 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReversible Privacy Preservation using Multi-level Encryption and Compressive Sensing
Jun 20, 2019

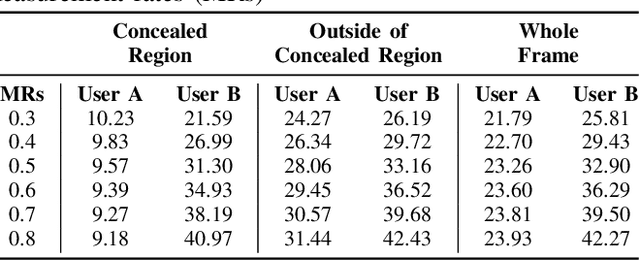
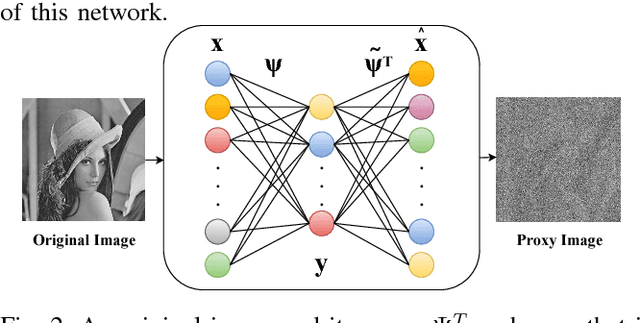
Security monitoring via ubiquitous cameras and their more extended in intelligent buildings stand to gain from advances in signal processing and machine learning. While these innovative and ground-breaking applications can be considered as a boon, at the same time they raise significant privacy concerns. In fact, recent GDPR (General Data Protection Regulation) legislation has highlighted and become an incentive for privacy-preserving solutions. Typical privacy-preserving video monitoring schemes address these concerns by either anonymizing the sensitive data. However, these approaches suffer from some limitations, since they are usually non-reversible, do not provide multiple levels of decryption and computationally costly. In this paper, we provide a novel privacy-preserving method, which is reversible, supports de-identification at multiple privacy levels, and can efficiently perform data acquisition, encryption and data hiding by combining multi-level encryption with compressive sensing. The effectiveness of the proposed approach in protecting the identity of the users has been validated using the goodness of reconstruction quality and strong anonymization of the faces.
Compressively Sensed Image Recognition
Oct 15, 2018
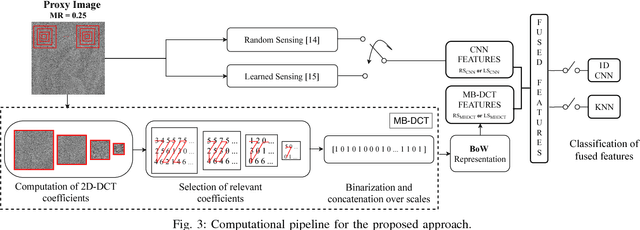

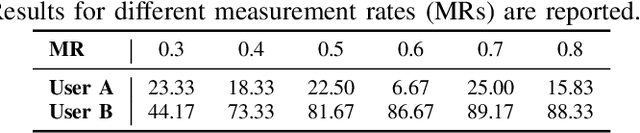
Compressive Sensing (CS) theory asserts that sparse signal reconstruction is possible from a small number of linear measurements. Although CS enables low-cost linear sampling, it requires non-linear and costly reconstruction. Recent literature works show that compressive image classification is possible in CS domain without reconstruction of the signal. In this work, we introduce a DCT base method that extracts binary discriminative features directly from CS measurements. These CS measurements can be obtained by using (i) a random or a pseudo-random measurement matrix, or (ii) a measurement matrix whose elements are learned from the training data to optimize the given classification task. We further introduce feature fusion by concatenating Bag of Words (BoW) representation of our binary features with one of the two state-of-the-art CNN-based feature vectors. We show that our fused feature outperforms the state-of-the-art in both cases.
View subspaces for indexing and retrieval of 3D models
May 13, 2011View-based indexing schemes for 3D object retrieval are gaining popularity since they provide good retrieval results. These schemes are coherent with the theory that humans recognize objects based on their 2D appearances. The viewbased techniques also allow users to search with various queries such as binary images, range images and even 2D sketches. The previous view-based techniques use classical 2D shape descriptors such as Fourier invariants, Zernike moments, Scale Invariant Feature Transform-based local features and 2D Digital Fourier Transform coefficients. These methods describe each object independent of others. In this work, we explore data driven subspace models, such as Principal Component Analysis, Independent Component Analysis and Nonnegative Matrix Factorization to describe the shape information of the views. We treat the depth images obtained from various points of the view sphere as 2D intensity images and train a subspace to extract the inherent structure of the views within a database. We also show the benefit of categorizing shapes according to their eigenvalue spread. Both the shape categorization and data-driven feature set conjectures are tested on the PSB database and compared with the competitor view-based 3D shape retrieval algorithms
Sign Language Tutoring Tool
Feb 18, 2008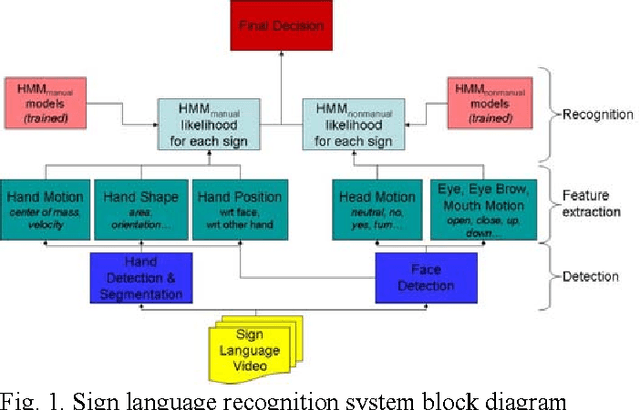
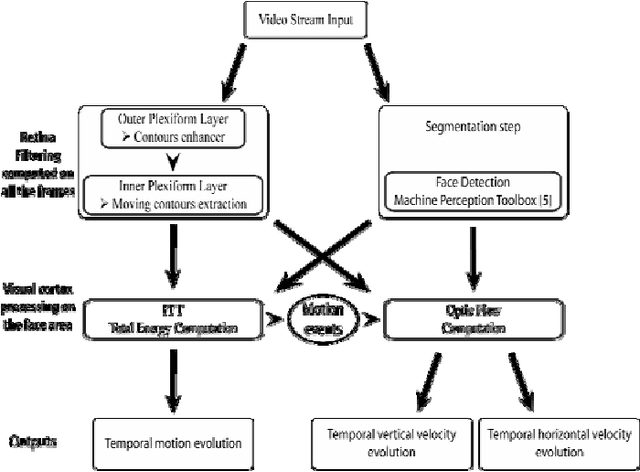
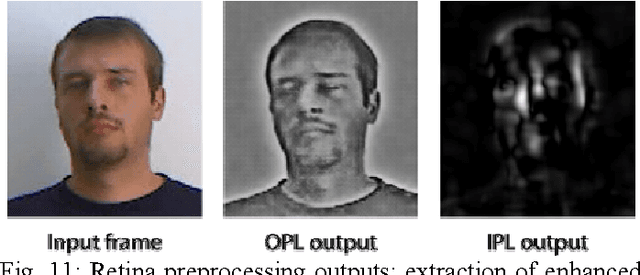
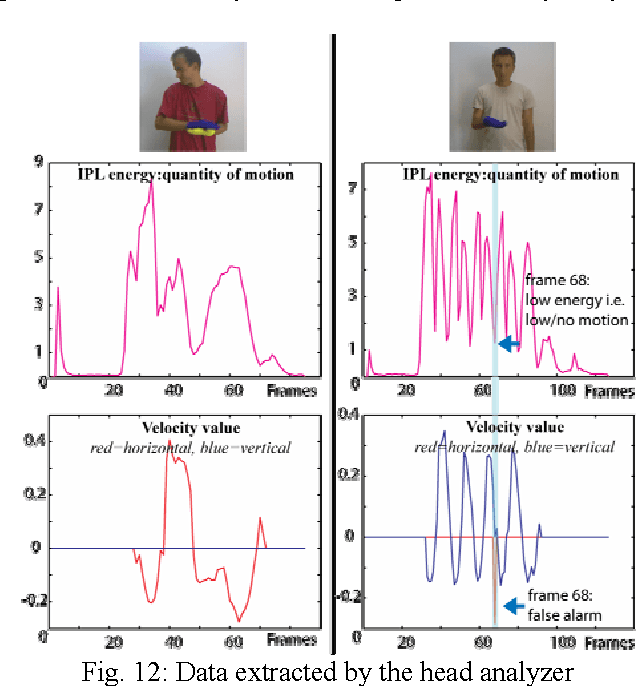
In this project, we have developed a sign language tutor that lets users learn isolated signs by watching recorded videos and by trying the same signs. The system records the user's video and analyses it. If the sign is recognized, both verbal and animated feedback is given to the user. The system is able to recognize complex signs that involve both hand gestures and head movements and expressions. Our performance tests yield a 99% recognition rate on signs involving only manual gestures and 85% recognition rate on signs that involve both manual and non manual components, such as head movement and facial expressions.