 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Synthetic Corruptions to Measure Robustness to Natural Distribution Shifts
Jul 26, 2021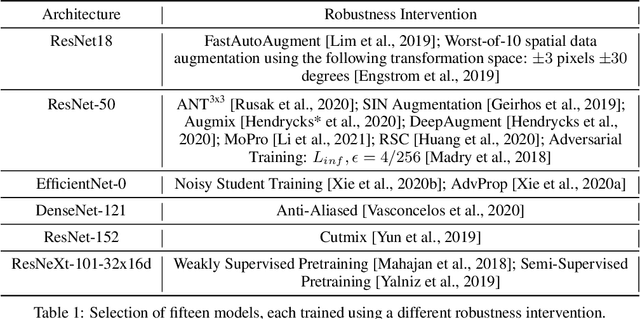


Synthetic corruptions gathered into a benchmark are frequently used to measure neural network robustness to distribution shifts. However, robustness to synthetic corruption benchmarks is not always predictive of robustness to distribution shifts encountered in real-world applications. In this paper, we propose a methodology to build synthetic corruption benchmarks that make robustness estimations more correlated with robustness to real-world distribution shifts. Using the overlapping criterion, we split synthetic corruptions into categories that help to better understand neural network robustness. Based on these categories, we identify three parameters that are relevant to take into account when constructing a corruption benchmark: number of represented categories, balance among categories and size of benchmarks. Applying the proposed methodology, we build a new benchmark called ImageNet-Syn2Nat to predict image classifier robustness.
Using the Overlapping Score to Improve Corruption Benchmarks
May 26, 2021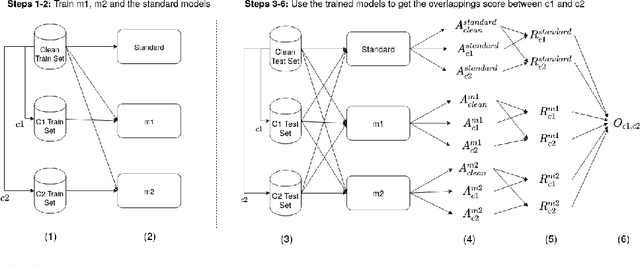
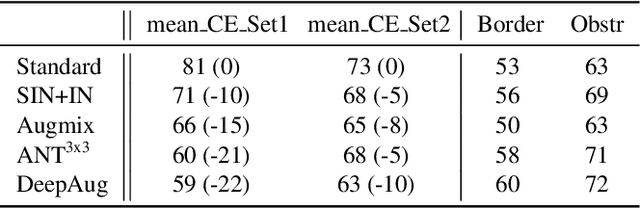
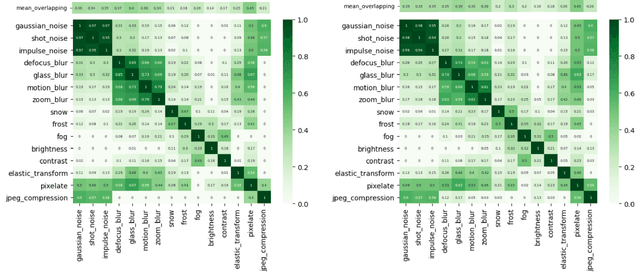
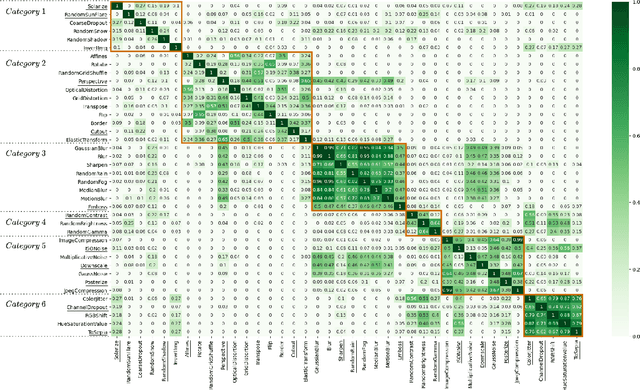
Neural Networks are sensitive to various corruptions that usually occur in real-world applications such as blurs, noises, low-lighting conditions, etc. To estimate the robustness of neural networks to these common corruptions, we generally use a group of modeled corruptions gathered into a benchmark. Unfortunately, no objective criterion exists to determine whether a benchmark is representative of a large diversity of independent corruptions. In this paper, we propose a metric called corruption overlapping score, which can be used to reveal flaws in corruption benchmarks. Two corruptions overlap when the robustnesses of neural networks to these corruptions are correlated. We argue that taking into account overlappings between corruptions can help to improve existing benchmarks or build better ones.
Addressing Neural Network Robustness with Mixup and Targeted Labeling Adversarial Training
Aug 19, 2020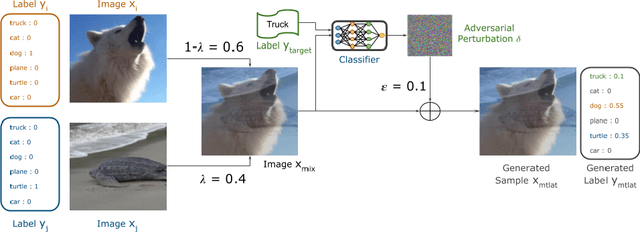
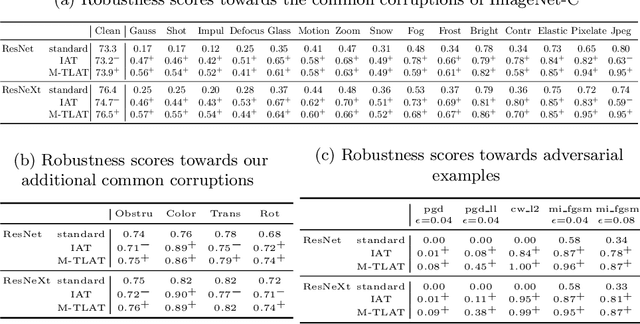
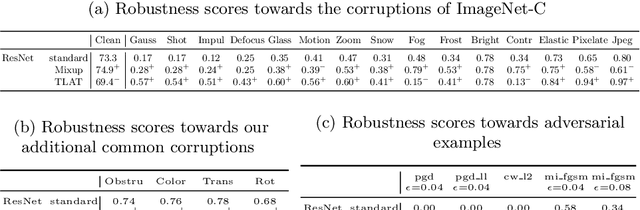

Despite their performance, Artificial Neural Networks are not reliable enough for most of industrial applications. They are sensitive to noises, rotations, blurs and adversarial examples. There is a need to build defenses that protect against a wide range of perturbations, covering the most traditional common corruptions and adversarial examples. We propose a new data augmentation strategy called M-TLAT and designed to address robustness in a broad sense. Our approach combines the Mixup augmentation and a new adversarial training algorithm called Targeted Labeling Adversarial Training (TLAT). The idea of TLAT is to interpolate the target labels of adversarial examples with the ground-truth labels. We show that M-TLAT can increase the robustness of image classifiers towards nineteen common corruptions and five adversarial attacks, without reducing the accuracy on clean samples.
Are Adversarial Robustness and Common Perturbation Robustness Independent Attributes ?
Oct 09, 2019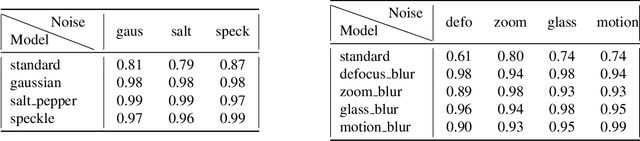



Neural Networks have been shown to be sensitive to common perturbations such as blur, Gaussian noise, rotations, etc. They are also vulnerable to some artificial malicious corruptions called adversarial examples. The adversarial examples study has recently become very popular and it sometimes even reduces the term "adversarial robustness" to the term "robustness". Yet, we do not know to what extent the adversarial robustness is related to the global robustness. Similarly, we do not know if a robustness to various common perturbations such as translations or contrast losses for instance, could help with adversarial corruptions. We intend to study the links between the robustnesses of neural networks to both perturbations. With our experiments, we provide one of the first benchmark designed to estimate the robustness of neural networks to common perturbations. We show that increasing the robustness to carefully selected common perturbations, can make neural networks more robust to unseen common perturbations. We also prove that adversarial robustness and robustness to common perturbations are independent. Our results make us believe that neural network robustness should be addressed in a broader sense.