 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVICCA: Visual Interpretation and Comprehension of Chest X-ray Anomalies in Generated Report Without Human Feedback
Jan 29, 2025



As artificial intelligence (AI) becomes increasingly central to healthcare, the demand for explainable and trustworthy models is paramount. Current report generation systems for chest X-rays (CXR) often lack mechanisms for validating outputs without expert oversight, raising concerns about reliability and interpretability. To address these challenges, we propose a novel multimodal framework designed to enhance the semantic alignment and localization accuracy of AI-generated medical reports. Our framework integrates two key modules: a Phrase Grounding Model, which identifies and localizes pathologies in CXR images based on textual prompts, and a Text-to-Image Diffusion Module, which generates synthetic CXR images from prompts while preserving anatomical fidelity. By comparing features between the original and generated images, we introduce a dual-scoring system: one score quantifies localization accuracy, while the other evaluates semantic consistency. This approach significantly outperforms existing methods, achieving state-of-the-art results in pathology localization and text-to-image alignment. The integration of phrase grounding with diffusion models, coupled with the dual-scoring evaluation system, provides a robust mechanism for validating report quality, paving the way for more trustworthy and transparent AI in medical imaging.
Semantic Textual Similarity Assessment in Chest X-ray Reports Using a Domain-Specific Cosine-Based Metric
Feb 19, 2024



Medical language processing and deep learning techniques have emerged as critical tools for improving healthcare, particularly in the analysis of medical imaging and medical text data. These multimodal data fusion techniques help to improve the interpretation of medical imaging and lead to increased diagnostic accuracy, informed clinical decisions, and improved patient outcomes. The success of these models relies on the ability to extract and consolidate semantic information from clinical text. This paper addresses the need for more robust methods to evaluate the semantic content of medical reports. Conventional natural language processing approaches and metrics are initially designed for considering the semantic context in the natural language domain and machine translation, often failing to capture the complex semantic meanings inherent in medical content. In this study, we introduce a novel approach designed specifically for assessing the semantic similarity between generated medical reports and the ground truth. Our approach is validated, demonstrating its efficiency in assessing domain-specific semantic similarity within medical contexts. By applying our metric to state-of-the-art Chest X-ray report generation models, we obtain results that not only align with conventional metrics but also provide more contextually meaningful scores in the considered medical domain.
Optimal Latent Vector Alignment for Unsupervised Domain Adaptation in Medical Image Segmentation
Jun 15, 2021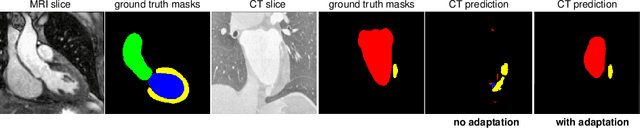
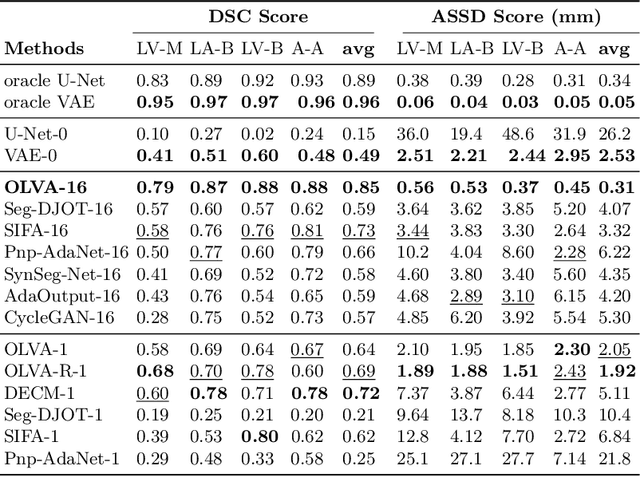

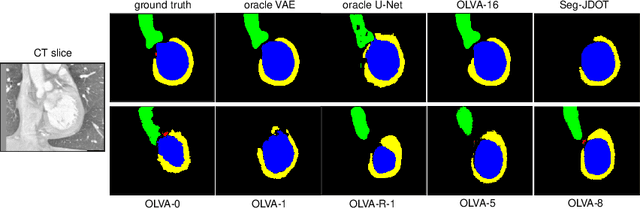
This paper addresses the domain shift problem for segmentation. As a solution, we propose OLVA, a novel and lightweight unsupervised domain adaptation method based on a Variational Auto-Encoder (VAE) and Optimal Transport (OT) theory. Thanks to the VAE, our model learns a shared cross-domain latent space that follows a normal distribution, which reduces the domain shift. To guarantee valid segmentations, our shared latent space is designed to model the shape rather than the intensity variations. We further rely on an OT loss to match and align the remaining discrepancy between the two domains in the latent space. We demonstrate OLVA's effectiveness for the segmentation of multiple cardiac structures on the public Multi-Modality Whole Heart Segmentation (MM-WHS) dataset, where the source domain consists of annotated 3D MR images and the unlabelled target domain of 3D CTs. Our results show remarkable improvements with an additional margin of 12.5\% dice score over concurrent generative training approaches.
IFSS-Net: Interactive Few-Shot Siamese Network for Faster Muscles Segmentation and Propagation in 3-D Freehand Ultrasound
Nov 26, 2020
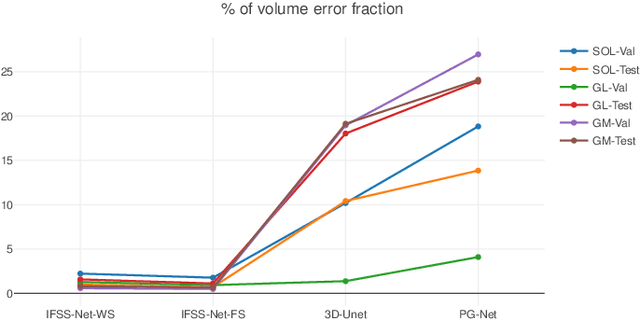


We present an accurate, fast and efficient method for segmentation and muscle mask propagation in 3D freehand ultrasound data, towards accurate volume quantification. To this end, we propose a deep Siamese 3D Encoder-Decoder network that captures the evolution of the muscle appearance and shape for contiguous slices and uses it to propagate a reference mask annotated by a clinical expert. To handle longer changes of the muscle shape over the entire volume and to provide an accurate propagation, we devised a Bidirectional Long Short Term Memory module. To train our model with a minimal amount of training samples, we propose a strategy to combine learning from few annotated 2D ultrasound slices with sequential pseudo-labeling of the unannotated slices. To promote few-shot learning, we propose a decremental update of the objective function to guide the model convergence in the absence of large amounts of annotated data. Finally, to handle the class-imbalance between foreground and background muscle pixels, we propose a parametric Tversky loss function that learns to adaptively penalize false positives and false negatives. We validate our approach for the segmentation, label propagation, and volume computation of the three low-limb muscles on a dataset of 44 subjects. We achieve a dice score coefficient of over $95~\%$ and a small fraction of error with $1.6035~\pm~0.587$.
ADS-ME: Anomaly Detection System for Micro-expression Spotting
Mar 11, 2019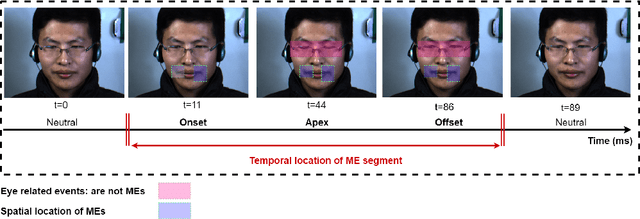
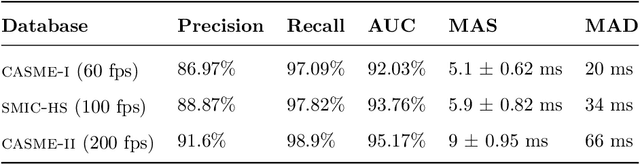
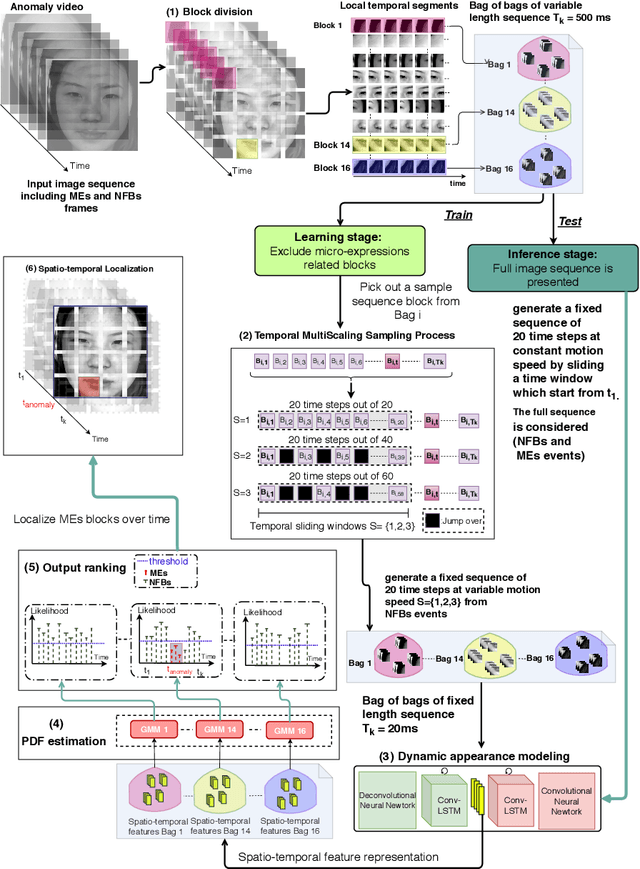

Micro-expressions (MEs) are infrequent and uncontrollable facial events that can highlight emotional deception and appear in a high-stakes environment. This paper propose an algorithm for spatiotemporal MEs spotting. Since MEs are unusual events, we treat them as abnormal patterns that diverge from expected Normal Facial Behaviour (NFBs) patterns. NFBs correspond to facial muscle activations, eye blink/gaze events and mouth opening/closing movements that are all facial deformation but not MEs. We propose a probabilistic model to estimate the probability density function that models the spatiotemporal distributions of NFBs patterns. To rank the outputs, we compute the negative log-likelihood and we developed an adaptive thresholding technique to identify MEs from NFBs. While working only with NFBs data, the main challenge is to capture intrinsic spatiotemoral features, hence we design a recurrent convolutional autoencoder for feature representation. Finally, we show that our system is superior to previous works for MEs spotting.
Spontaneous Facial Expression Recognition using Sparse Representation
Sep 30, 2018

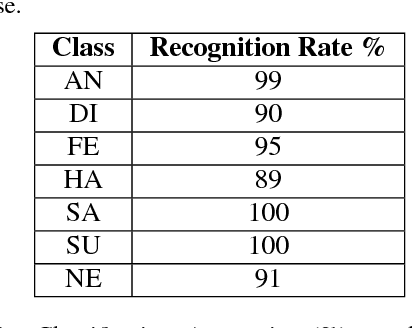
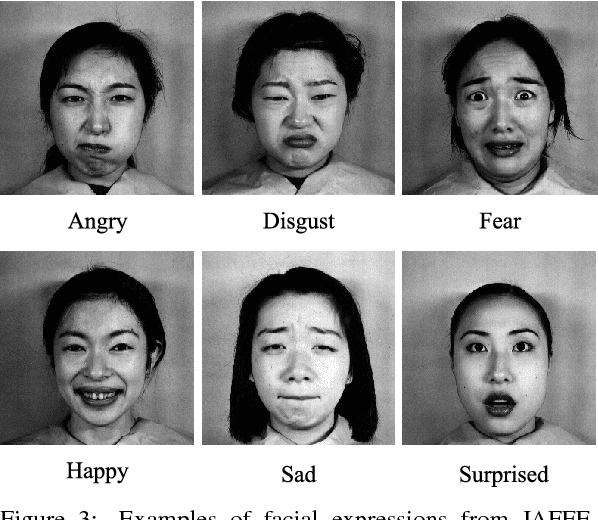
Facial expression is the most natural means for human beings to communicate their emotions. Most facial expression analysis studies consider the case of acted expressions. Spontaneous facial expression recognition is significantly more challenging since each person has a different way to react to a given emotion. We consider the problem of recognizing spontaneous facial expression by learning discriminative dictionaries for sparse representation. Facial images are represented as a sparse linear combination of prototype atoms via Orthogonal Matching Pursuit algorithm. Sparse codes are then used to train an SVM classifier dedicated to the recognition task. The dictionary that sparsifies the facial images (feature points with the same class labels should have similar sparse codes) is crucial for robust classification. Learning sparsifying dictionaries heavily relies on the initialization process of the dictionary. To improve the performance of dictionaries, a random face feature descriptor based on the Random Projection concept is developed. The effectiveness of the proposed method is evaluated through several experiments on the spontaneous facial expressions DynEmo database. It is also estimated on the well-known acted facial expressions JAFFE database for a purpose of comparison with state-of-the-art methods.
Improving Bag-of-Visual-Words Towards Effective Facial Expressive Image Classification
Sep 30, 2018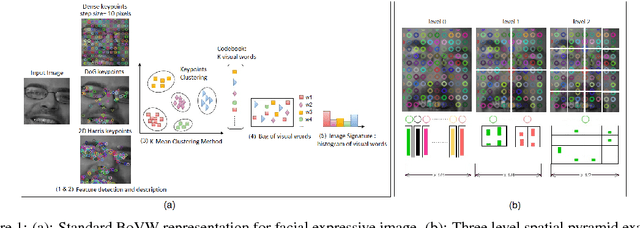

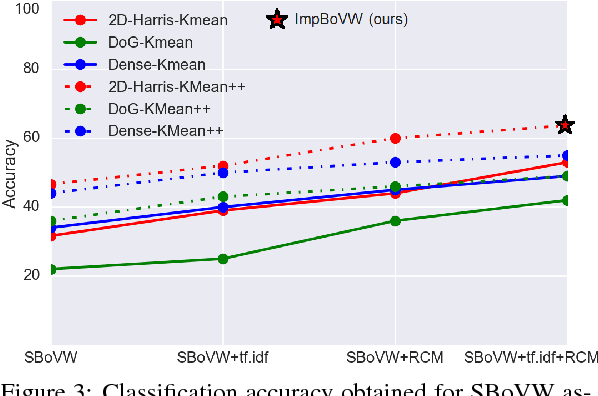

Bag-of-Visual-Words (BoVW) approach has been widely used in the recent years for image classification purposes. However, the limitations regarding optimal feature selection, clustering technique, the lack of spatial organization of the data and the weighting of visual words are crucial. These factors affect the stability of the model and reduce performance. We propose to develop an algorithm based on BoVW for facial expression analysis which goes beyond those limitations. Thus the visual codebook is built by using k-Means++ method to avoid poor clustering. To exploit reliable low level features, we search for the best feature detector that avoids locating a large number of keypoints which do not contribute to the classification process. Then, we propose to compute the relative conjunction matrix in order to preserve the spatial order of the data by coding the relationships among visual words. In addition, a weighting scheme that reflects how important a visual word is with respect to a given image is introduced. We speed up the learning process by using histogram intersection kernel by Support Vector Machine to learn a discriminative classifier. The efficiency of the proposed algorithm is compared with standard bag of visual words method and with bag of visual words method with spatial pyramid. Extensive experiments on the CK+, the MMI and the JAFFE databases show good average recognition rates. Likewise, the ability to recognize spontaneous and non-basic expressive states is investigated using the DynEmo database.
* 8 pages, 6 figures, Volume 5: VISAPPm year 2018, publisher=SciTePress, organization=INSTICC, isbn=978-989-758-290-5