 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Enhanced Real Estate Appraisal
Mar 13, 2026The Sales Comparison Approach (SCA) is one of the most popular when it comes to real estate appraisal. Used as a reference in real estate expertise and as one of the major types of Automatic Valuation Models (AVM), it recently gained popularity within machine learning methods. The performance of models able to use data represented as sets and graphs made it possible to adapt this methodology efficiently, yielding substantial results. SCA relies on taking past transactions (comparables) as references, selected according to their similarity with the target property's sale. In this study, we focus on the selection of these comparables for real estate appraisal. We demonstrate that the selection of comparables used in many state-of-the-art algorithms can be significantly improved by learning a selection policy instead of imposing it. Our method relies on a hybrid vector-geographical retrieval module capable of adapting to different datasets and optimized jointly with an estimation module. We further show that the use of carefully selected comparables makes it possible to build models that require fewer comparables and fewer parameters with performance close to state-of-the-art models. All our evaluations are made on five datasets which span areas in the United States, Brazil, and France.
Online Unsupervised Domain Adaptation for Person Re-identification
May 09, 2022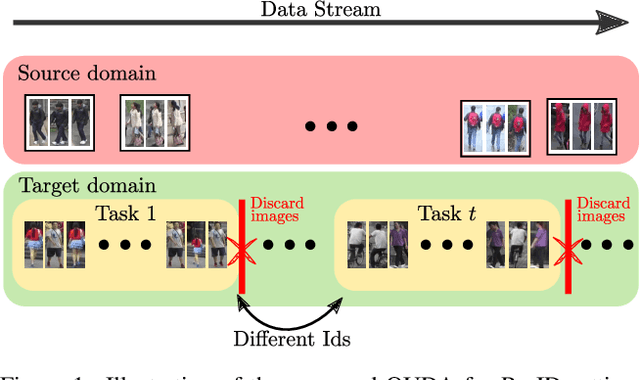
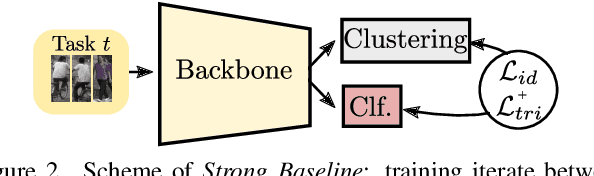
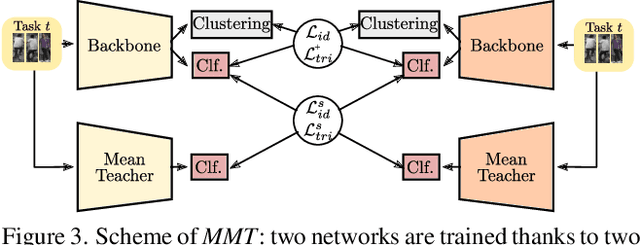
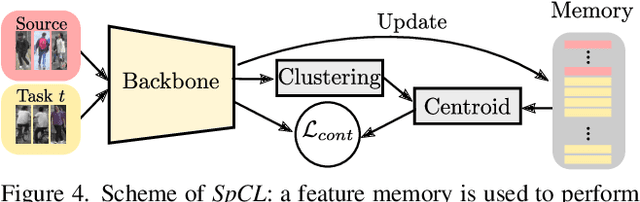
Unsupervised domain adaptation for person re-identification (Person Re-ID) is the task of transferring the learned knowledge on the labeled source domain to the unlabeled target domain. Most of the recent papers that address this problem adopt an offline training setting. More precisely, the training of the Re-ID model is done assuming that we have access to the complete training target domain data set. In this paper, we argue that the target domain generally consists of a stream of data in a practical real-world application, where data is continuously increasing from the different network's cameras. The Re-ID solutions are also constrained by confidentiality regulations stating that the collected data can be stored for only a limited period, hence the model can no longer get access to previously seen target images. Therefore, we present a new yet practical online setting for Unsupervised Domain Adaptation for person Re-ID with two main constraints: Online Adaptation and Privacy Protection. We then adapt and evaluate the state-of-the-art UDA algorithms on this new online setting using the well-known Market-1501, Duke, and MSMT17 benchmarks.
Prediction of fish location by combining fisheries data and sea bottom temperature forecasting
May 04, 2022


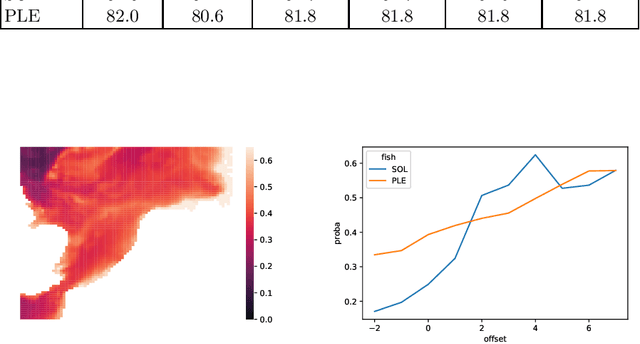
This paper combines fisheries dependent data and environmental data to be used in a machine learning pipeline to predict the spatio-temporal abundance of two species (plaice and sole) commonly caught by the Belgian fishery in the North Sea. By combining fisheries related features with environmental data, sea bottom temperature derived from remote sensing, a higher accuracy can be achieved. In a forecast setting, the predictive accuracy is further improved by predicting, using a recurrent deep neural network, the sea bottom temperature up to four days in advance instead of relying on the last previous temperature measurement.
Using Synthetic Corruptions to Measure Robustness to Natural Distribution Shifts
Jul 26, 2021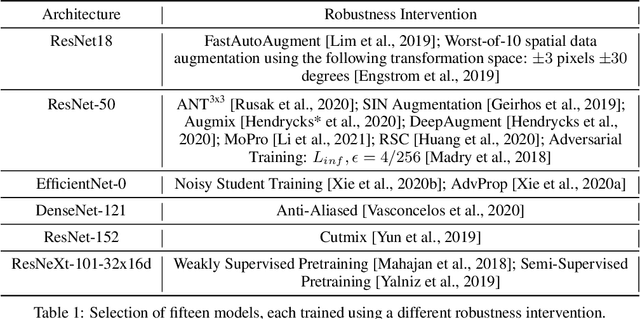


Synthetic corruptions gathered into a benchmark are frequently used to measure neural network robustness to distribution shifts. However, robustness to synthetic corruption benchmarks is not always predictive of robustness to distribution shifts encountered in real-world applications. In this paper, we propose a methodology to build synthetic corruption benchmarks that make robustness estimations more correlated with robustness to real-world distribution shifts. Using the overlapping criterion, we split synthetic corruptions into categories that help to better understand neural network robustness. Based on these categories, we identify three parameters that are relevant to take into account when constructing a corruption benchmark: number of represented categories, balance among categories and size of benchmarks. Applying the proposed methodology, we build a new benchmark called ImageNet-Syn2Nat to predict image classifier robustness.
Using the Overlapping Score to Improve Corruption Benchmarks
May 26, 2021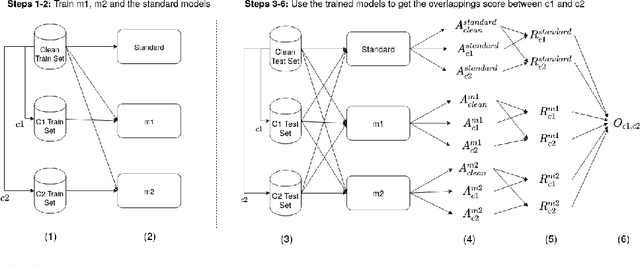
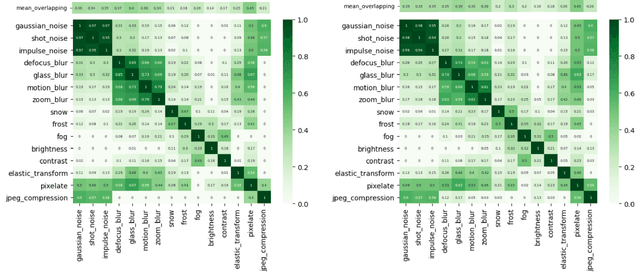
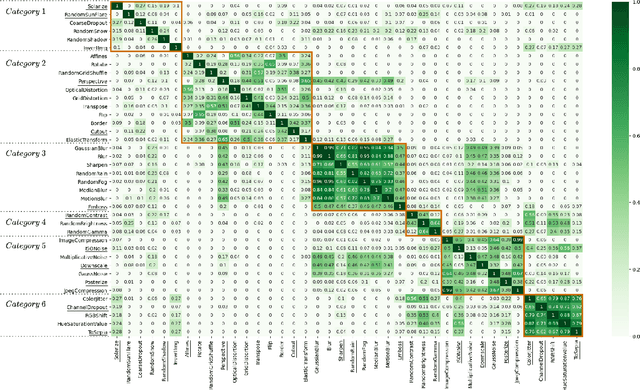
Neural Networks are sensitive to various corruptions that usually occur in real-world applications such as blurs, noises, low-lighting conditions, etc. To estimate the robustness of neural networks to these common corruptions, we generally use a group of modeled corruptions gathered into a benchmark. Unfortunately, no objective criterion exists to determine whether a benchmark is representative of a large diversity of independent corruptions. In this paper, we propose a metric called corruption overlapping score, which can be used to reveal flaws in corruption benchmarks. Two corruptions overlap when the robustnesses of neural networks to these corruptions are correlated. We argue that taking into account overlappings between corruptions can help to improve existing benchmarks or build better ones.
Addressing Neural Network Robustness with Mixup and Targeted Labeling Adversarial Training
Aug 19, 2020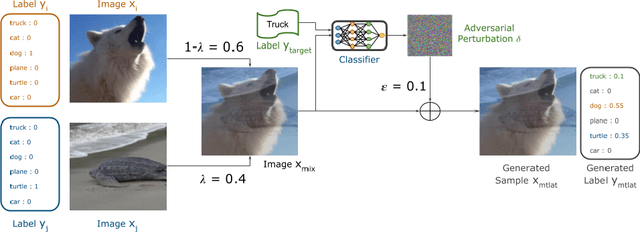
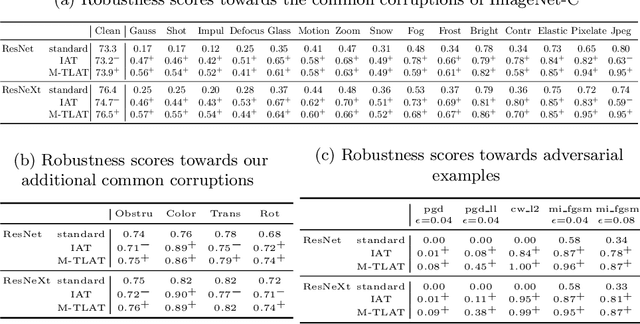
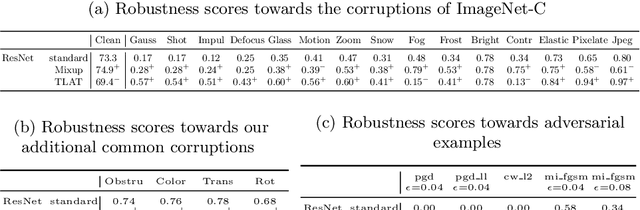

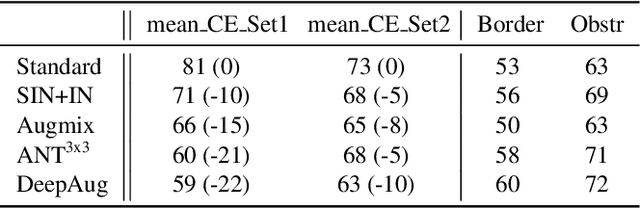
Despite their performance, Artificial Neural Networks are not reliable enough for most of industrial applications. They are sensitive to noises, rotations, blurs and adversarial examples. There is a need to build defenses that protect against a wide range of perturbations, covering the most traditional common corruptions and adversarial examples. We propose a new data augmentation strategy called M-TLAT and designed to address robustness in a broad sense. Our approach combines the Mixup augmentation and a new adversarial training algorithm called Targeted Labeling Adversarial Training (TLAT). The idea of TLAT is to interpolate the target labels of adversarial examples with the ground-truth labels. We show that M-TLAT can increase the robustness of image classifiers towards nineteen common corruptions and five adversarial attacks, without reducing the accuracy on clean samples.
Are Adversarial Robustness and Common Perturbation Robustness Independent Attributes ?
Oct 09, 2019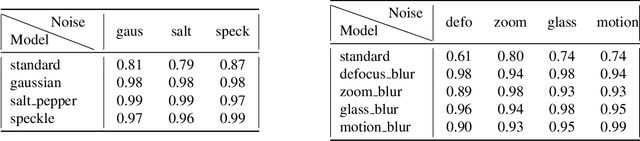



Neural Networks have been shown to be sensitive to common perturbations such as blur, Gaussian noise, rotations, etc. They are also vulnerable to some artificial malicious corruptions called adversarial examples. The adversarial examples study has recently become very popular and it sometimes even reduces the term "adversarial robustness" to the term "robustness". Yet, we do not know to what extent the adversarial robustness is related to the global robustness. Similarly, we do not know if a robustness to various common perturbations such as translations or contrast losses for instance, could help with adversarial corruptions. We intend to study the links between the robustnesses of neural networks to both perturbations. With our experiments, we provide one of the first benchmark designed to estimate the robustness of neural networks to common perturbations. We show that increasing the robustness to carefully selected common perturbations, can make neural networks more robust to unseen common perturbations. We also prove that adversarial robustness and robustness to common perturbations are independent. Our results make us believe that neural network robustness should be addressed in a broader sense.
Person re-identification across different datasets with multi-task learning
Jul 25, 2018



This paper presents an approach to tackle the re-identification problem. This is a challenging problem due to the large variation of pose, illumination or camera view. More and more datasets are available to train machine learning models for person re-identification. These datasets vary in conditions: cameras numbers, camera positions, location, season, in size, i.e. number of images, number of different identities. Finally in labeling: there are datasets annotated with attributes while others are not. To deal with this variety of datasets we present in this paper an approach to take information from different datasets to build a system which performs well on all of them. Our model is based on a Convolutional Neural Network (CNN) and trained using multitask learning. Several losses are used to extract the different information available in the different datasets. Our main task is learned with a classification loss. To reduce the intra-class variation we experiment with the center loss. Our paper ends with a performance evaluation in which we discuss the influence of the different losses on the global re-identification performance. We show that with our method, we are able to build a system that performs well on different datasets and simultaneously extracts attributes. We also show that our system outperforms recent re-identification works on two datasets.