 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn overview on the evaluated video retrieval tasks at TRECVID 2022
Jun 22, 2023



The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, tasks-based evaluation supported by metrology. Over the last twenty-one years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2022 planned for the following six tasks: Ad-hoc video search, Video to text captioning, Disaster scene description and indexing, Activity in extended videos, deep video understanding, and movie summarization. In total, 35 teams from various research organizations worldwide signed up to join the evaluation campaign this year. This paper introduces the tasks, datasets used, evaluation frameworks and metrics, as well as a high-level results overview.
TRECVID 2020: A comprehensive campaign for evaluating video retrieval tasks across multiple application domains
Apr 27, 2021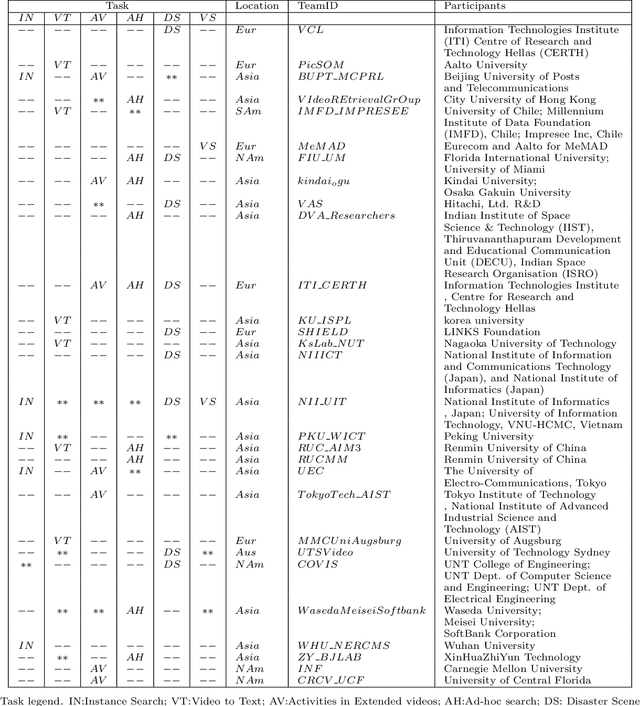

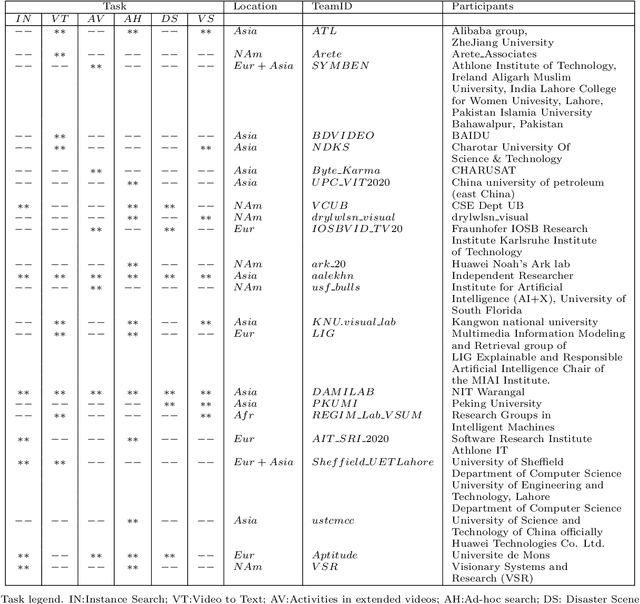
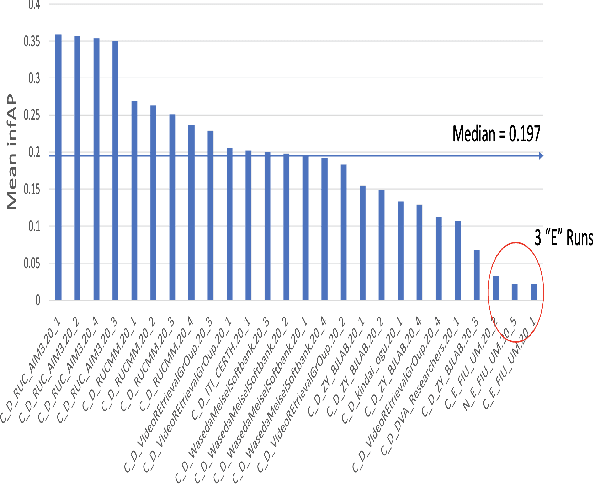
The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, metrics-based evaluation. Over the last twenty years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2020 represented a continuation of four tasks and the addition of two new tasks. In total, 29 teams from various research organizations worldwide completed one or more of the following six tasks: 1. Ad-hoc Video Search (AVS), 2. Instance Search (INS), 3. Disaster Scene Description and Indexing (DSDI), 4. Video to Text Description (VTT), 5. Activities in Extended Video (ActEV), 6. Video Summarization (VSUM). This paper is an introduction to the evaluation framework, tasks, data, and measures used in the evaluation campaign.
TRECVID 2019: An Evaluation Campaign to Benchmark Video Activity Detection, Video Captioning and Matching, and Video Search & Retrieval
Sep 21, 2020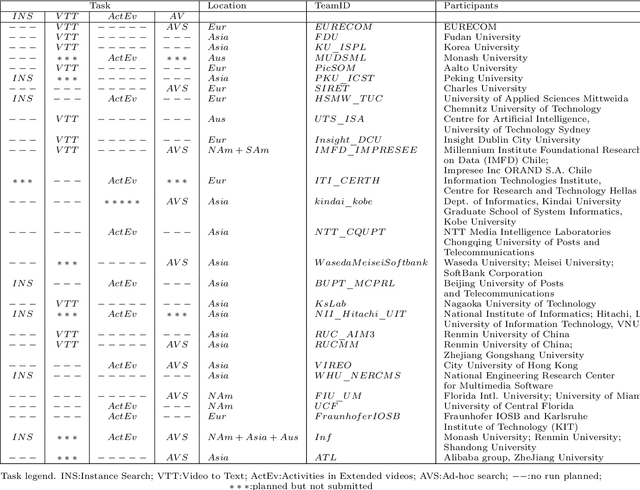
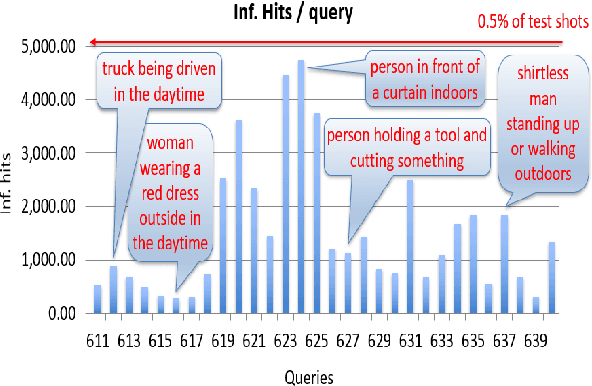

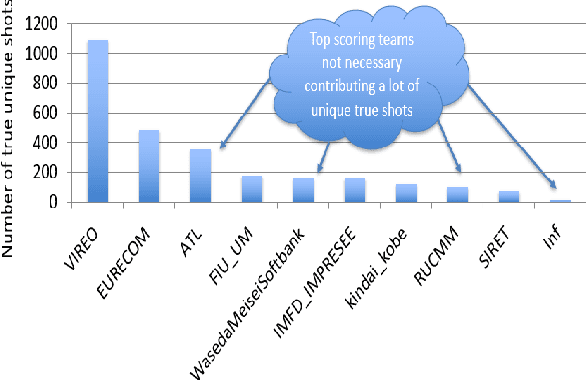
The TREC Video Retrieval Evaluation (TRECVID) 2019 was a TREC-style video analysis and retrieval evaluation, the goal of which remains to promote progress in research and development of content-based exploitation and retrieval of information from digital video via open, metrics-based evaluation. Over the last nineteen years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2019 represented a continuation of four tasks from TRECVID 2018. In total, 27 teams from various research organizations worldwide completed one or more of the following four tasks: 1. Ad-hoc Video Search (AVS) 2. Instance Search (INS) 3. Activities in Extended Video (ActEV) 4. Video to Text Description (VTT) This paper is an introduction to the evaluation framework, tasks, data, and measures used in the workshop.
Shape retrieval of non-rigid 3d human models
Mar 01, 2020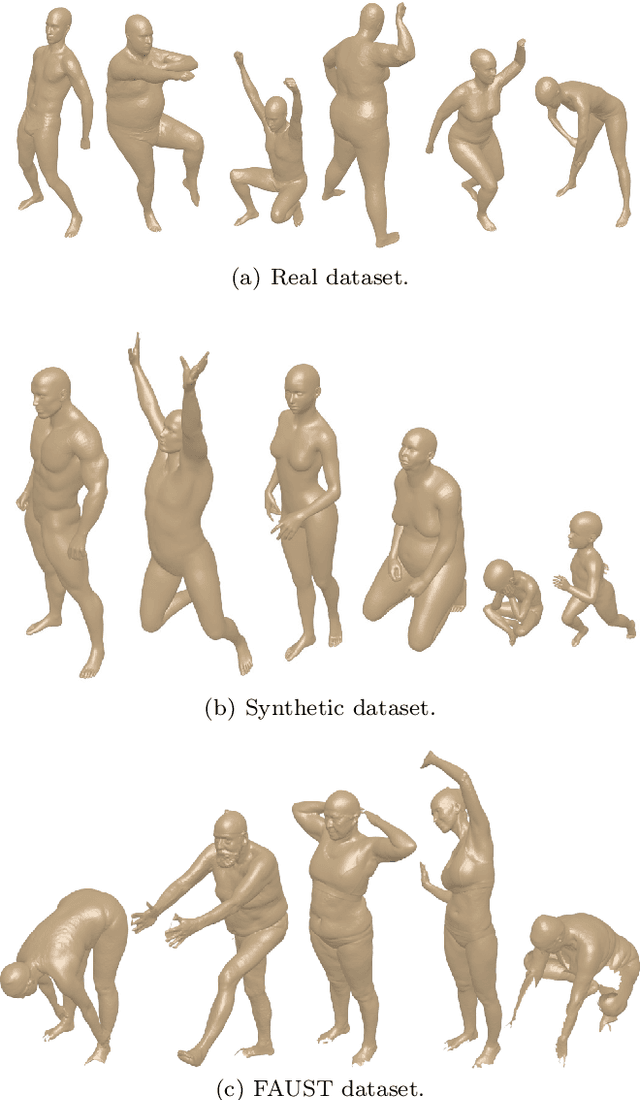
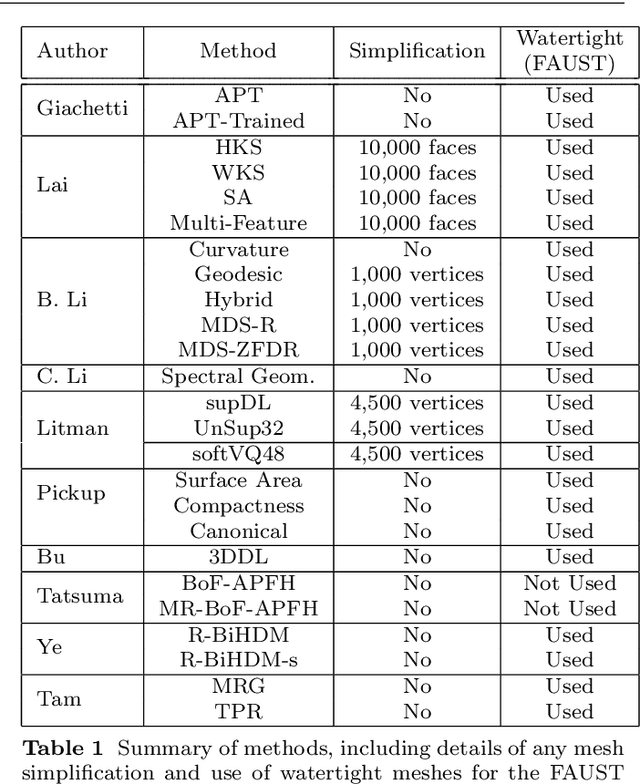
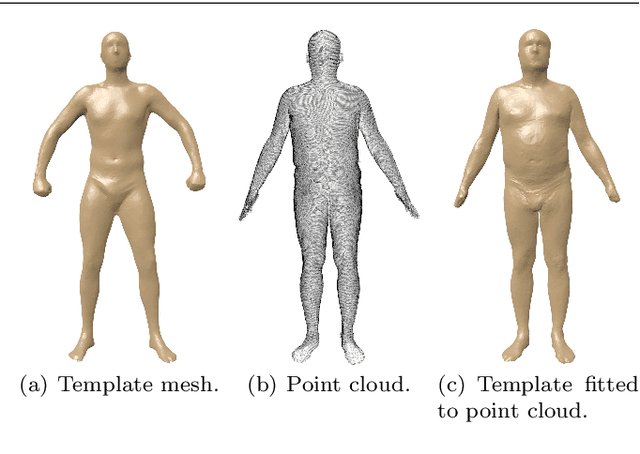
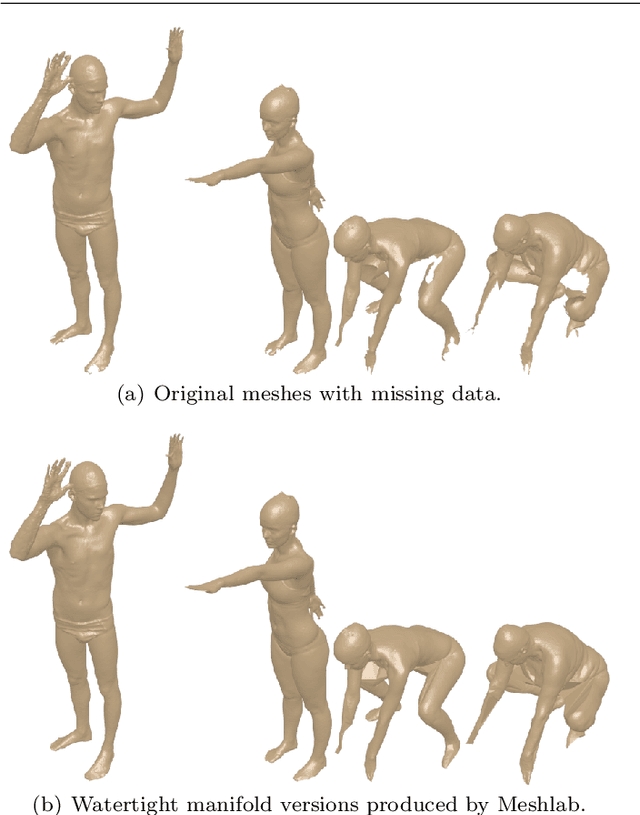
3D models of humans are commonly used within computer graphics and vision, and so the ability to distinguish between body shapes is an important shape retrieval problem. We extend our recent paper which provided a benchmark for testing non-rigid 3D shape retrieval algorithms on 3D human models. This benchmark provided a far stricter challenge than previous shape benchmarks. We have added 145 new models for use as a separate training set, in order to standardise the training data used and provide a fairer comparison. We have also included experiments with the FAUST dataset of human scans. All participants of the previous benchmark study have taken part in the new tests reported here, many providing updated results using the new data. In addition, further participants have also taken part, and we provide extra analysis of the retrieval results. A total of 25 different shape retrieval methods.
An evaluation of local shape descriptors for 3D shape retrieval
Feb 10, 2012As the usage of 3D models increases, so does the importance of developing accurate 3D shape retrieval algorithms. A common approach is to calculate a shape descriptor for each object, which can then be compared to determine two objects' similarity. However, these descriptors are often evaluated independently and on different datasets, making them difficult to compare. Using the SHREC 2011 Shape Retrieval Contest of Non-rigid 3D Watertight Meshes dataset, we systematically evaluate a collection of local shape descriptors. We apply each descriptor to the bag-of-words paradigm and assess the effects of varying the dictionary's size and the number of sample points. In addition, several salient point detection methods are used to choose sample points; these methods are compared to each other and to random selection. Finally, information from two local descriptors is combined in two ways and changes in performance are investigated. This paper presents results of these experiment
Benchmarks, Performance Evaluation and Contests for 3D Shape Retrieval
May 18, 2011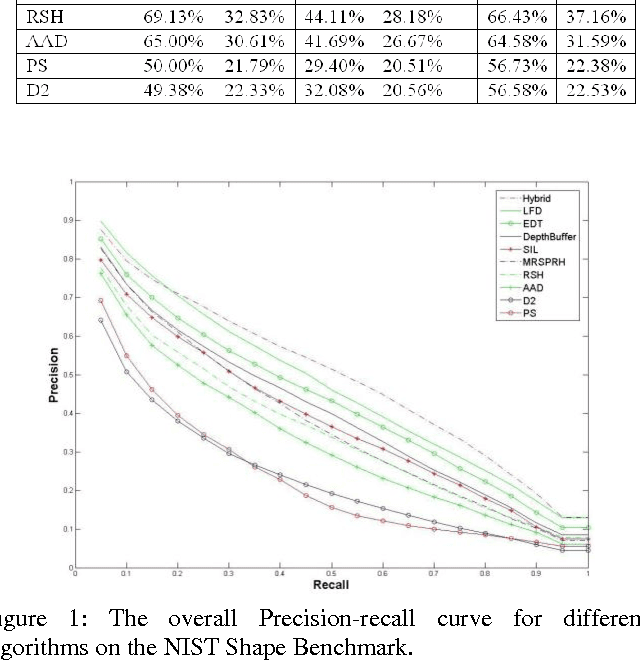

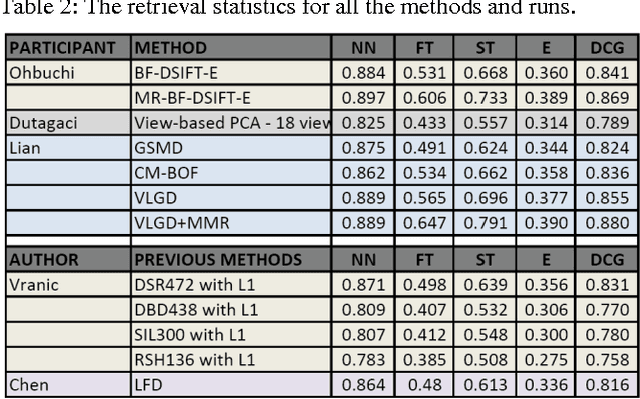
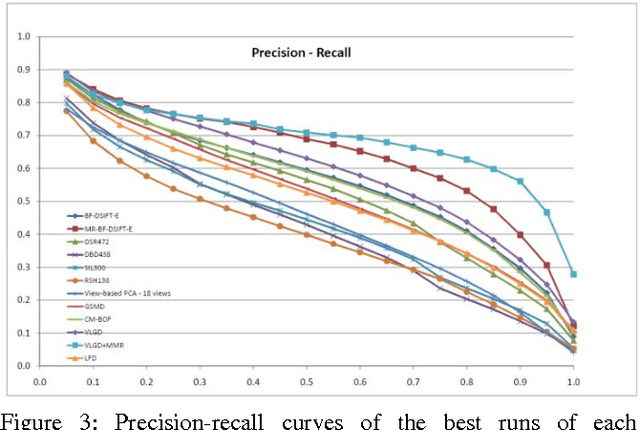
Benchmarking of 3D Shape retrieval allows developers and researchers to compare the strengths of different algorithms on a standard dataset. Here we describe the procedures involved in developing a benchmark and issues involved. We then discuss some of the current 3D shape retrieval benchmarks efforts of our group and others. We also review the different performance evaluation measures that are developed and used by researchers in the community. After that we give an overview of the 3D shape retrieval contest (SHREC) tracks run under the EuroGraphics Workshop on 3D Object Retrieval and give details of tracks that we organized for SHREC 2010. Finally we demonstrate some of the results based on the different SHREC contest tracks and the NIST shape benchmark.
Retrieval and Clustering from a 3D Human Database based on Body and Head Shape
May 13, 2011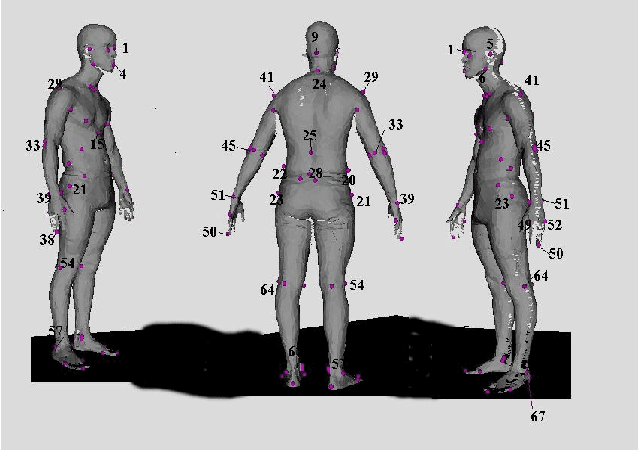
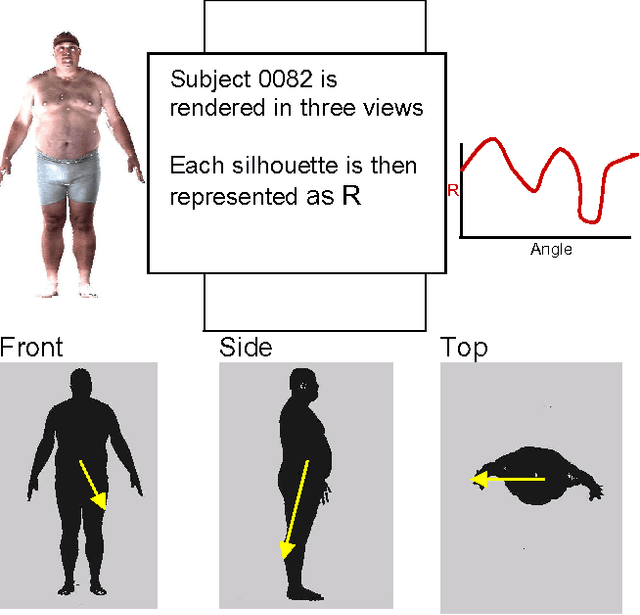
In this paper, we describe a framework for similarity based retrieval and clustering from a 3D human database. Our technique is based on both body and head shape representation and the retrieval is based on similarity of both of them. The 3D human database used in our study is the CAESAR anthropometric database which contains approximately 5000 bodies. We have developed a web-based interface for specifying the queries to interact with the retrieval system. Our approach performs the similarity based retrieval in a reasonable amount of time and is a practical approach.
Face Recognition using 3D Facial Shape and Color Map Information: Comparison and Combination
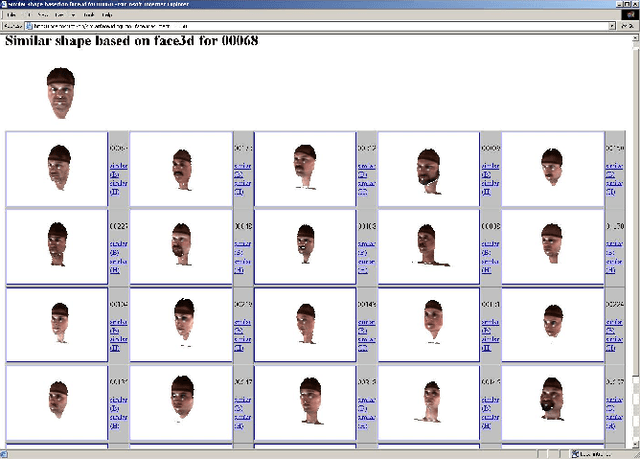
May 13, 2011In this paper, we investigate the use of 3D surface geometry for face recognition and compare it to one based on color map information. The 3D surface and color map data are from the CAESAR anthropometric database. We find that the recognition performance is not very different between 3D surface and color map information using a principal component analysis algorithm. We also discuss the different techniques for the combination of the 3D surface and color map information for multi-modal recognition by using different fusion approaches and show that there is significant improvement in results. The effectiveness of various techniques is compared and evaluated on a dataset with 200 subjects in two different positions.
Salient Local 3D Features for 3D Shape Retrieval
May 13, 2011In this paper we describe a new formulation for the 3D salient local features based on the voxel grid inspired by the Scale Invariant Feature Transform (SIFT). We use it to identify the salient keypoints (invariant points) on a 3D voxelized model and calculate invariant 3D local feature descriptors at these keypoints. We then use the bag of words approach on the 3D local features to represent the 3D models for shape retrieval. The advantages of the method are that it can be applied to rigid as well as to articulated and deformable 3D models. Finally, this approach is applied for 3D Shape Retrieval on the McGill articulated shape benchmark and then the retrieval results are presented and compared to other methods.
View subspaces for indexing and retrieval of 3D models
May 13, 2011View-based indexing schemes for 3D object retrieval are gaining popularity since they provide good retrieval results. These schemes are coherent with the theory that humans recognize objects based on their 2D appearances. The viewbased techniques also allow users to search with various queries such as binary images, range images and even 2D sketches. The previous view-based techniques use classical 2D shape descriptors such as Fourier invariants, Zernike moments, Scale Invariant Feature Transform-based local features and 2D Digital Fourier Transform coefficients. These methods describe each object independent of others. In this work, we explore data driven subspace models, such as Principal Component Analysis, Independent Component Analysis and Nonnegative Matrix Factorization to describe the shape information of the views. We treat the depth images obtained from various points of the view sphere as 2D intensity images and train a subspace to extract the inherent structure of the views within a database. We also show the benefit of categorizing shapes according to their eigenvalue spread. Both the shape categorization and data-driven feature set conjectures are tested on the PSB database and compared with the competitor view-based 3D shape retrieval algorithms