 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral-spatial classification of hyperspectral images: three tricks and a new supervised learning setting
Paper and Code


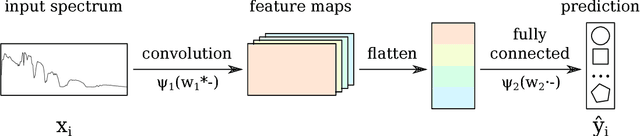
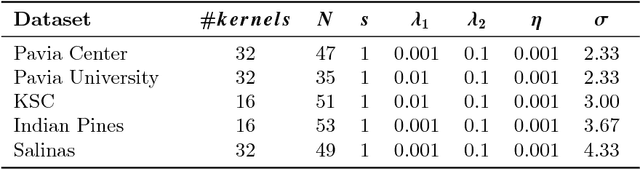
Spectral-spatial classification of hyperspectral images has been the subject of many studies in recent years. In the presence of only very few labeled pixels, this task becomes challenging. In this paper we address the following two research questions: 1) Can a simple neural network with just a single hidden layer achieve state of the art performance in the presence of few labeled pixels? 2) How is the performance of hyperspectral image classification methods affected when using disjoint train and test sets? We give a positive answer to the first question by using three tricks within a very basic shallow Convolutional Neural Network (CNN) architecture: a tailored loss function, and smooth- and label-based data augmentation. The tailored loss function enforces that neighborhood wavelengths have similar contributions to the features generated during training. A new label-based technique here proposed favors selection of pixels in smaller classes, which is beneficial in the presence of very few labeled pixels and skewed class distributions. To address the second question, we introduce a new sampling procedure to generate disjoint train and test set. Then the train set is used to obtain the CNN model, which is then applied to pixels in the test set to estimate their labels. We assess the efficacy of the simple neural network method on five publicly available hyperspectral images. On these images our method significantly outperforms considered baselines. Notably, with just 1% of labeled pixels per class, on these datasets our method achieves an accuracy that goes from 86.42% (challenging dataset) to 99.52% (easy dataset). Furthermore we show that the simple neural network method improves over other baselines in the new challenging supervised setting. Our analysis substantiates the highly beneficial effect of using the entire image (so train and test data) for constructing a model.