 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALT: Introducing a Framework for Hierarchical Segmentations in Medical Imaging using Softmax for Arbitrary Label Trees
Jul 11, 2024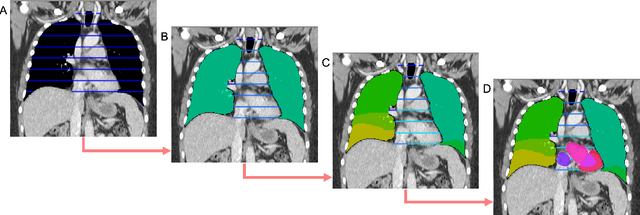
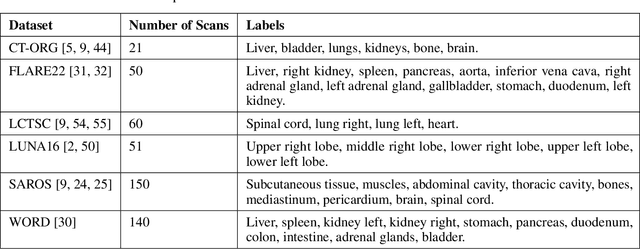
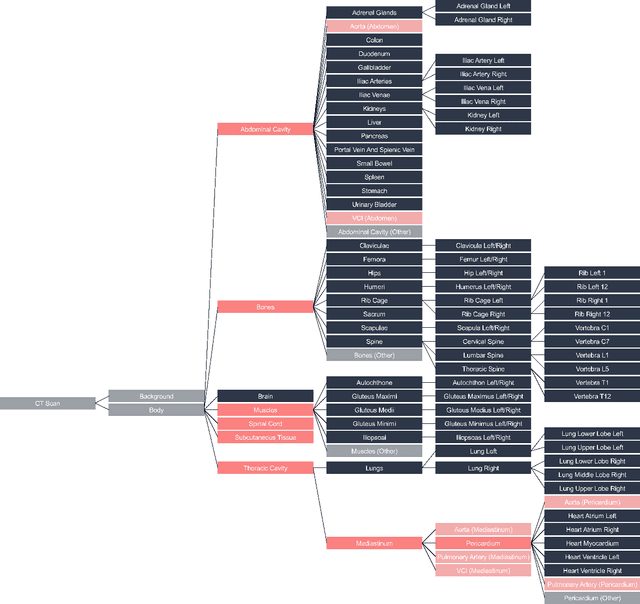
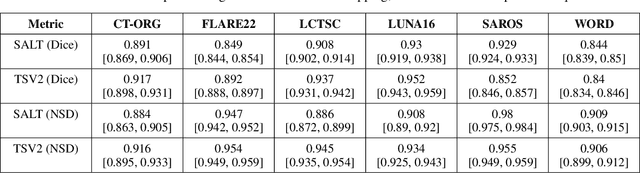
Traditional segmentation networks approach anatomical structures as standalone elements, overlooking the intrinsic hierarchical connections among them. This study introduces Softmax for Arbitrary Label Trees (SALT), a novel approach designed to leverage the hierarchical relationships between labels, improving the efficiency and interpretability of the segmentations. This study introduces a novel segmentation technique for CT imaging, which leverages conditional probabilities to map the hierarchical structure of anatomical landmarks, such as the spine's division into lumbar, thoracic, and cervical regions and further into individual vertebrae. The model was developed using the SAROS dataset from The Cancer Imaging Archive (TCIA), comprising 900 body region segmentations from 883 patients. The dataset was further enhanced by generating additional segmentations with the TotalSegmentator, for a total of 113 labels. The model was trained on 600 scans, while validation and testing were conducted on 150 CT scans. Performance was assessed using the Dice score across various datasets, including SAROS, CT-ORG, FLARE22, LCTSC, LUNA16, and WORD. Among the evaluated datasets, SALT achieved its best results on the LUNA16 and SAROS datasets, with Dice scores of 0.93 and 0.929 respectively. The model demonstrated reliable accuracy across other datasets, scoring 0.891 on CT-ORG and 0.849 on FLARE22. The LCTSC dataset showed a score of 0.908 and the WORD dataset also showed good performance with a score of 0.844. SALT used the hierarchical structures inherent in the human body to achieve whole-body segmentations with an average of 35 seconds for 100 slices. This rapid processing underscores its potential for integration into clinical workflows, facilitating the automatic and efficient computation of full-body segmentations with each CT scan, thus enhancing diagnostic processes and patient care.
ROCOv2: Radiology Objects in COntext Version 2, an Updated Multimodal Image Dataset
May 16, 2024Automated medical image analysis systems often require large amounts of training data with high quality labels, which are difficult and time consuming to generate. This paper introduces Radiology Object in COntext version 2 (ROCOv2), a multimodal dataset consisting of radiological images and associated medical concepts and captions extracted from the PMC Open Access subset. It is an updated version of the ROCO dataset published in 2018, and adds 35,705 new images added to PMC since 2018. It further provides manually curated concepts for imaging modalities with additional anatomical and directional concepts for X-rays. The dataset consists of 79,789 images and has been used, with minor modifications, in the concept detection and caption prediction tasks of ImageCLEFmedical Caption 2023. The dataset is suitable for training image annotation models based on image-caption pairs, or for multi-label image classification using Unified Medical Language System (UMLS) concepts provided with each image. In addition, it can serve for pre-training of medical domain models, and evaluation of deep learning models for multi-task learning.