 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view analysis of unregistered medical images using cross-view transformers
Paper and Code
Mar 21, 2021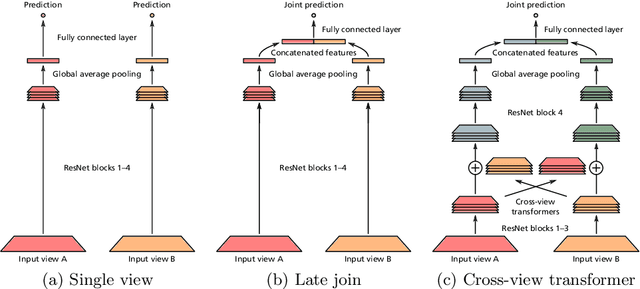

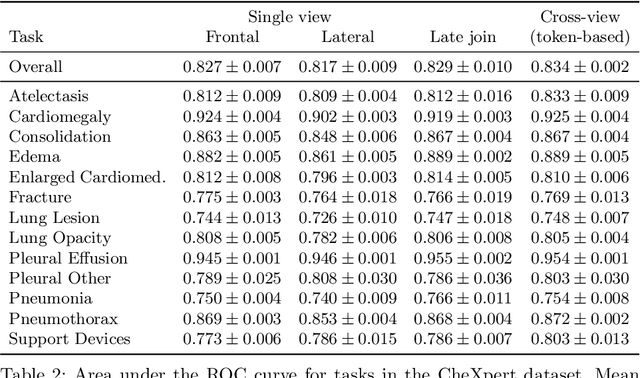
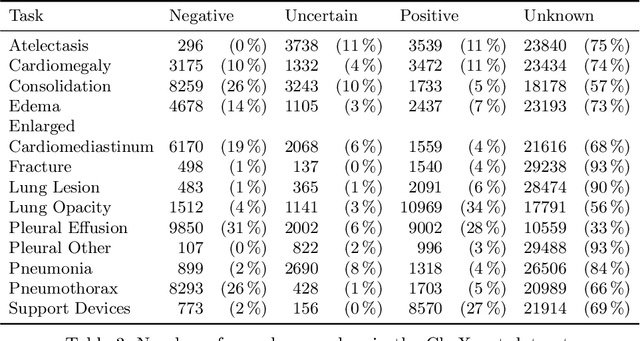
Multi-view medical image analysis often depends on the combination of information from multiple views. However, differences in perspective or other forms of misalignment can make it difficult to combine views effectively, as registration is not always possible. Without registration, views can only be combined at a global feature level, by joining feature vectors after global pooling. We present a novel cross-view transformer method to transfer information between unregistered views at the level of spatial feature maps. We demonstrate this method on multi-view mammography and chest X-ray datasets. On both datasets, we find that a cross-view transformer that links spatial feature maps can outperform a baseline model that joins feature vectors after global pooling.