 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-assembling the past: The RePAIR dataset and benchmark for real world 2D and 3D puzzle solving
Oct 31, 2024



This paper proposes the RePAIR dataset that represents a challenging benchmark to test modern computational and data driven methods for puzzle-solving and reassembly tasks. Our dataset has unique properties that are uncommon to current benchmarks for 2D and 3D puzzle solving. The fragments and fractures are realistic, caused by a collapse of a fresco during a World War II bombing at the Pompeii archaeological park. The fragments are also eroded and have missing pieces with irregular shapes and different dimensions, challenging further the reassembly algorithms. The dataset is multi-modal providing high resolution images with characteristic pictorial elements, detailed 3D scans of the fragments and meta-data annotated by the archaeologists. Ground truth has been generated through several years of unceasing fieldwork, including the excavation and cleaning of each fragment, followed by manual puzzle solving by archaeologists of a subset of approx. 1000 pieces among the 16000 available. After digitizing all the fragments in 3D, a benchmark was prepared to challenge current reassembly and puzzle-solving methods that often solve more simplistic synthetic scenarios. The tested baselines show that there clearly exists a gap to fill in solving this computationally complex problem.
Nash Meets Wertheimer: Using Good Continuation in Jigsaw Puzzles
Oct 22, 2024



Jigsaw puzzle solving is a challenging task for computer vision since it requires high-level spatial and semantic reasoning. To solve the problem, existing approaches invariably use color and/or shape information but in many real-world scenarios, such as in archaeological fresco reconstruction, this kind of clues is often unreliable due to severe physical and pictorial deterioration of the individual fragments. This makes state-of-the-art approaches entirely unusable in practice. On the other hand, in such cases, simple geometrical patterns such as lines or curves offer a powerful yet unexplored clue. In an attempt to fill in this gap, in this paper we introduce a new challenging version of the puzzle solving problem in which one deliberately ignores conventional color and shape features and relies solely on the presence of linear geometrical patterns. The reconstruction process is then only driven by one of the most fundamental principles of Gestalt perceptual organization, namely Wertheimer's {\em law of good continuation}. In order to tackle this problem, we formulate the puzzle solving problem as the problem of finding a Nash equilibrium of a (noncooperative) multiplayer game and use classical multi-population replicator dynamics to solve it. The proposed approach is general and allows us to deal with pieces of arbitrary shape, size and orientation. We evaluate our approach on both synthetic and real-world data and compare it with state-of-the-art algorithms. The results show the intrinsic complexity of our purely line-based puzzle problem as well as the relative effectiveness of our game-theoretic formulation.
* to be published in ACCV2024
Reassembling Broken Objects using Breaking Curves
Jun 05, 2023Reassembling 3D broken objects is a challenging task. A robust solution that generalizes well must deal with diverse patterns associated with different types of broken objects. We propose a method that tackles the pairwise assembly of 3D point clouds, that is agnostic on the type of object, and that relies solely on their geometrical information, without any prior information on the shape of the reconstructed object. The method receives two point clouds as input and segments them into regions using detected closed boundary contours, known as breaking curves. Possible alignment combinations of the regions of each broken object are evaluated and the best one is selected as the final alignment. Experiments were carried out both on available 3D scanned objects and on a recent benchmark for synthetic broken objects. Results show that our solution performs well in reassembling different kinds of broken objects.
Identifying centres of interest in paintings using alignment and edge detection: Case studies on works by Luc Tuymans
Jan 04, 2021

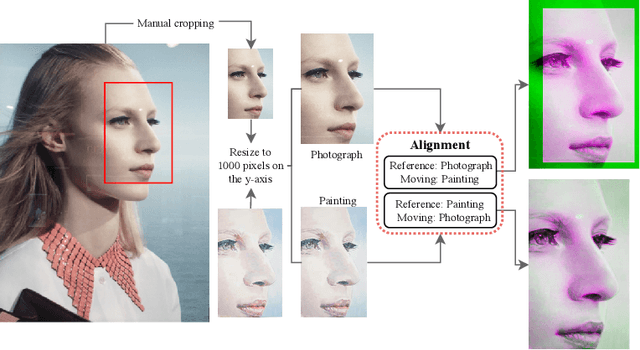

What is the creative process through which an artist goes from an original image to a painting? Can we examine this process using techniques from computer vision and pattern recognition? Here we set the first preliminary steps to algorithmically deconstruct some of the transformations that an artist applies to an original image in order to establish centres of interest, which are focal areas of a painting that carry meaning. We introduce a comparative methodology that first cuts out the minimal segment from the original image on which the painting is based, then aligns the painting with this source, investigates micro-differences to identify centres of interest and attempts to understand their role. In this paper we focus exclusively on micro-differences with respect to edges. We believe that research into where and how artists create centres of interest in paintings is valuable for curators, art historians, viewers, and art educators, and might even help artists to understand and refine their own artistic method.
Transductive Visual Verb Sense Disambiguation
Dec 20, 2020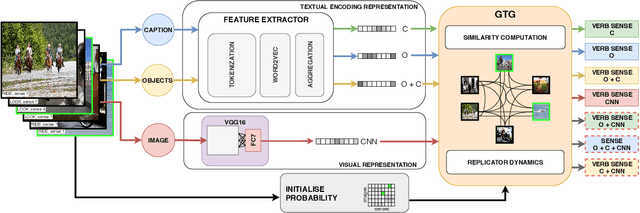
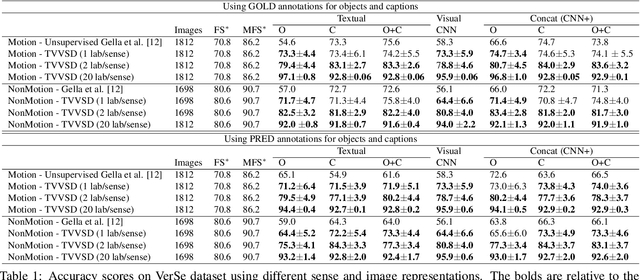
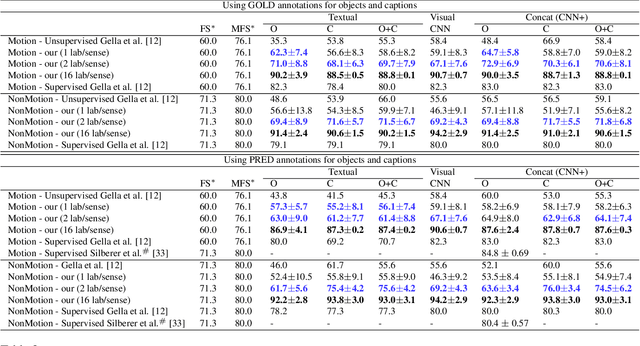
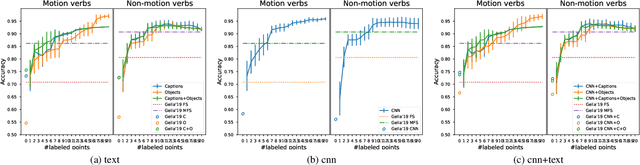
Verb Sense Disambiguation is a well-known task in NLP, the aim is to find the correct sense of a verb in a sentence. Recently, this problem has been extended in a multimodal scenario, by exploiting both textual and visual features of ambiguous verbs leading to a new problem, the Visual Verb Sense Disambiguation (VVSD). Here, the sense of a verb is assigned considering the content of an image paired with it rather than a sentence in which the verb appears. Annotating a dataset for this task is more complex than textual disambiguation, because assigning the correct sense to a pair of $<$image, verb$>$ requires both non-trivial linguistic and visual skills. In this work, differently from the literature, the VVSD task will be performed in a transductive semi-supervised learning (SSL) setting, in which only a small amount of labeled information is required, reducing tremendously the need for annotated data. The disambiguation process is based on a graph-based label propagation method which takes into account mono or multimodal representations for $<$image, verb$>$ pairs. Experiments have been carried out on the recently published dataset VerSe, the only available dataset for this task. The achieved results outperform the current state-of-the-art by a large margin while using only a small fraction of labeled samples per sense. Code available: https://github.com/GiBg1aN/TVVSD.
Neural Networks based approaches for Major Depressive Disorder and Bipolar Disorder Diagnosis using EEG signals: A review
Sep 28, 2020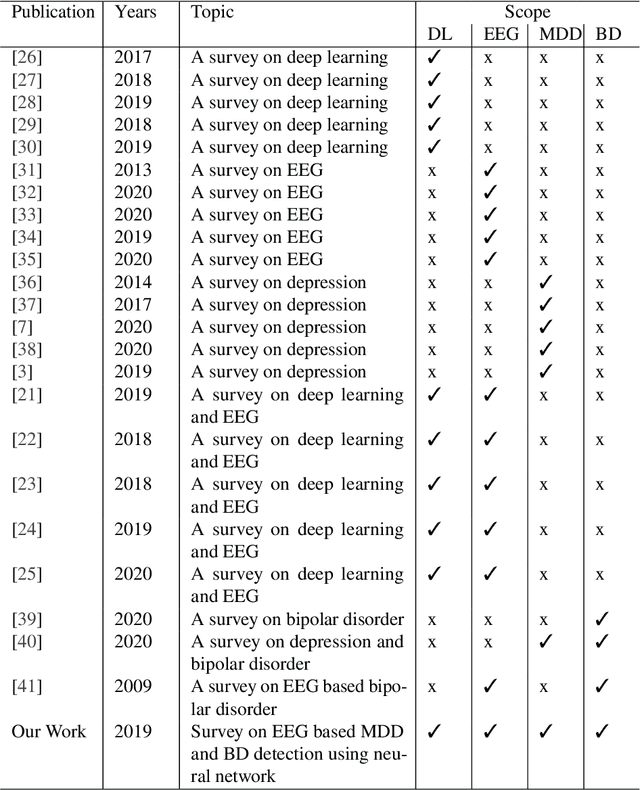
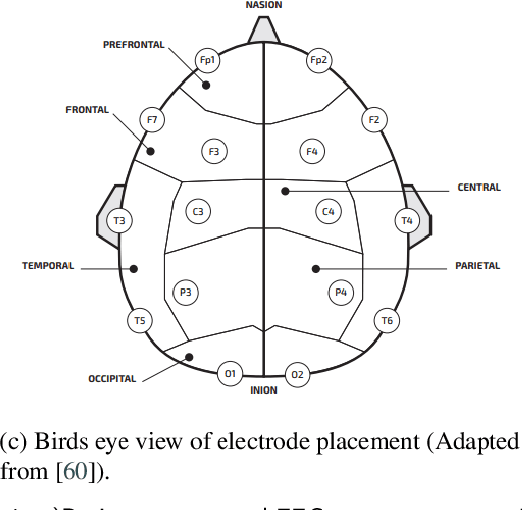
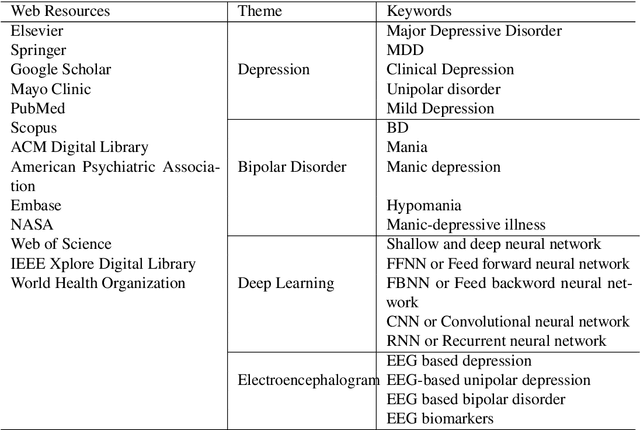
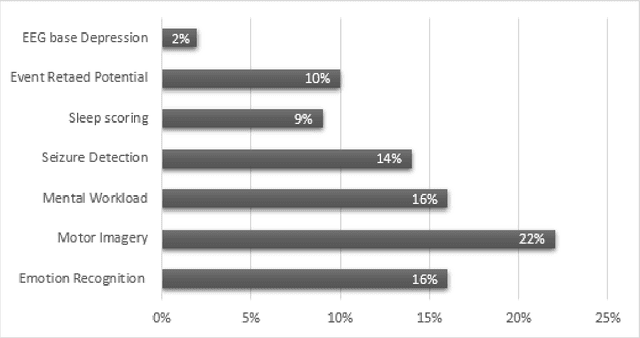
Mental disorders represent critical public health challenges as they are leading contributors to the global burden of disease and intensely influence social and financial welfare of individuals. The present comprehensive review concentrate on the two mental disorders: Major depressive Disorder (MDD) and Bipolar Disorder (BD) with noteworthy publications during the last ten years. There's a big need nowadays for phenotypic characterization of psychiatric disorders with biomarkers. Electroencephalography (EEG) signals could offer a rich signature for MDD and BD and then they could improve understanding of pathophysiological mechanisms underling these mental disorders. In this work, we focus on the literature works adopting neural networks fed by EEG signals. Among those studies using EEG and neural networks, we have discussed a variety of EEG based protocols, biomarkers and public datasets for depression and bipolar disorder detection. We conclude with a discussion and valuable recommendations that will help to improve the reliability of developed models and for more accurate and more deterministic computational intelligence based systems in psychiatry. This review will prove to be a structured and valuable initial point for the researchers working on depression and bipolar disorders recognition by using EEG signals.
CHAOS Challenge -- Combined (CT-MR) Healthy Abdominal Organ Segmentation
Jan 17, 2020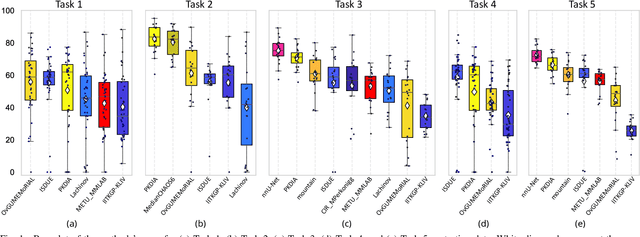
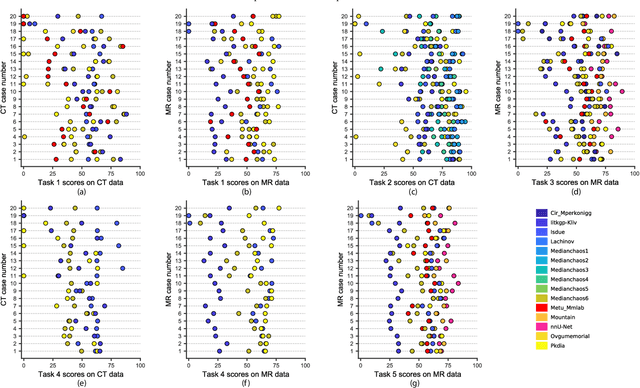
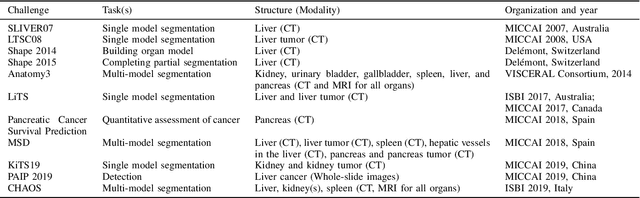
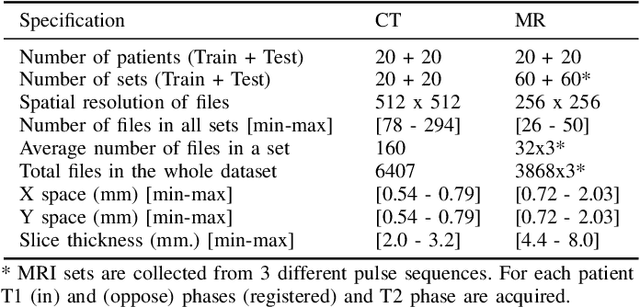
Segmentation of abdominal organs has been a comprehensive, yet unresolved, research field for many years. In the last decade, intensive developments in deep learning (DL) have introduced new state-of-the-art segmentation systems. Despite outperforming the overall accuracy of existing systems, the effects of DL model properties and parameters on the performance is hard to interpret. This makes comparative analysis a necessary tool to achieve explainable studies and systems. Moreover, the performance of DL for emerging learning approaches such as cross-modality and multi-modal tasks have been rarely discussed. In order to expand the knowledge in these topics, CHAOS -- Combined (CT-MR) Healthy Abdominal Organ Segmentation challenge has been organized in the IEEE International Symposium on Biomedical Imaging (ISBI), 2019, in Venice, Italy. Despite a large number of the previous abdomen related challenges, the majority of which are focused on tumor/lesion detection and/or classification with a single modality, CHAOS provides both abdominal CT and MR data from healthy subjects. Five different and complementary tasks have been designed to analyze the capabilities of the current approaches from multiple perspectives. The results are investigated thoroughly, compared with manual annotations and interactive methods. The outcomes are reported in detail to reflect the latest advancements in the field. CHAOS challenge and data will be available online to provide a continuous benchmark resource for segmentation.
Weakly Supervised Semantic Segmentation Using Constrained Dominant Sets
Sep 20, 2019


The availability of large-scale data sets is an essential pre-requisite for deep learning based semantic segmentation schemes. Since obtaining pixel-level labels is extremely expensive, supervising deep semantic segmentation networks using low-cost weak annotations has been an attractive research problem in recent years. In this work, we explore the potential of Constrained Dominant Sets (CDS) for generating multi-labeled full mask predictions to train a fully convolutional network (FCN) for semantic segmentation. Our experimental results show that using CDS's yields higher-quality mask predictions compared to methods that have been adopted in the literature for the same purpose.
Unsupervised Domain Adaptation using Graph Transduction Games
May 06, 2019



Unsupervised domain adaptation (UDA) amounts to assigning class labels to the unlabeled instances of a dataset from a target domain, using labeled instances of a dataset from a related source domain. In this paper, we propose to cast this problem in a game-theoretic setting as a non-cooperative game and introduce a fully automatized iterative algorithm for UDA based on graph transduction games (GTG). The main advantages of this approach are its principled foundation, guaranteed termination of the iterative algorithms to a Nash equilibrium (which corresponds to a consistent labeling condition) and soft labels quantifying the uncertainty of the label assignment process. We also investigate the beneficial effect of using pseudo-labels from linear classifiers to initialize the iterative process. The performance of the resulting methods is assessed on publicly available object recognition benchmark datasets involving both shallow and deep features. Results of experiments demonstrate the suitability of the proposed game-theoretic approach for solving UDA tasks.
Unobtrusive and Multimodal Approach for Behavioral Engagement Detection of Students
Jan 16, 2019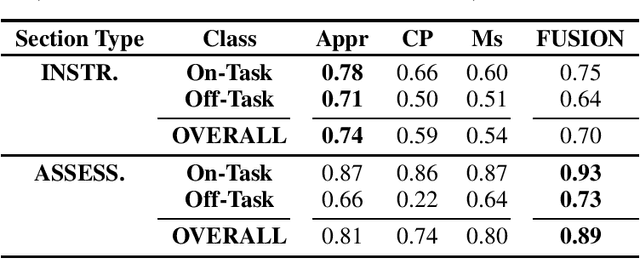
We propose a multimodal approach for detection of students' behavioral engagement states (i.e., On-Task vs. Off-Task), based on three unobtrusive modalities: Appearance, Context-Performance, and Mouse. Final behavioral engagement states are achieved by fusing modality-specific classifiers at the decision level. Various experiments were conducted on a student dataset collected in an authentic classroom.