 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductive Visual Verb Sense Disambiguation
Dec 20, 2020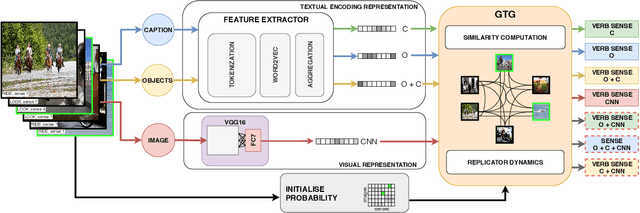
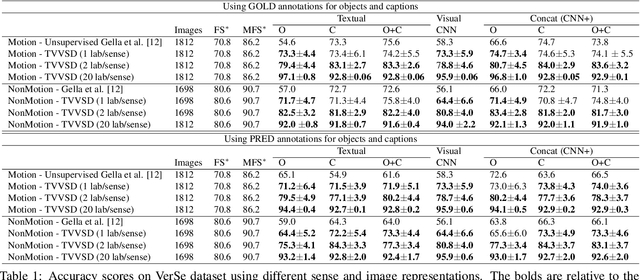
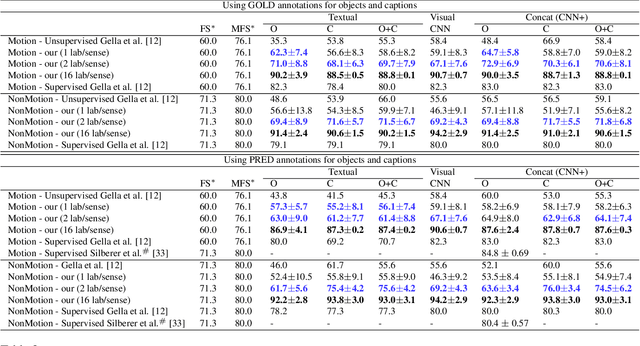
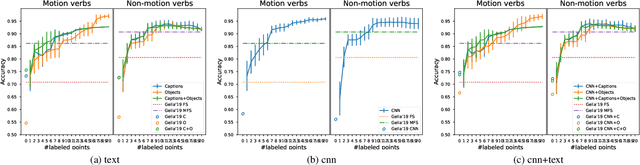
Verb Sense Disambiguation is a well-known task in NLP, the aim is to find the correct sense of a verb in a sentence. Recently, this problem has been extended in a multimodal scenario, by exploiting both textual and visual features of ambiguous verbs leading to a new problem, the Visual Verb Sense Disambiguation (VVSD). Here, the sense of a verb is assigned considering the content of an image paired with it rather than a sentence in which the verb appears. Annotating a dataset for this task is more complex than textual disambiguation, because assigning the correct sense to a pair of $<$image, verb$>$ requires both non-trivial linguistic and visual skills. In this work, differently from the literature, the VVSD task will be performed in a transductive semi-supervised learning (SSL) setting, in which only a small amount of labeled information is required, reducing tremendously the need for annotated data. The disambiguation process is based on a graph-based label propagation method which takes into account mono or multimodal representations for $<$image, verb$>$ pairs. Experiments have been carried out on the recently published dataset VerSe, the only available dataset for this task. The achieved results outperform the current state-of-the-art by a large margin while using only a small fraction of labeled samples per sense. Code available: https://github.com/GiBg1aN/TVVSD.