or more of the following six tasks: 1. Ad-hoc Video Search (AVS), 2. Instance Search (INS), 3. Disaster Scene Description and Indexing (DSDI), 4. Video to Text Description (VTT), 5. Activities in Extended Video (ActEV), 6. Video Summarization (VSUM). This paper is an introduction to the evaluation framework, tasks, data, and measures used in the evaluation campaign.
TRECVID 2019: An Evaluation Campaign to Benchmark Video Activity Detection, Video Captioning and Matching, and Video Search & Retrieval
Sep 21, 2020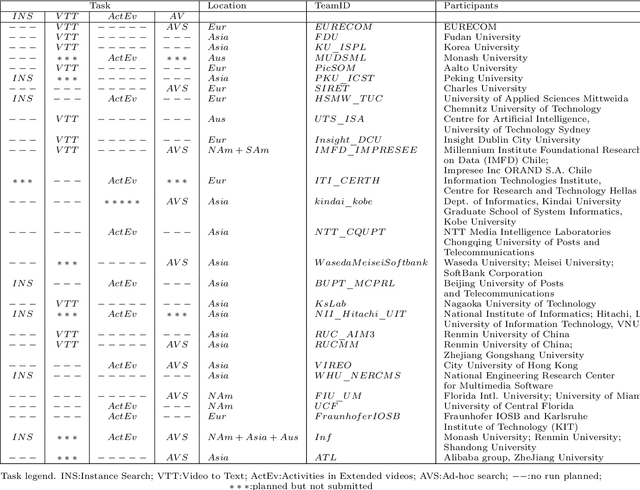
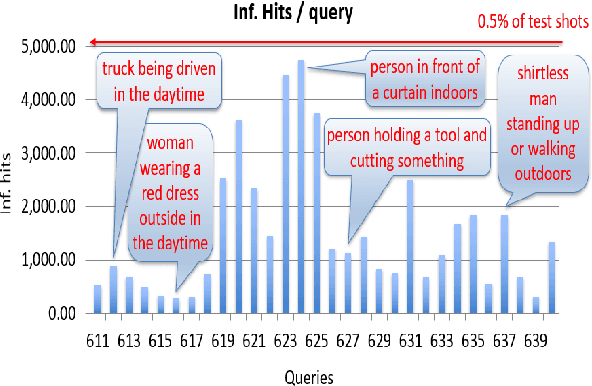

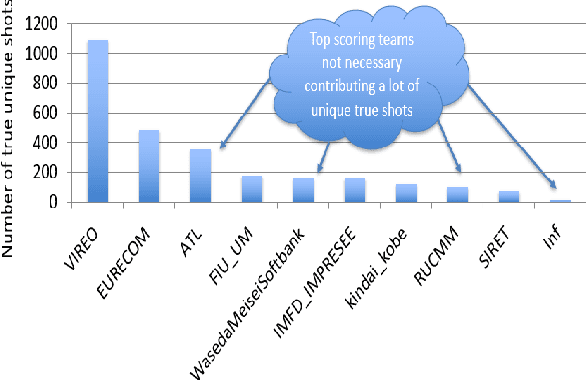
The TREC Video Retrieval Evaluation (TRECVID) 2019 was a TREC-style video analysis and retrieval evaluation, the goal of which remains to promote progress in research and development of content-based exploitation and retrieval of information from digital video via open, metrics-based evaluation. Over the last nineteen years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2019 represented a continuation of four tasks from TRECVID 2018. In total, 27 teams from various research organizations worldwide completed one or more of the following four tasks: 1. Ad-hoc Video Search (AVS) 2. Instance Search (INS) 3. Activities in Extended Video (ActEV) 4. Video to Text Description (VTT) This paper is an introduction to the evaluation framework, tasks, data, and measures used in the workshop.
HLVU : A New Challenge to Test Deep Understanding of Movies the Way Humans do
May 01, 2020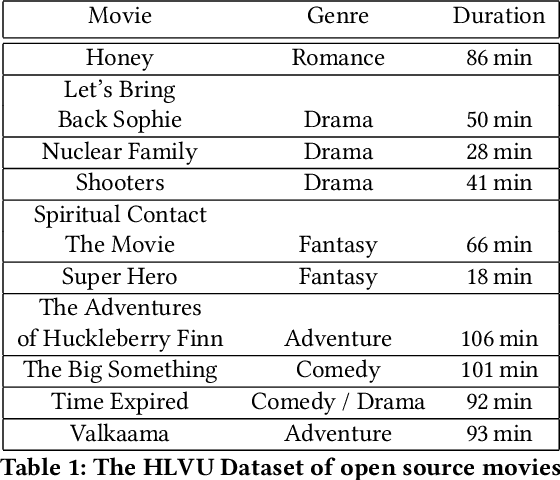
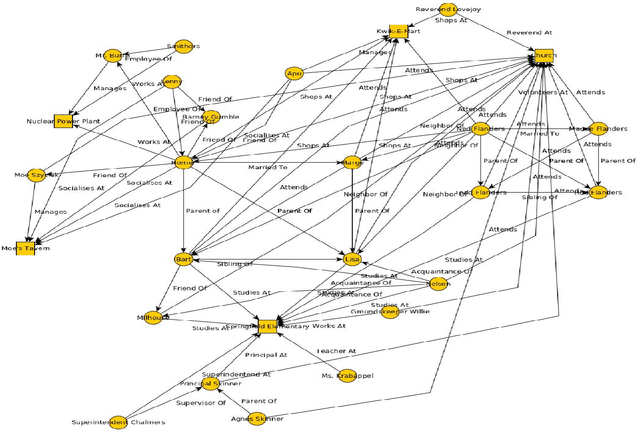
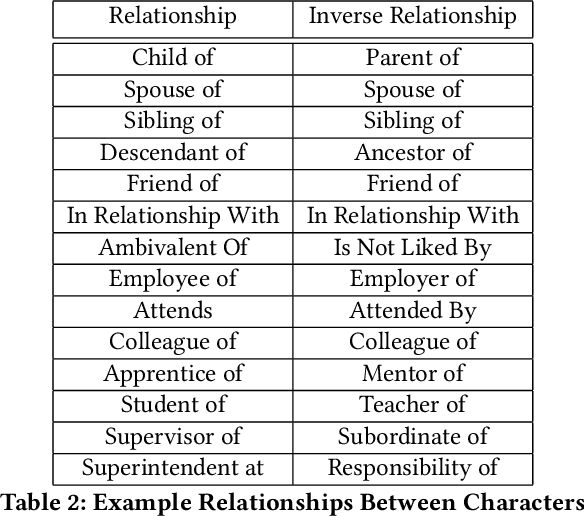
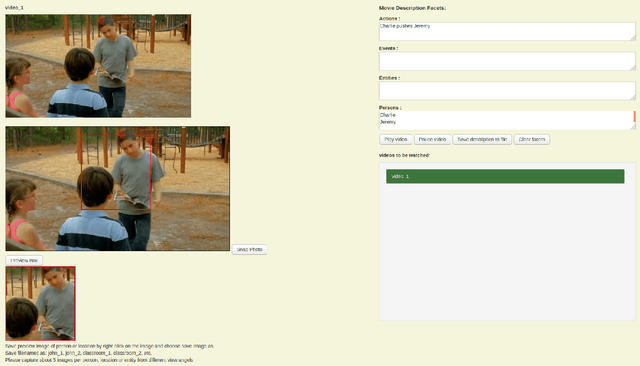
In this paper we propose a new evaluation challenge and direction in the area of High-level Video Understanding. The challenge we are proposing is designed to test automatic video analysis and understanding, and how accurately systems can comprehend a movie in terms of actors, entities, events and their relationship to each other. A pilot High-Level Video Understanding (HLVU) dataset of open source movies were collected for human assessors to build a knowledge graph representing each of them. A set of queries will be derived from the knowledge graph to test systems on retrieving relationships among actors, as well as reasoning and retrieving non-visual concepts. The objective is to benchmark if a computer system can "understand" non-explicit but obvious relationships the same way humans do when they watch the same movies. This is long-standing problem that is being addressed in the text domain and this project moves similar research to the video domain. Work of this nature is foundational to future video analytics and video understanding technologies. This work can be of interest to streaming services and broadcasters hoping to provide more intuitive ways for their customers to interact with and consume video content.
Evaluation of Automatic Video Captioning Using Direct Assessment
Oct 29, 2017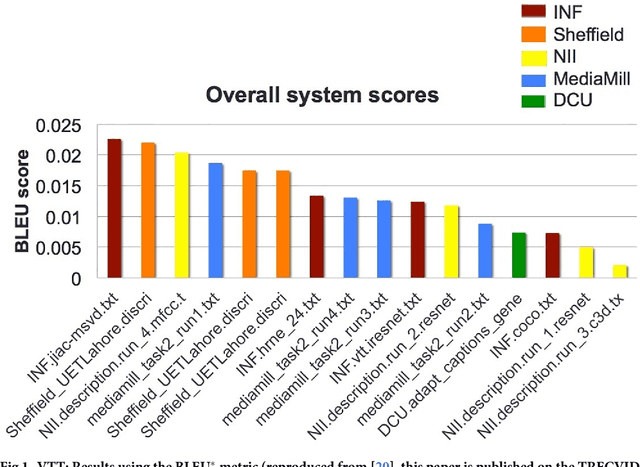

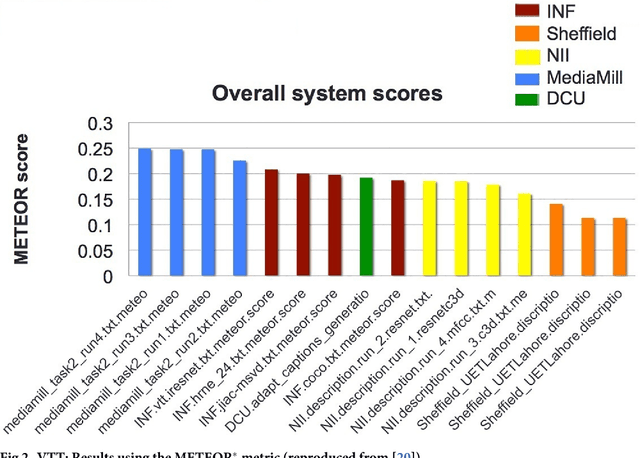
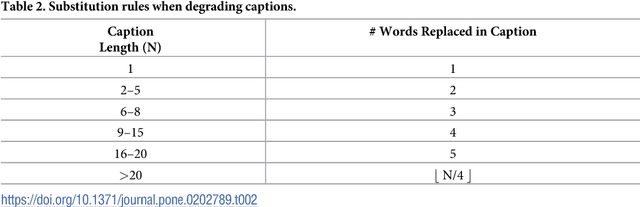
We present Direct Assessment, a method for manually assessing the quality of automatically-generated captions for video. Evaluating the accuracy of video captions is particularly difficult because for any given video clip there is no definitive ground truth or correct answer against which to measure. Automatic metrics for comparing automatic video captions against a manual caption such as BLEU and METEOR, drawn from techniques used in evaluating machine translation, were used in the TRECVid video captioning task in 2016 but these are shown to have weaknesses. The work presented here brings human assessment into the evaluation by crowdsourcing how well a caption describes a video. We automatically degrade the quality of some sample captions which are assessed manually and from this we are able to rate the quality of the human assessors, a factor we take into account in the evaluation. Using data from the TRECVid video-to-text task in 2016, we show how our direct assessment method is replicable and robust and should scale to where there many caption-generation techniques to be evaluated.