 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVICCA: Visual Interpretation and Comprehension of Chest X-ray Anomalies in Generated Report Without Human Feedback
Jan 29, 2025



As artificial intelligence (AI) becomes increasingly central to healthcare, the demand for explainable and trustworthy models is paramount. Current report generation systems for chest X-rays (CXR) often lack mechanisms for validating outputs without expert oversight, raising concerns about reliability and interpretability. To address these challenges, we propose a novel multimodal framework designed to enhance the semantic alignment and localization accuracy of AI-generated medical reports. Our framework integrates two key modules: a Phrase Grounding Model, which identifies and localizes pathologies in CXR images based on textual prompts, and a Text-to-Image Diffusion Module, which generates synthetic CXR images from prompts while preserving anatomical fidelity. By comparing features between the original and generated images, we introduce a dual-scoring system: one score quantifies localization accuracy, while the other evaluates semantic consistency. This approach significantly outperforms existing methods, achieving state-of-the-art results in pathology localization and text-to-image alignment. The integration of phrase grounding with diffusion models, coupled with the dual-scoring evaluation system, provides a robust mechanism for validating report quality, paving the way for more trustworthy and transparent AI in medical imaging.
Semantic Textual Similarity Assessment in Chest X-ray Reports Using a Domain-Specific Cosine-Based Metric
Feb 19, 2024



Medical language processing and deep learning techniques have emerged as critical tools for improving healthcare, particularly in the analysis of medical imaging and medical text data. These multimodal data fusion techniques help to improve the interpretation of medical imaging and lead to increased diagnostic accuracy, informed clinical decisions, and improved patient outcomes. The success of these models relies on the ability to extract and consolidate semantic information from clinical text. This paper addresses the need for more robust methods to evaluate the semantic content of medical reports. Conventional natural language processing approaches and metrics are initially designed for considering the semantic context in the natural language domain and machine translation, often failing to capture the complex semantic meanings inherent in medical content. In this study, we introduce a novel approach designed specifically for assessing the semantic similarity between generated medical reports and the ground truth. Our approach is validated, demonstrating its efficiency in assessing domain-specific semantic similarity within medical contexts. By applying our metric to state-of-the-art Chest X-ray report generation models, we obtain results that not only align with conventional metrics but also provide more contextually meaningful scores in the considered medical domain.
How far generated data can impact Neural Networks performance?
Mar 27, 2023



The success of deep learning models depends on the size and quality of the dataset to solve certain tasks. Here, we explore how far generated data can aid real data in improving the performance of Neural Networks. In this work, we consider facial expression recognition since it requires challenging local data generation at the level of local regions such as mouth, eyebrows, etc, rather than simple augmentation. Generative Adversarial Networks (GANs) provide an alternative method for generating such local deformations but they need further validation. To answer our question, we consider noncomplex Convolutional Neural Networks (CNNs) based classifiers for recognizing Ekman emotions. For the data generation process, we consider generating facial expressions (FEs) by relying on two GANs. The first generates a random identity while the second imposes facial deformations on top of it. We consider training the CNN classifier using FEs from: real-faces, GANs-generated, and finally using a combination of real and GAN-generated faces. We determine an upper bound regarding the data generation quantity to be mixed with the real one which contributes the most to enhancing FER accuracy. In our experiments, we find out that 5-times more synthetic data to the real FEs dataset increases accuracy by 16%.
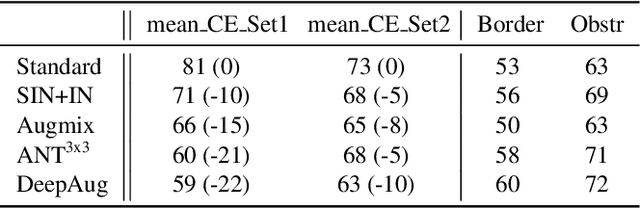
Using Synthetic Corruptions to Measure Robustness to Natural Distribution Shifts
Jul 26, 2021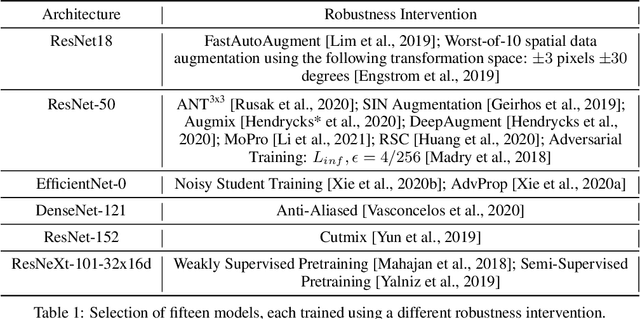


Synthetic corruptions gathered into a benchmark are frequently used to measure neural network robustness to distribution shifts. However, robustness to synthetic corruption benchmarks is not always predictive of robustness to distribution shifts encountered in real-world applications. In this paper, we propose a methodology to build synthetic corruption benchmarks that make robustness estimations more correlated with robustness to real-world distribution shifts. Using the overlapping criterion, we split synthetic corruptions into categories that help to better understand neural network robustness. Based on these categories, we identify three parameters that are relevant to take into account when constructing a corruption benchmark: number of represented categories, balance among categories and size of benchmarks. Applying the proposed methodology, we build a new benchmark called ImageNet-Syn2Nat to predict image classifier robustness.
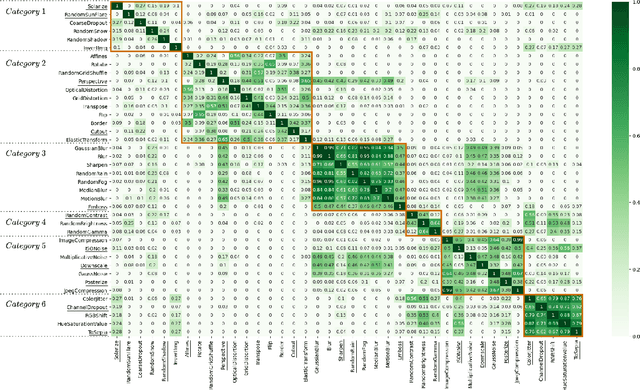
Using the Overlapping Score to Improve Corruption Benchmarks
May 26, 2021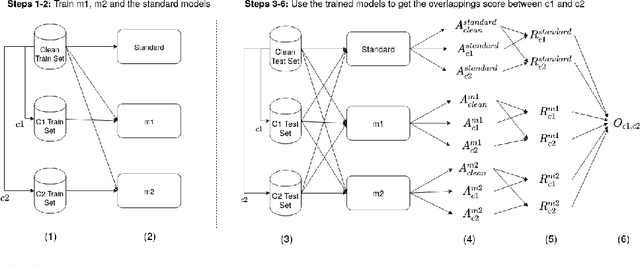
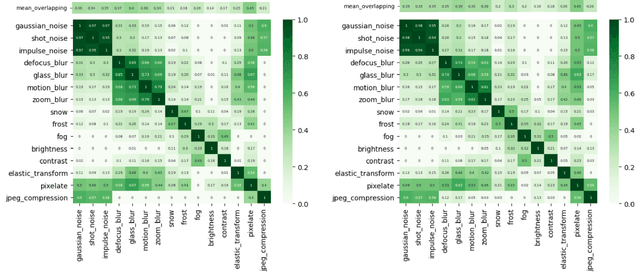
Neural Networks are sensitive to various corruptions that usually occur in real-world applications such as blurs, noises, low-lighting conditions, etc. To estimate the robustness of neural networks to these common corruptions, we generally use a group of modeled corruptions gathered into a benchmark. Unfortunately, no objective criterion exists to determine whether a benchmark is representative of a large diversity of independent corruptions. In this paper, we propose a metric called corruption overlapping score, which can be used to reveal flaws in corruption benchmarks. Two corruptions overlap when the robustnesses of neural networks to these corruptions are correlated. We argue that taking into account overlappings between corruptions can help to improve existing benchmarks or build better ones.
Addressing Neural Network Robustness with Mixup and Targeted Labeling Adversarial Training
Aug 19, 2020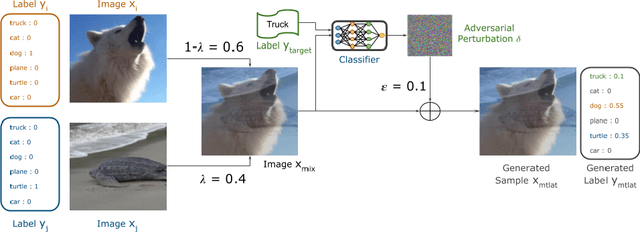
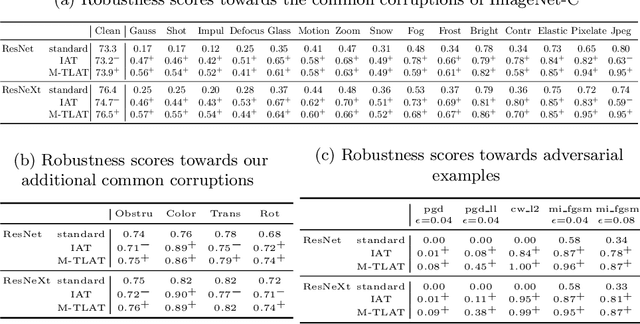
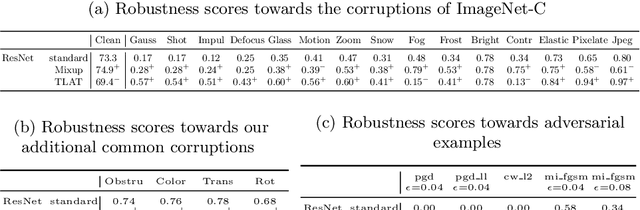

Despite their performance, Artificial Neural Networks are not reliable enough for most of industrial applications. They are sensitive to noises, rotations, blurs and adversarial examples. There is a need to build defenses that protect against a wide range of perturbations, covering the most traditional common corruptions and adversarial examples. We propose a new data augmentation strategy called M-TLAT and designed to address robustness in a broad sense. Our approach combines the Mixup augmentation and a new adversarial training algorithm called Targeted Labeling Adversarial Training (TLAT). The idea of TLAT is to interpolate the target labels of adversarial examples with the ground-truth labels. We show that M-TLAT can increase the robustness of image classifiers towards nineteen common corruptions and five adversarial attacks, without reducing the accuracy on clean samples.
Are Adversarial Robustness and Common Perturbation Robustness Independent Attributes ?
Oct 09, 2019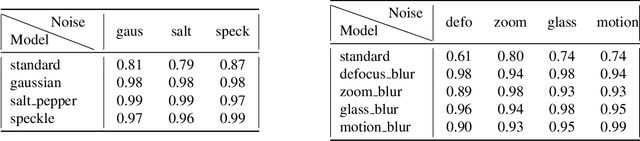



Neural Networks have been shown to be sensitive to common perturbations such as blur, Gaussian noise, rotations, etc. They are also vulnerable to some artificial malicious corruptions called adversarial examples. The adversarial examples study has recently become very popular and it sometimes even reduces the term "adversarial robustness" to the term "robustness". Yet, we do not know to what extent the adversarial robustness is related to the global robustness. Similarly, we do not know if a robustness to various common perturbations such as translations or contrast losses for instance, could help with adversarial corruptions. We intend to study the links between the robustnesses of neural networks to both perturbations. With our experiments, we provide one of the first benchmark designed to estimate the robustness of neural networks to common perturbations. We show that increasing the robustness to carefully selected common perturbations, can make neural networks more robust to unseen common perturbations. We also prove that adversarial robustness and robustness to common perturbations are independent. Our results make us believe that neural network robustness should be addressed in a broader sense.
ADS-ME: Anomaly Detection System for Micro-expression Spotting
Mar 11, 2019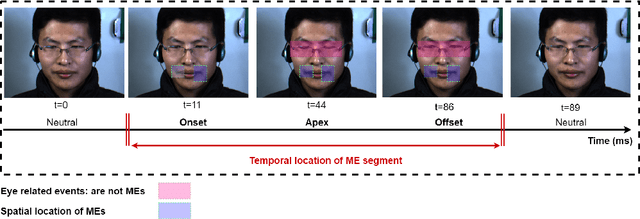
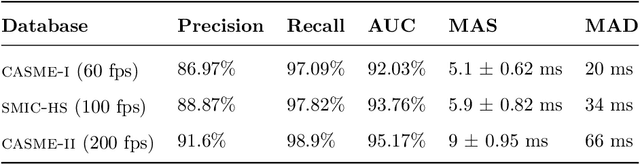
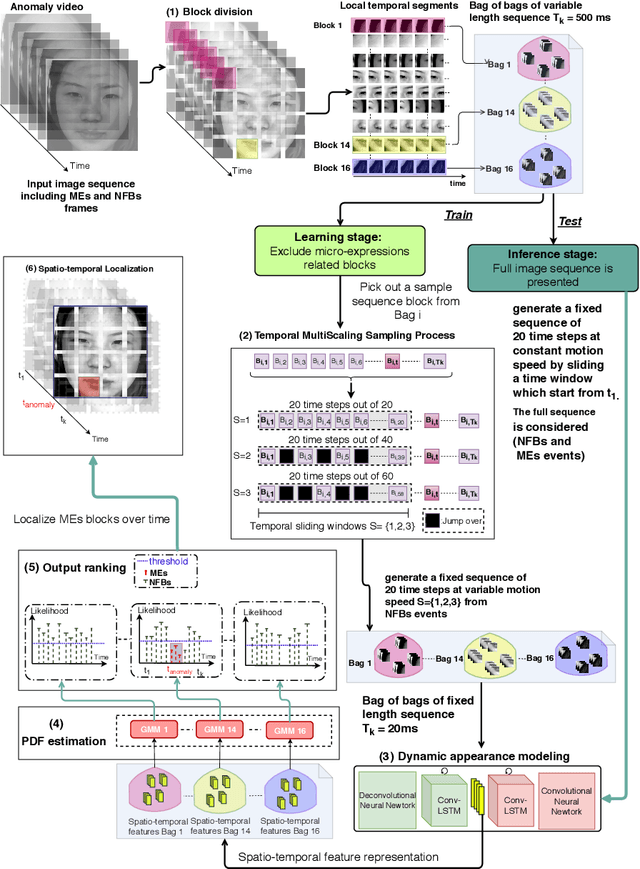

Micro-expressions (MEs) are infrequent and uncontrollable facial events that can highlight emotional deception and appear in a high-stakes environment. This paper propose an algorithm for spatiotemporal MEs spotting. Since MEs are unusual events, we treat them as abnormal patterns that diverge from expected Normal Facial Behaviour (NFBs) patterns. NFBs correspond to facial muscle activations, eye blink/gaze events and mouth opening/closing movements that are all facial deformation but not MEs. We propose a probabilistic model to estimate the probability density function that models the spatiotemporal distributions of NFBs patterns. To rank the outputs, we compute the negative log-likelihood and we developed an adaptive thresholding technique to identify MEs from NFBs. While working only with NFBs data, the main challenge is to capture intrinsic spatiotemoral features, hence we design a recurrent convolutional autoencoder for feature representation. Finally, we show that our system is superior to previous works for MEs spotting.
Spontaneous Facial Expression Recognition using Sparse Representation
Sep 30, 2018

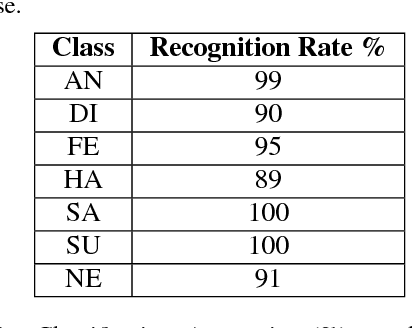
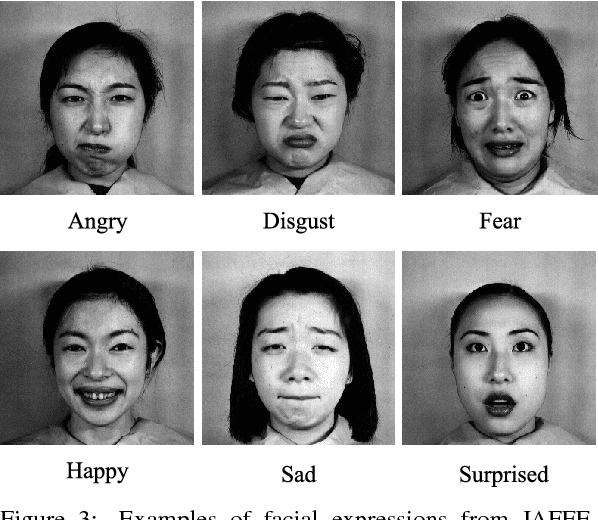
Facial expression is the most natural means for human beings to communicate their emotions. Most facial expression analysis studies consider the case of acted expressions. Spontaneous facial expression recognition is significantly more challenging since each person has a different way to react to a given emotion. We consider the problem of recognizing spontaneous facial expression by learning discriminative dictionaries for sparse representation. Facial images are represented as a sparse linear combination of prototype atoms via Orthogonal Matching Pursuit algorithm. Sparse codes are then used to train an SVM classifier dedicated to the recognition task. The dictionary that sparsifies the facial images (feature points with the same class labels should have similar sparse codes) is crucial for robust classification. Learning sparsifying dictionaries heavily relies on the initialization process of the dictionary. To improve the performance of dictionaries, a random face feature descriptor based on the Random Projection concept is developed. The effectiveness of the proposed method is evaluated through several experiments on the spontaneous facial expressions DynEmo database. It is also estimated on the well-known acted facial expressions JAFFE database for a purpose of comparison with state-of-the-art methods.
Improving Bag-of-Visual-Words Towards Effective Facial Expressive Image Classification
Sep 30, 2018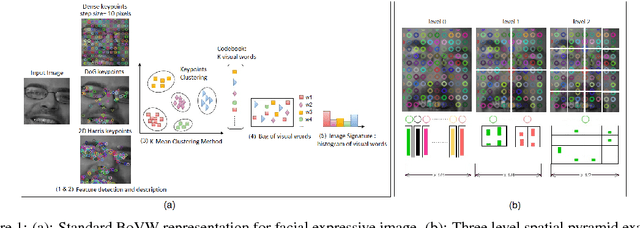

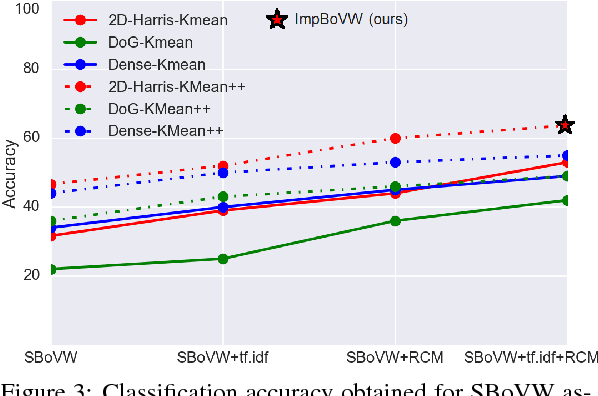

Bag-of-Visual-Words (BoVW) approach has been widely used in the recent years for image classification purposes. However, the limitations regarding optimal feature selection, clustering technique, the lack of spatial organization of the data and the weighting of visual words are crucial. These factors affect the stability of the model and reduce performance. We propose to develop an algorithm based on BoVW for facial expression analysis which goes beyond those limitations. Thus the visual codebook is built by using k-Means++ method to avoid poor clustering. To exploit reliable low level features, we search for the best feature detector that avoids locating a large number of keypoints which do not contribute to the classification process. Then, we propose to compute the relative conjunction matrix in order to preserve the spatial order of the data by coding the relationships among visual words. In addition, a weighting scheme that reflects how important a visual word is with respect to a given image is introduced. We speed up the learning process by using histogram intersection kernel by Support Vector Machine to learn a discriminative classifier. The efficiency of the proposed algorithm is compared with standard bag of visual words method and with bag of visual words method with spatial pyramid. Extensive experiments on the CK+, the MMI and the JAFFE databases show good average recognition rates. Likewise, the ability to recognize spontaneous and non-basic expressive states is investigated using the DynEmo database.
* 8 pages, 6 figures, Volume 5: VISAPPm year 2018, publisher=SciTePress, organization=INSTICC, isbn=978-989-758-290-5