 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing the Overlapping Score to Improve Corruption Benchmarks
Paper and Code
May 26, 2021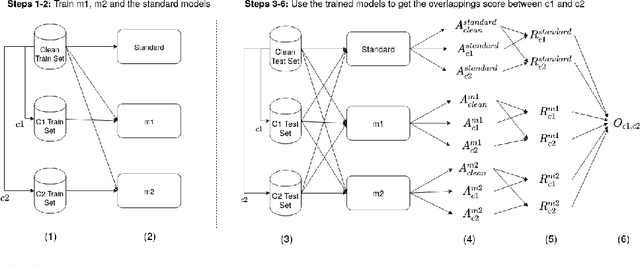
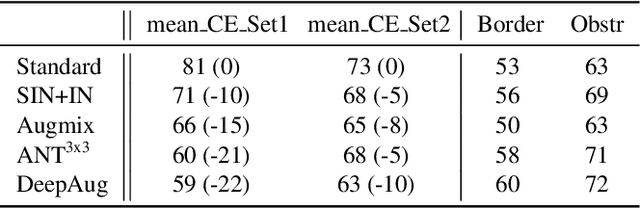
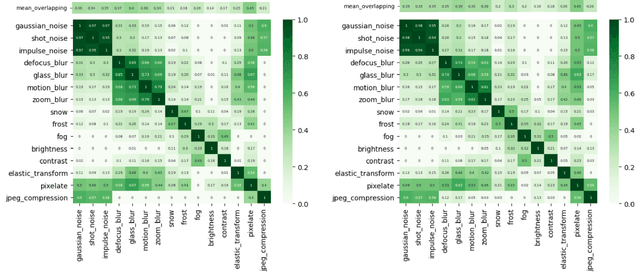
Neural Networks are sensitive to various corruptions that usually occur in real-world applications such as blurs, noises, low-lighting conditions, etc. To estimate the robustness of neural networks to these common corruptions, we generally use a group of modeled corruptions gathered into a benchmark. Unfortunately, no objective criterion exists to determine whether a benchmark is representative of a large diversity of independent corruptions. In this paper, we propose a metric called corruption overlapping score, which can be used to reveal flaws in corruption benchmarks. Two corruptions overlap when the robustnesses of neural networks to these corruptions are correlated. We argue that taking into account overlappings between corruptions can help to improve existing benchmarks or build better ones.