 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation with Randomized Expectation Maximization
Paper and Code
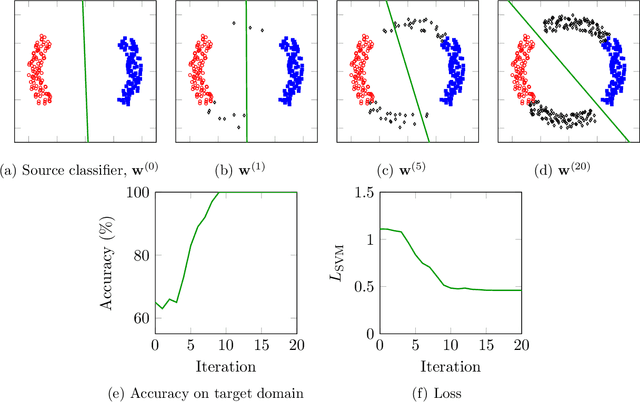



Domain adaptation (DA) is the task of classifying an unlabeled dataset (target) using a labeled dataset (source) from a related domain. The majority of successful DA methods try to directly match the distributions of the source and target data by transforming the feature space. Despite their success, state of the art methods based on this approach are either involved or unable to directly scale to data with many features. This article shows that domain adaptation can be successfully performed by using a very simple randomized expectation maximization (EM) method. We consider two instances of the method, which involve logistic regression and support vector machine, respectively. The underlying assumption of the proposed method is the existence of a good single linear classifier for both source and target domain. The potential limitations of this assumption are alleviated by the flexibility of the method, which can directly incorporate deep features extracted from a pre-trained deep neural network. The resulting algorithm is strikingly easy to implement and apply. We test its performance on 36 real-life adaptation tasks over text and image data with diverse characteristics. The method achieves state-of-the-art results, competitive with those of involved end-to-end deep transfer-learning methods.