 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view analysis of unregistered medical images using cross-view transformers
Mar 21, 2021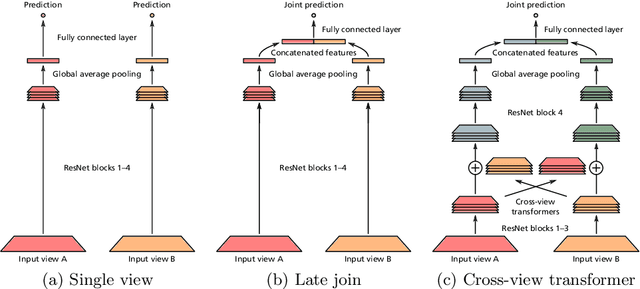

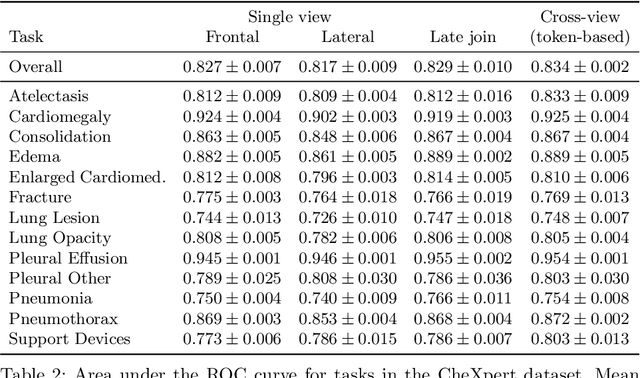
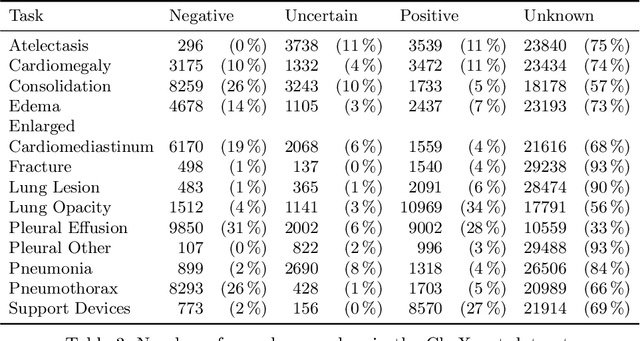
Multi-view medical image analysis often depends on the combination of information from multiple views. However, differences in perspective or other forms of misalignment can make it difficult to combine views effectively, as registration is not always possible. Without registration, views can only be combined at a global feature level, by joining feature vectors after global pooling. We present a novel cross-view transformer method to transfer information between unregistered views at the level of spatial feature maps. We demonstrate this method on multi-view mammography and chest X-ray datasets. On both datasets, we find that a cross-view transformer that links spatial feature maps can outperform a baseline model that joins feature vectors after global pooling.
Skewed Laplace Spectral Mixture kernels for long-term forecasting in Gaussian process
Nov 08, 2020
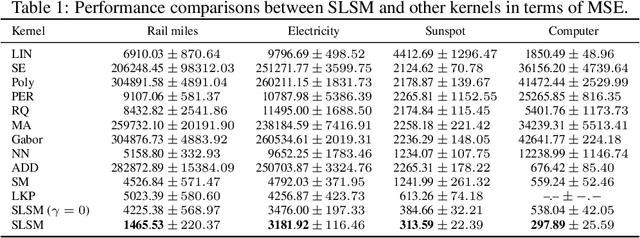

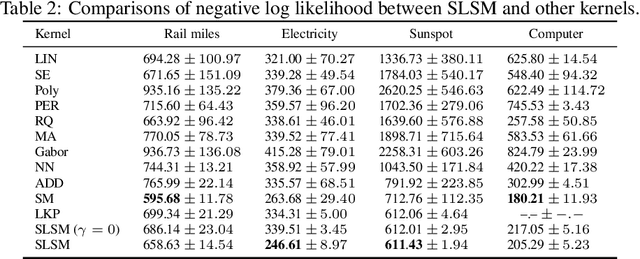
Long-term forecasting involves predicting a horizon that is far ahead of the last observation. It is a problem of highly practical relevance, for instance for companies in order to decide upon expensive long-term investments. Despite recent progress and success of Gaussian Processes (GPs) based on Spectral Mixture kernels, long-term forecasting remains a challenging problem for these kernels because they decay exponentially at large horizons. This is mainly due their use of a mixture of Gaussians to model spectral densities. The challenges underlying long-term forecasting become evident by investigating the distribution of the Fourier coefficients of (the training part of) the signal, which is non-smooth, heavy-tailed, sparse and skewed. Notably the heavy tail and skewness characteristics of such distribution in spectral domain allow to capture long range covariance of the signal in the time domain. Motivated by these observations, we propose to model spectral densities using a Skewed Laplace Spectral Mixture (SLSM) due to the skewness of its peaks, sparsity, non-smoothness, and heavy tail characteristics. By applying the inverse Fourier Transform to this spectral density we obtain a new GP kernel for long-term forecasting. Results of extensive experiments, including a multivariate time series, show the beneficial effect of the proposed SLSM kernel for long-term extrapolation and robustness to the choice of the number of mixture components.
Unsupervised Domain Adaptation using Graph Transduction Games
May 06, 2019



Unsupervised domain adaptation (UDA) amounts to assigning class labels to the unlabeled instances of a dataset from a target domain, using labeled instances of a dataset from a related source domain. In this paper, we propose to cast this problem in a game-theoretic setting as a non-cooperative game and introduce a fully automatized iterative algorithm for UDA based on graph transduction games (GTG). The main advantages of this approach are its principled foundation, guaranteed termination of the iterative algorithms to a Nash equilibrium (which corresponds to a consistent labeling condition) and soft labels quantifying the uncertainty of the label assignment process. We also investigate the beneficial effect of using pseudo-labels from linear classifiers to initialize the iterative process. The performance of the resulting methods is assessed on publicly available object recognition benchmark datasets involving both shallow and deep features. Results of experiments demonstrate the suitability of the proposed game-theoretic approach for solving UDA tasks.
Spectral Mixture Kernels with Time and Phase Delay Dependencies
Oct 14, 2018
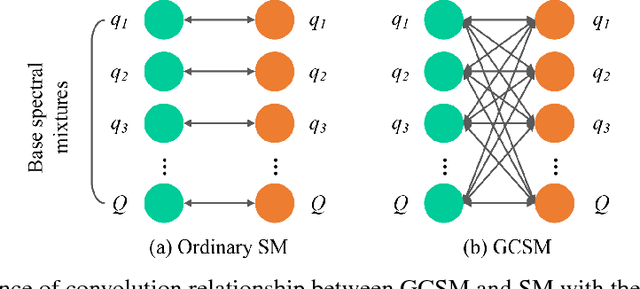
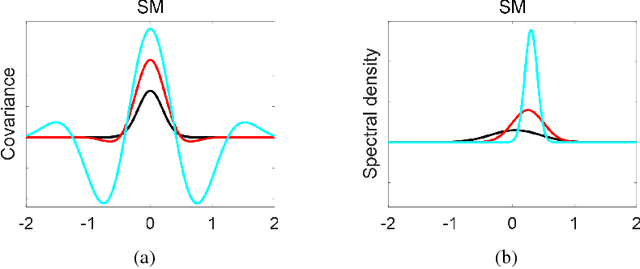
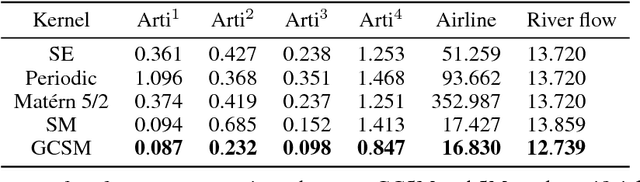
Spectral Mixture (SM) kernels form a powerful class of kernels for Gaussian processes, capable to discover patterns, extrapolate, and model negative co-variances. In SM kernels, spectral mixture components are linearly combined to construct a final flexible kernel. As a consequence SM kernels does not explicitly model correlations between components and dependencies related to time and phase delays between components, because only the auto-convolution of base components are used. To address these drawbacks we introduce Generalized Convolution Spectral Mixture (GCSM) kernels. We incorporate time and phase delay into the base spectral mixture and use cross-convolution between a base component and the complex conjugate of another base component to construct a complex-valued and positive definite kernel representing correlations between base components. In this way the total number of components in GCSM becomes quadratic. We perform a thorough comparative experimental analysis of GCSM on synthetic and real-life datasets. Results indicate the beneficial effect of the extra features of GCSM. This is illustrated in the problem of forecasting the long range trend of a river flow to monitor environment evolution, where GCSM is capable of discovering correlated patterns that SM cannot and improving patterns recognition ability of SM.
Multi-Output Convolution Spectral Mixture for Gaussian Processes
Oct 14, 2018
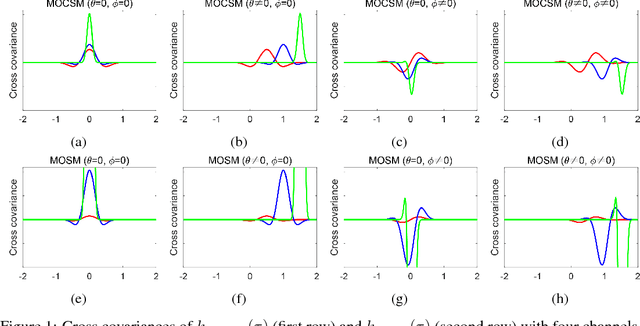
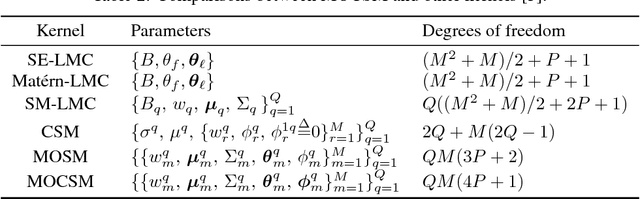
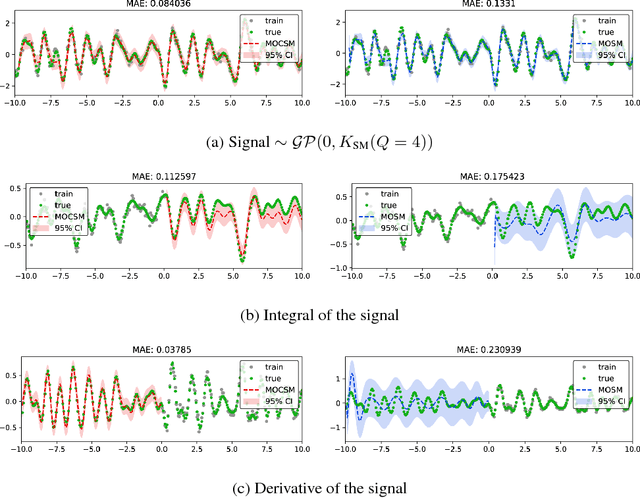
Multi-output Gaussian processes (MOGPs) are recently extended by using spectral mixture kernel, which enables expressively pattern extrapolation with a strong interpretation. In particular, Multi-Output Spectral Mixture kernel (MOSM) is a recent, powerful state of the art method. However, MOSM cannot reduce to the ordinary spectral mixture kernel (SM) when using a single channel. Moreover, when the spectral density of different channels is either very close or very far from each other in the frequency domain, MOSM generates unreasonable scale effects on cross weights which produces an incorrect description of the channel correlation structure. In this paper, we tackle these drawbacks and introduce a principled multi-output convolution spectral mixture kernel (MOCSM) framework. In our framework, we model channel dependencies through convolution of time and phase delayed spectral mixtures between different channels. Results of extensive experiments on synthetic and real datasets demontrate the advantages of MOCSM and its state of the art performance.
Generalized Spectral Mixture Kernels for Multi-Task Gaussian Processes
Oct 14, 2018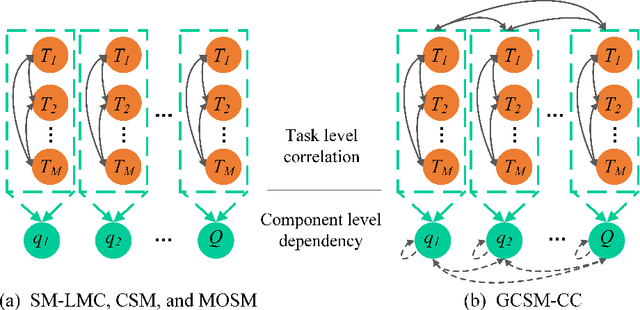

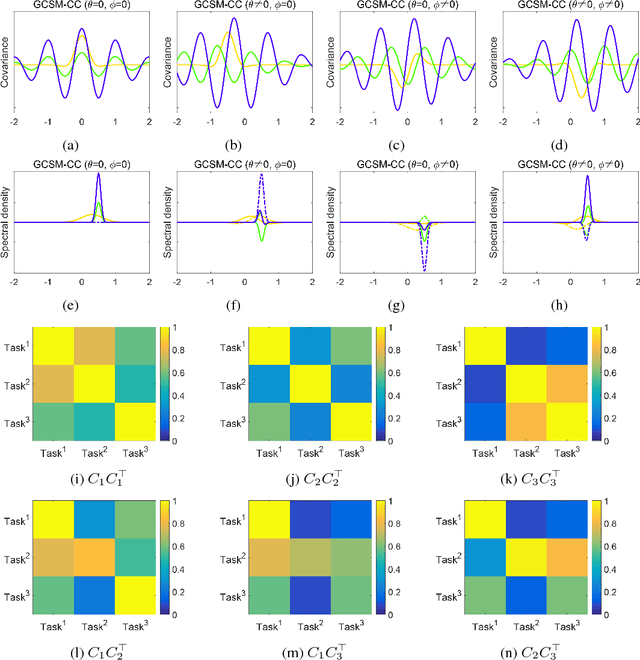

Multi-Task Gaussian processes (MTGPs) have shown a significant progress both in expressiveness and interpretation of the relatedness between different tasks: from linear combinations of independent single-output Gaussian processes (GPs), through the direct modeling of the cross-covariances such as spectral mixture kernels with phase shift, to the design of multivariate covariance functions based on spectral mixture kernels which model delays among tasks in addition to phase differences, and which provide a parametric interpretation of the relatedness across tasks. In this paper we further extend expressiveness and interpretability of MTGPs models and introduce a new family of kernels capable to model nonlinear correlations between tasks as well as dependencies between spectral mixtures, including time and phase delay. Specifically, we use generalized convolution spectral mixture kernels for modeling dependencies at spectral mixture level, and coupling coregionalization for discovering task level correlations. The proposed kernels for MTGP are validated on artificial data and compared with existing MTGPs methods on three real-world experiments. Results indicate the benefits of our more expressive representation with respect to performance and interpretability.
Vendor-independent soft tissue lesion detection using weakly supervised and unsupervised adversarial domain adaptation
Aug 14, 2018Computer-aided detection aims to improve breast cancer screening programs by helping radiologists to evaluate digital mammography (DM) exams. DM exams are generated by devices from different vendors, with diverse characteristics between and even within vendors. Physical properties of these devices and postprocessing of the images can greatly influence the resulting mammogram. This results in the fact that a deep learning model trained on data from one vendor cannot readily be applied to data from another vendor. This paper investigates the use of tailored transfer learning methods based on adversarial learning to tackle this problem. We consider a database of DM exams (mostly bilateral and two views) generated by Hologic and Siemens vendors. We analyze two transfer learning settings: 1) unsupervised transfer, where Hologic data with soft lesion annotation at pixel level and Siemens unlabelled data are used to annotate images in the latter data; 2) weak supervised transfer, where exam level labels for images from the Siemens mammograph are available. We propose tailored variants of recent state-of-the-art methods for transfer learning which take into account the class imbalance and incorporate knowledge provided by the annotations at exam level. Results of experiments indicate the beneficial effect of transfer learning in both transfer settings. Notably, at 0.02 false positives per image, we achieve a sensitivity of 0.37, compared to 0.30 of a baseline with no transfer. Results indicate that using exam level annotations gives an additional increase in sensitivity.
Spectral-spatial classification of hyperspectral images: three tricks and a new supervised learning setting
Jul 23, 2018

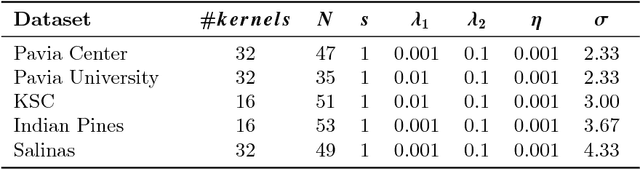
Spectral-spatial classification of hyperspectral images has been the subject of many studies in recent years. In the presence of only very few labeled pixels, this task becomes challenging. In this paper we address the following two research questions: 1) Can a simple neural network with just a single hidden layer achieve state of the art performance in the presence of few labeled pixels? 2) How is the performance of hyperspectral image classification methods affected when using disjoint train and test sets? We give a positive answer to the first question by using three tricks within a very basic shallow Convolutional Neural Network (CNN) architecture: a tailored loss function, and smooth- and label-based data augmentation. The tailored loss function enforces that neighborhood wavelengths have similar contributions to the features generated during training. A new label-based technique here proposed favors selection of pixels in smaller classes, which is beneficial in the presence of very few labeled pixels and skewed class distributions. To address the second question, we introduce a new sampling procedure to generate disjoint train and test set. Then the train set is used to obtain the CNN model, which is then applied to pixels in the test set to estimate their labels. We assess the efficacy of the simple neural network method on five publicly available hyperspectral images. On these images our method significantly outperforms considered baselines. Notably, with just 1% of labeled pixels per class, on these datasets our method achieves an accuracy that goes from 86.42% (challenging dataset) to 99.52% (easy dataset). Furthermore we show that the simple neural network method improves over other baselines in the new challenging supervised setting. Our analysis substantiates the highly beneficial effect of using the entire image (so train and test data) for constructing a model.
Simple Domain Adaptation with Class Prediction Uncertainty Alignment
Apr 12, 2018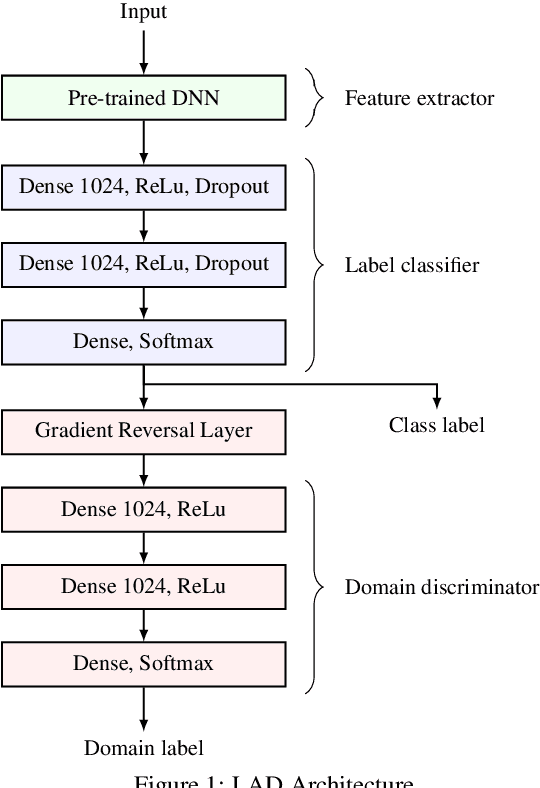
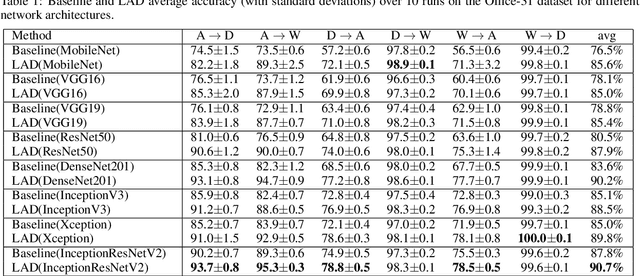
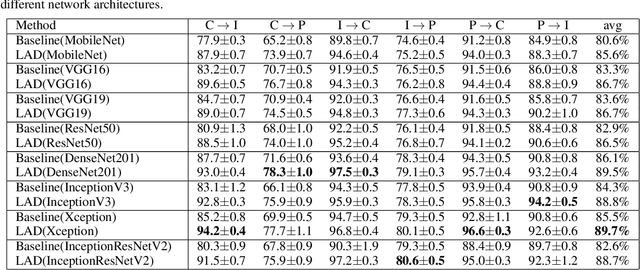
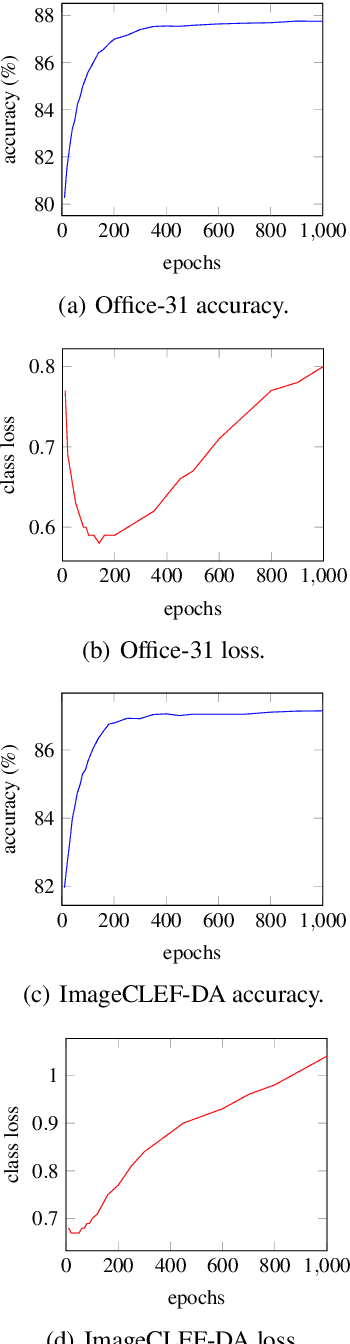
Unsupervised domain adaptation tries to adapt a classifier trained on a labeled source domain to a related but unlabeled target domain. Methods based on adversarial learning try to learn a representation that is at the same time discriminative for the labels yet incapable of discriminating the domains. We propose a very simple and efficient method based on this approach which only aligns predicted class probabilities across domains. Experiments show that this strikingly simple adversarial domain adaptation method is robust to overfitting and achieves state-of-the-art results on datasets for image classification.
Domain Adaptation with Randomized Expectation Maximization
Mar 20, 2018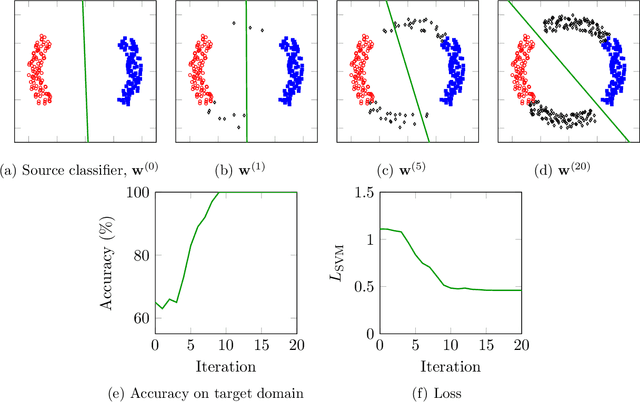



Domain adaptation (DA) is the task of classifying an unlabeled dataset (target) using a labeled dataset (source) from a related domain. The majority of successful DA methods try to directly match the distributions of the source and target data by transforming the feature space. Despite their success, state of the art methods based on this approach are either involved or unable to directly scale to data with many features. This article shows that domain adaptation can be successfully performed by using a very simple randomized expectation maximization (EM) method. We consider two instances of the method, which involve logistic regression and support vector machine, respectively. The underlying assumption of the proposed method is the existence of a good single linear classifier for both source and target domain. The potential limitations of this assumption are alleviated by the flexibility of the method, which can directly incorporate deep features extracted from a pre-trained deep neural network. The resulting algorithm is strikingly easy to implement and apply. We test its performance on 36 real-life adaptation tasks over text and image data with diverse characteristics. The method achieves state-of-the-art results, competitive with those of involved end-to-end deep transfer-learning methods.