 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing Grayscale: The Road to Understanding and Improving Unlearnable Examples
Nov 25, 2021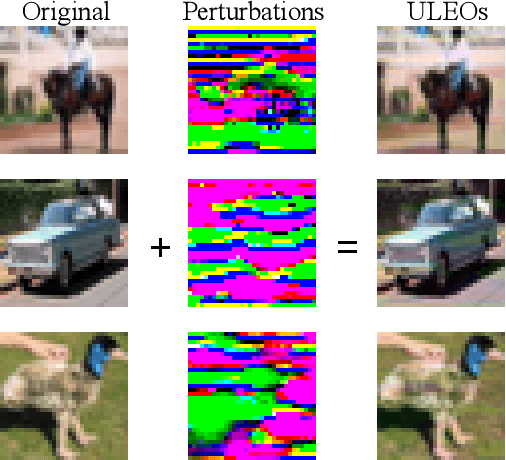
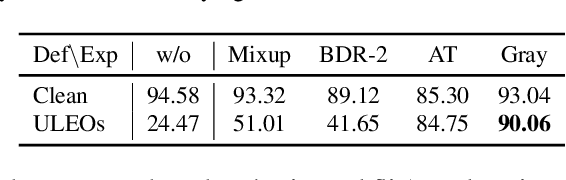
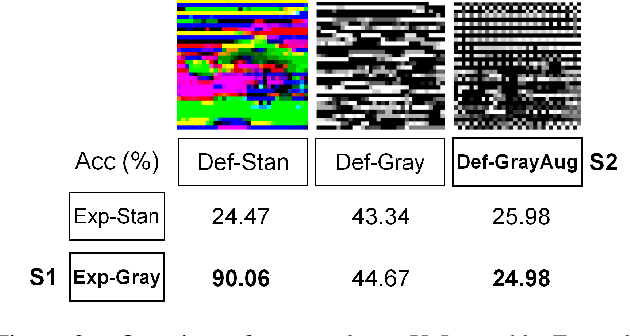
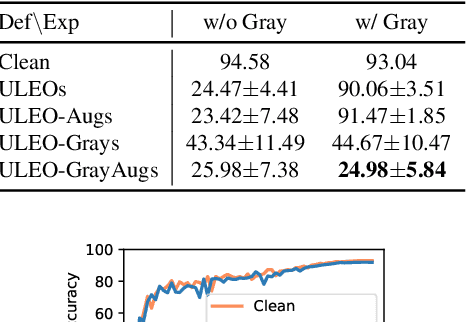
Recent work has shown that imperceptible perturbations can be applied to craft unlearnable examples (ULEs), i.e. images whose content cannot be used to improve a classifier during training. In this paper, we reveal the road that researchers should follow for understanding ULEs and improving ULEs as they were originally formulated (ULEOs). The paper makes four contributions. First, we show that ULEOs exploit color and, consequently, their effects can be mitigated by simple grayscale pre-filtering, without resorting to adversarial training. Second, we propose an extension to ULEOs, which is called ULEO-GrayAugs, that forces the generated ULEs away from channel-wise color perturbations by making use of grayscale knowledge and data augmentations during optimization. Third, we show that ULEOs generated using Multi-Layer Perceptrons (MLPs) are effective in the case of complex Convolutional Neural Network (CNN) classifiers, suggesting that CNNs suffer specific vulnerability to ULEs. Fourth, we demonstrate that when a classifier is trained on ULEOs, adversarial training will prevent a drop in accuracy measured both on clean images and on adversarial images. Taken together, our contributions represent a substantial advance in the state of art of unlearnable examples, but also reveal important characteristics of their behavior that must be better understood in order to achieve further improvements.
Swift sky localization of gravitational waves using deep learning seeded importance sampling
Nov 01, 2021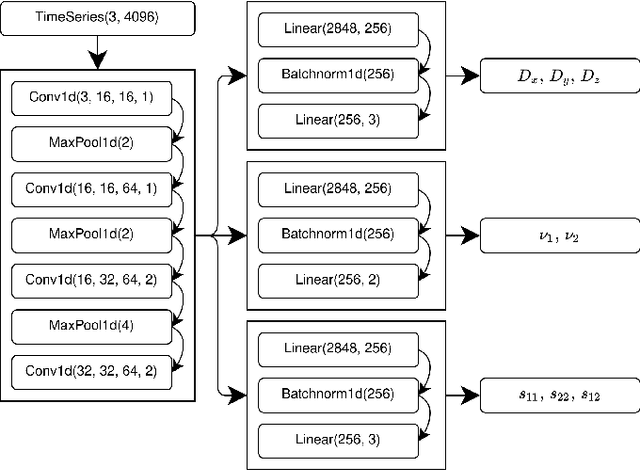
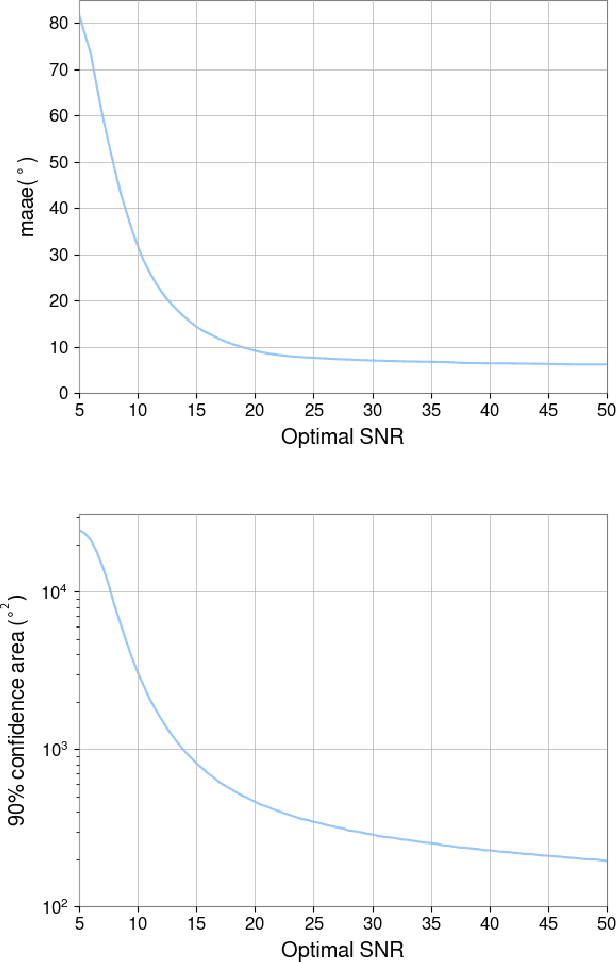
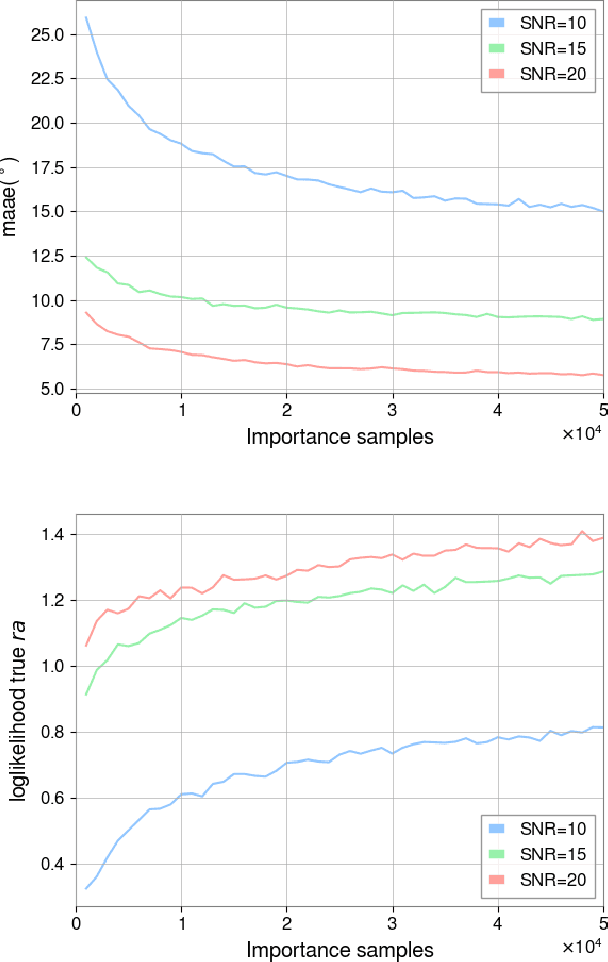
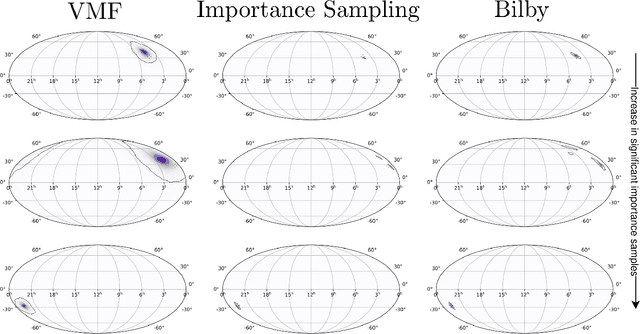
Fast, highly accurate, and reliable inference of the sky origin of gravitational waves would enable real-time multi-messenger astronomy. Current Bayesian inference methodologies, although highly accurate and reliable, are slow. Deep learning models have shown themselves to be accurate and extremely fast for inference tasks on gravitational waves, but their output is inherently questionable due to the blackbox nature of neural networks. In this work, we join Bayesian inference and deep learning by applying importance sampling on an approximate posterior generated by a multi-headed convolutional neural network. The neural network parametrizes Von Mises-Fisher and Gaussian distributions for the sky coordinates and two masses for given simulated gravitational wave injections in the LIGO and Virgo detectors. We generate skymaps for unseen gravitational-wave events that highly resemble predictions generated using Bayesian inference in a few minutes. Furthermore, we can detect poor predictions from the neural network, and quickly flag them.
Skewed Laplace Spectral Mixture kernels for long-term forecasting in Gaussian process
Nov 08, 2020
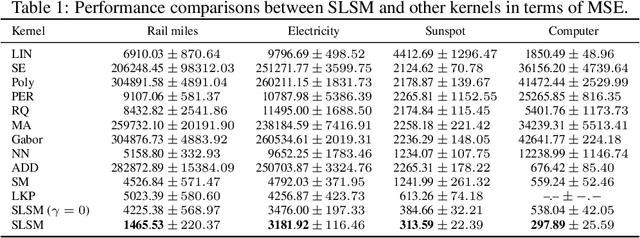

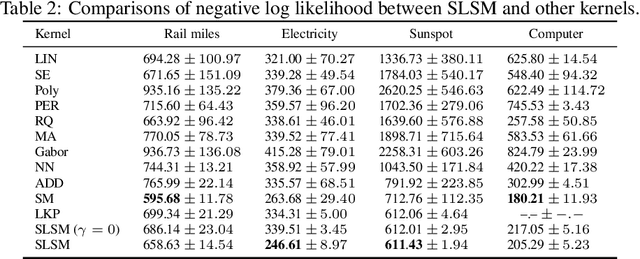
Long-term forecasting involves predicting a horizon that is far ahead of the last observation. It is a problem of highly practical relevance, for instance for companies in order to decide upon expensive long-term investments. Despite recent progress and success of Gaussian Processes (GPs) based on Spectral Mixture kernels, long-term forecasting remains a challenging problem for these kernels because they decay exponentially at large horizons. This is mainly due their use of a mixture of Gaussians to model spectral densities. The challenges underlying long-term forecasting become evident by investigating the distribution of the Fourier coefficients of (the training part of) the signal, which is non-smooth, heavy-tailed, sparse and skewed. Notably the heavy tail and skewness characteristics of such distribution in spectral domain allow to capture long range covariance of the signal in the time domain. Motivated by these observations, we propose to model spectral densities using a Skewed Laplace Spectral Mixture (SLSM) due to the skewness of its peaks, sparsity, non-smoothness, and heavy tail characteristics. By applying the inverse Fourier Transform to this spectral density we obtain a new GP kernel for long-term forecasting. Results of extensive experiments, including a multivariate time series, show the beneficial effect of the proposed SLSM kernel for long-term extrapolation and robustness to the choice of the number of mixture components.
Unsupervised Domain Adaptation using Graph Transduction Games
May 06, 2019



Unsupervised domain adaptation (UDA) amounts to assigning class labels to the unlabeled instances of a dataset from a target domain, using labeled instances of a dataset from a related source domain. In this paper, we propose to cast this problem in a game-theoretic setting as a non-cooperative game and introduce a fully automatized iterative algorithm for UDA based on graph transduction games (GTG). The main advantages of this approach are its principled foundation, guaranteed termination of the iterative algorithms to a Nash equilibrium (which corresponds to a consistent labeling condition) and soft labels quantifying the uncertainty of the label assignment process. We also investigate the beneficial effect of using pseudo-labels from linear classifiers to initialize the iterative process. The performance of the resulting methods is assessed on publicly available object recognition benchmark datasets involving both shallow and deep features. Results of experiments demonstrate the suitability of the proposed game-theoretic approach for solving UDA tasks.
Spectral-spatial classification of hyperspectral images: three tricks and a new supervised learning setting
Jul 23, 2018

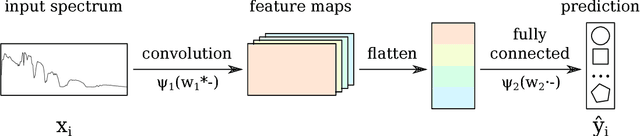
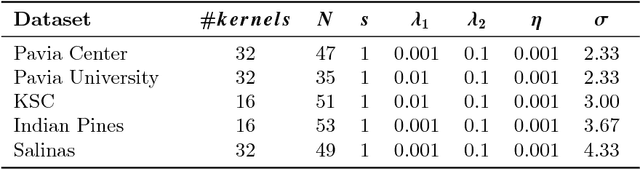
Spectral-spatial classification of hyperspectral images has been the subject of many studies in recent years. In the presence of only very few labeled pixels, this task becomes challenging. In this paper we address the following two research questions: 1) Can a simple neural network with just a single hidden layer achieve state of the art performance in the presence of few labeled pixels? 2) How is the performance of hyperspectral image classification methods affected when using disjoint train and test sets? We give a positive answer to the first question by using three tricks within a very basic shallow Convolutional Neural Network (CNN) architecture: a tailored loss function, and smooth- and label-based data augmentation. The tailored loss function enforces that neighborhood wavelengths have similar contributions to the features generated during training. A new label-based technique here proposed favors selection of pixels in smaller classes, which is beneficial in the presence of very few labeled pixels and skewed class distributions. To address the second question, we introduce a new sampling procedure to generate disjoint train and test set. Then the train set is used to obtain the CNN model, which is then applied to pixels in the test set to estimate their labels. We assess the efficacy of the simple neural network method on five publicly available hyperspectral images. On these images our method significantly outperforms considered baselines. Notably, with just 1% of labeled pixels per class, on these datasets our method achieves an accuracy that goes from 86.42% (challenging dataset) to 99.52% (easy dataset). Furthermore we show that the simple neural network method improves over other baselines in the new challenging supervised setting. Our analysis substantiates the highly beneficial effect of using the entire image (so train and test data) for constructing a model.
Generative models for local network community detection
Apr 12, 2018


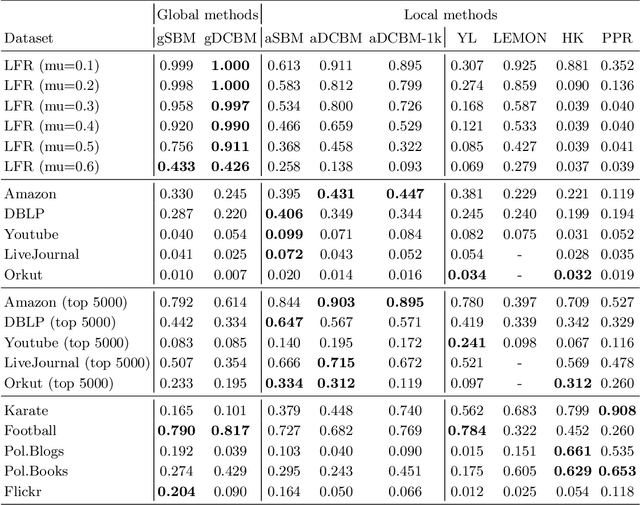
Local network community detection aims to find a single community in a large network, while inspecting only a small part of that network around a given seed node. This is much cheaper than finding all communities in a network. Most methods for local community detection are formulated as ad-hoc optimization problems. In this work, we instead start from a generative model for networks with community structure. By assuming that the network is uniform, we can approximate the structure of unobserved parts of the network to obtain a method for local community detection. We apply this local approximation technique to two variants of the stochastic block model. To our knowledge, this results in the first local community detection methods based on probabilistic models. Interestingly, in the limit, one of the proposed approximations corresponds to conductance, a popular metric in this field. Experiments on real and synthetic datasets show comparable or improved results compared to state-of-the-art local community detection algorithms.
Simple Domain Adaptation with Class Prediction Uncertainty Alignment
Apr 12, 2018
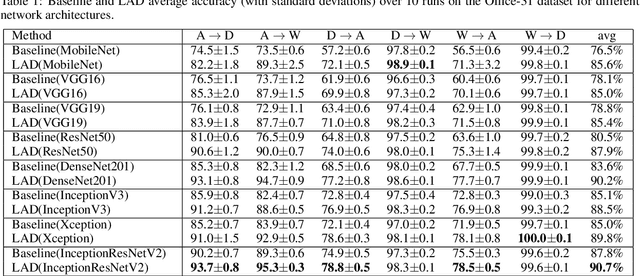
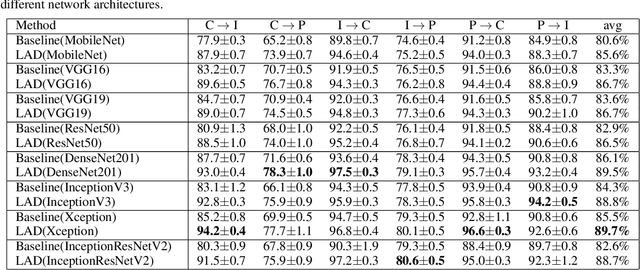
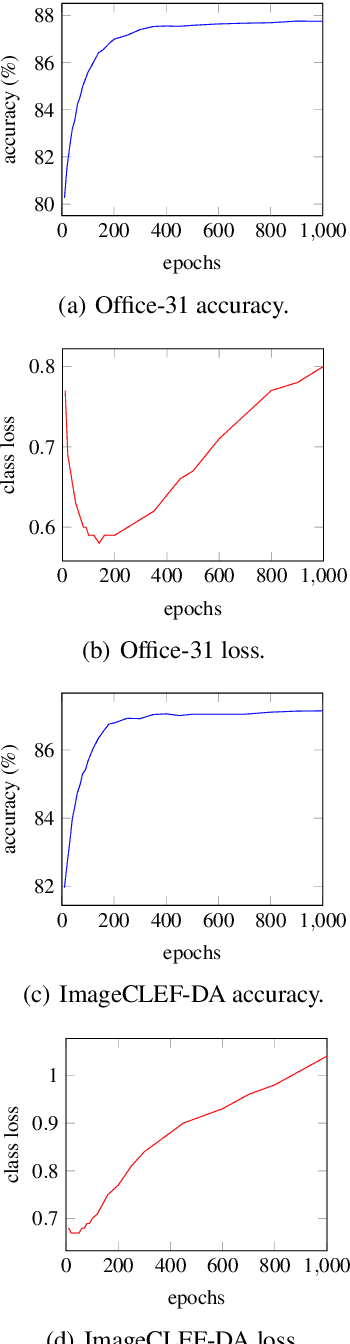
Unsupervised domain adaptation tries to adapt a classifier trained on a labeled source domain to a related but unlabeled target domain. Methods based on adversarial learning try to learn a representation that is at the same time discriminative for the labels yet incapable of discriminating the domains. We propose a very simple and efficient method based on this approach which only aligns predicted class probabilities across domains. Experiments show that this strikingly simple adversarial domain adaptation method is robust to overfitting and achieves state-of-the-art results on datasets for image classification.
Domain Adaptation with Randomized Expectation Maximization
Mar 20, 2018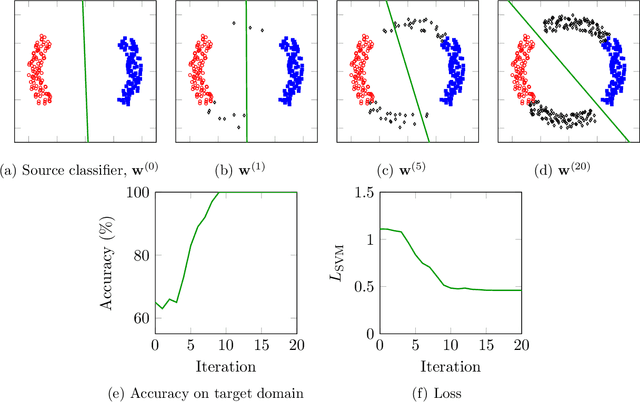



Domain adaptation (DA) is the task of classifying an unlabeled dataset (target) using a labeled dataset (source) from a related domain. The majority of successful DA methods try to directly match the distributions of the source and target data by transforming the feature space. Despite their success, state of the art methods based on this approach are either involved or unable to directly scale to data with many features. This article shows that domain adaptation can be successfully performed by using a very simple randomized expectation maximization (EM) method. We consider two instances of the method, which involve logistic regression and support vector machine, respectively. The underlying assumption of the proposed method is the existence of a good single linear classifier for both source and target domain. The potential limitations of this assumption are alleviated by the flexibility of the method, which can directly incorporate deep features extracted from a pre-trained deep neural network. The resulting algorithm is strikingly easy to implement and apply. We test its performance on 36 real-life adaptation tasks over text and image data with diverse characteristics. The method achieves state-of-the-art results, competitive with those of involved end-to-end deep transfer-learning methods.
Unsupervised Domain Adaptation with Random Walks on Target Labelings
Mar 20, 2018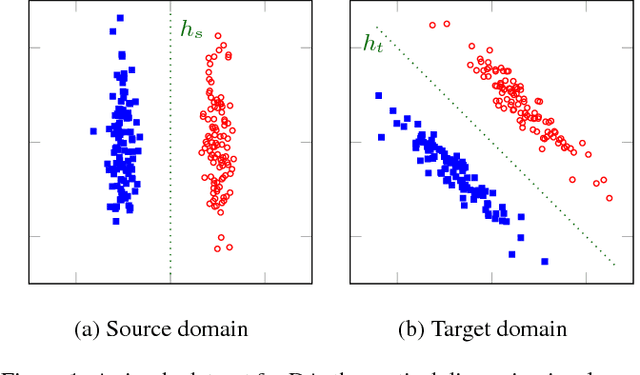
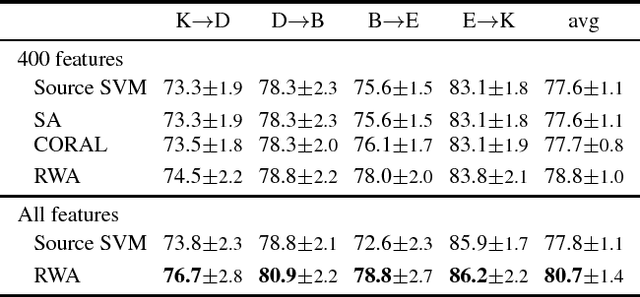
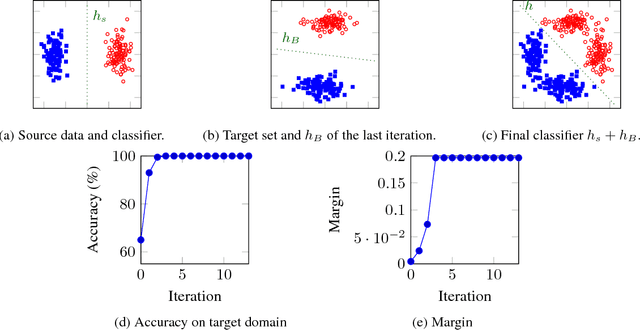
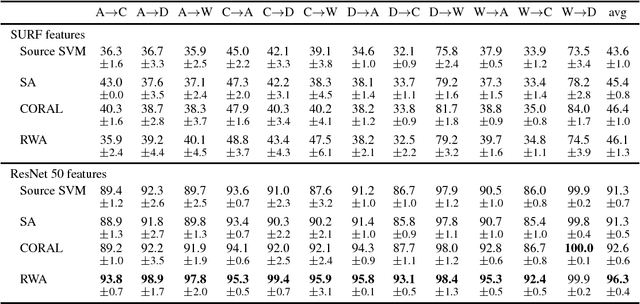
Unsupervised Domain Adaptation (DA) is used to automatize the task of labeling data: an unlabeled dataset (target) is annotated using a labeled dataset (source) from a related domain. We cast domain adaptation as the problem of finding stable labels for target examples. A new definition of label stability is proposed, motivated by a generalization error bound for large margin linear classifiers: a target labeling is stable when, with high probability, a classifier trained on a random subsample of the target with that labeling yields the same labeling. We find stable labelings using a random walk on a directed graph with transition probabilities based on labeling stability. The majority vote of those labelings visited by the walk yields a stable label for each target example. The resulting domain adaptation algorithm is strikingly easy to implement and apply: It does not rely on data transformations, which are in general computational prohibitive in the presence of many input features, and does not need to access the source data, which is advantageous when data sharing is restricted. By acting on the original feature space, our method is able to take full advantage of deep features from external pre-trained neural networks, as demonstrated by the results of our experiments.
Deep Learning for Automatic Stereotypical Motor Movement Detection using Wearable Sensors in Autism Spectrum Disorders
Sep 14, 2017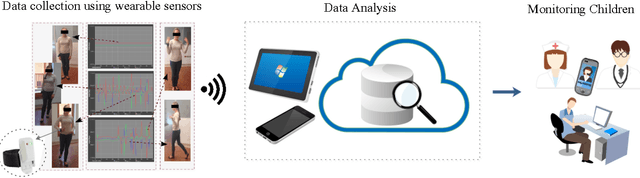
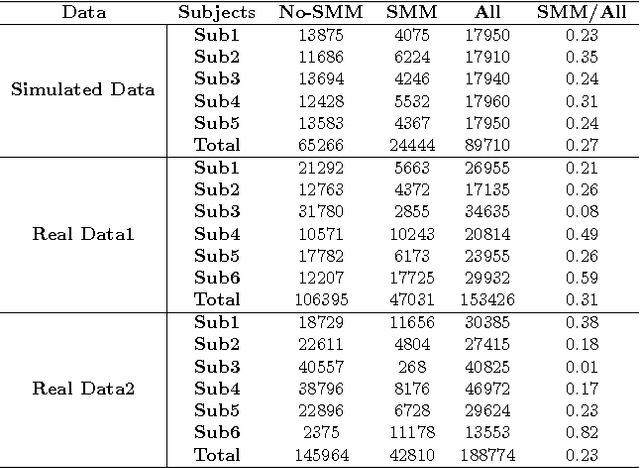
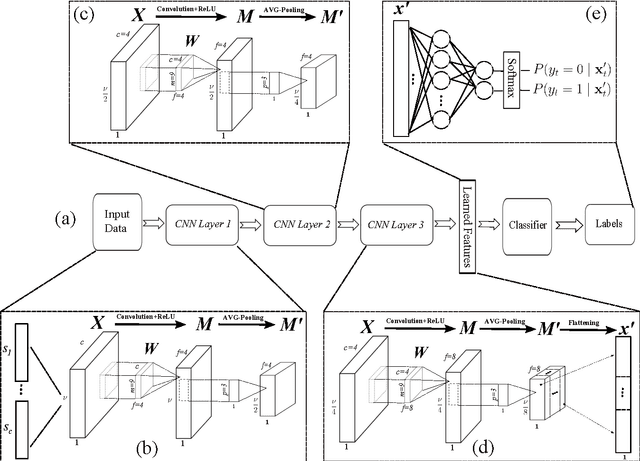
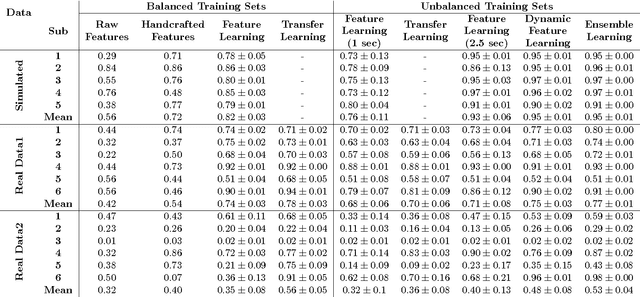
Autism Spectrum Disorders are associated with atypical movements, of which stereotypical motor movements (SMMs) interfere with learning and social interaction. The automatic SMM detection using inertial measurement units (IMU) remains complex due to the strong intra and inter-subject variability, especially when handcrafted features are extracted from the signal. We propose a new application of the deep learning to facilitate automatic SMM detection using multi-axis IMUs. We use a convolutional neural network (CNN) to learn a discriminative feature space from raw data. We show how the CNN can be used for parameter transfer learning to enhance the detection rate on longitudinal data. We also combine the long short-term memory (LSTM) with CNN to model the temporal patterns in a sequence of multi-axis signals. Further, we employ ensemble learning to combine multiple LSTM learners into a more robust SMM detector. Our results show that: 1) feature learning outperforms handcrafted features; 2) parameter transfer learning is beneficial in longitudinal settings; 3) using LSTM to learn the temporal dynamic of signals enhances the detection rate especially for skewed training data; 4) an ensemble of LSTMs provides more accurate and stable detectors. These findings provide a significant step toward accurate SMM detection in real-time scenarios.