 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking Parkinson's Disease with Smile: An AI-enabled Screening Framework
Aug 03, 2023



Parkinson's disease (PD) diagnosis remains challenging due to lacking a reliable biomarker and limited access to clinical care. In this study, we present an analysis of the largest video dataset containing micro-expressions to screen for PD. We collected 3,871 videos from 1,059 unique participants, including 256 self-reported PD patients. The recordings are from diverse sources encompassing participants' homes across multiple countries, a clinic, and a PD care facility in the US. Leveraging facial landmarks and action units, we extracted features relevant to Hypomimia, a prominent symptom of PD characterized by reduced facial expressions. An ensemble of AI models trained on these features achieved an accuracy of 89.7% and an Area Under the Receiver Operating Characteristic (AUROC) of 89.3% while being free from detectable bias across population subgroups based on sex and ethnicity on held-out data. Further analysis reveals that features from the smiling videos alone lead to comparable performance, even on two external test sets the model has never seen during training, suggesting the potential for PD risk assessment from smiling selfie videos.
Using AI to Measure Parkinson's Disease Severity at Home
Apr 13, 2023We present an artificial intelligence system to remotely assess the motor performance of individuals with Parkinson's disease (PD). Participants performed a motor task (i.e., tapping fingers) in front of a webcam, and data from 250 global participants were rated by three expert neurologists following the Movement Disorder Society Unified Parkinson's Disease Rating Scale (MDS-UPDRS). The neurologists' ratings were highly reliable, with an intra-class correlation coefficient (ICC) of 0.88. We developed computer algorithms to obtain objective measurements that align with the MDS-UPDRS guideline and are strongly correlated with the neurologists' ratings. Our machine learning model trained on these measures outperformed an MDS-UPDRS certified rater, with a mean absolute error (MAE) of 0.59 compared to the rater's MAE of 0.79. However, the model performed slightly worse than the expert neurologists (0.53 MAE). The methodology can be replicated for similar motor tasks, providing the possibility of evaluating individuals with PD and other movement disorders remotely, objectively, and in areas with limited access to neurological care.
TextMI: Textualize Multimodal Information for Integrating Non-verbal Cues in Pre-trained Language Models
Mar 29, 2023Pre-trained large language models have recently achieved ground-breaking performance in a wide variety of language understanding tasks. However, the same model can not be applied to multimodal behavior understanding tasks (e.g., video sentiment/humor detection) unless non-verbal features (e.g., acoustic and visual) can be integrated with language. Jointly modeling multiple modalities significantly increases the model complexity, and makes the training process data-hungry. While an enormous amount of text data is available via the web, collecting large-scale multimodal behavioral video datasets is extremely expensive, both in terms of time and money. In this paper, we investigate whether large language models alone can successfully incorporate non-verbal information when they are presented in textual form. We present a way to convert the acoustic and visual information into corresponding textual descriptions and concatenate them with the spoken text. We feed this augmented input to a pre-trained BERT model and fine-tune it on three downstream multimodal tasks: sentiment, humor, and sarcasm detection. Our approach, TextMI, significantly reduces model complexity, adds interpretability to the model's decision, and can be applied for a diverse set of tasks while achieving superior (multimodal sarcasm detection) or near SOTA (multimodal sentiment analysis and multimodal humor detection) performance. We propose TextMI as a general, competitive baseline for multimodal behavioral analysis tasks, particularly in a low-resource setting.
Auto-Gait: Automatic Ataxia Risk Assessment with Computer Vision on Gait Task Videos
Mar 15, 2022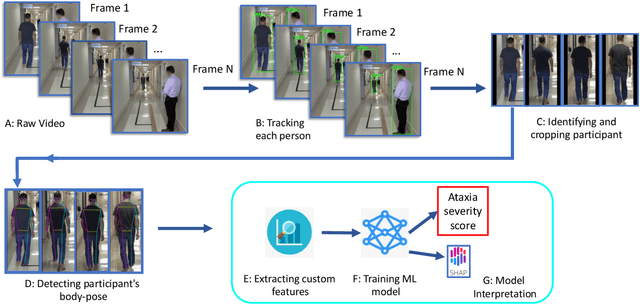


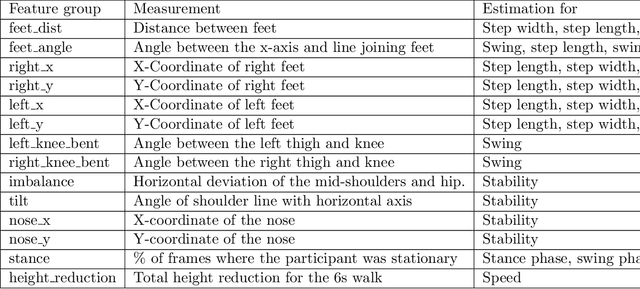
In this paper, we investigated whether we can 1) detect participants with ataxia-specific gait characteristics (risk-prediction), and 2) assess severity of ataxia from gait (severity-assessment). We collected 155 videos from 89 participants, 24 controls and 65 diagnosed with (or are pre-manifest) spinocerebellar ataxias (SCAs), performing the gait task of the Scale for the Assessment and Rating of Ataxia (SARA) from 11 medical sites located in 8 different states in the United States. We developed a method to separate the participants from their surroundings and constructed several features to capture gait characteristics like step width, step length, swing, stability, speed, etc. Our risk-prediction model achieves 83.06% accuracy and an 80.23% F1 score. Similarly, our severity-assessment model achieves a mean absolute error (MAE) score of 0.6225 and a Pearson's correlation coefficient score of 0.7268. Our models still performed competitively when evaluated on data from sites not used during training. Furthermore, through feature importance analysis, we found that our models associate wider steps, decreased walking speed, and increased instability with greater ataxia severity, which is consistent with previously established clinical knowledge. Our models create possibilities for remote ataxia assessment in non-clinical settings in the future, which could significantly improve accessibility of ataxia care. Furthermore, our underlying dataset was assembled from a geographically diverse cohort, highlighting its potential to further increase equity. The code used in this study is open to the public, and the anonymized body pose landmark dataset could be released upon approval from our Institutional Review Board (IRB).
DBATES: DataBase of Audio features, Text, and visual Expressions in competitive debate Speeches
Mar 26, 2021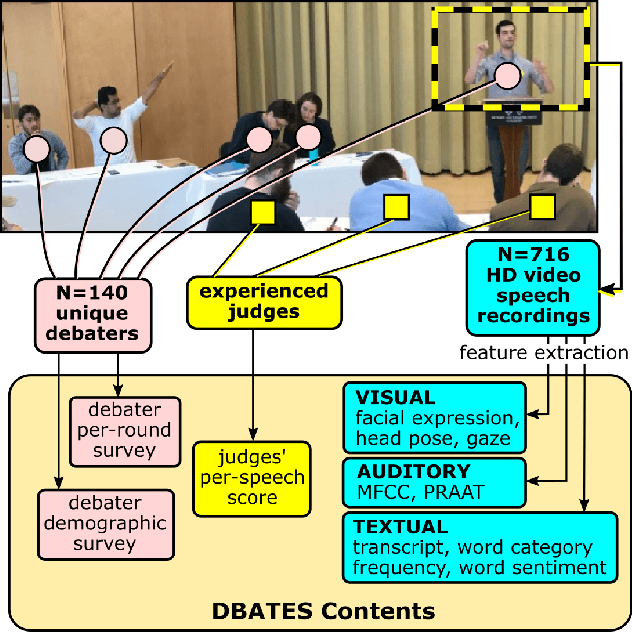
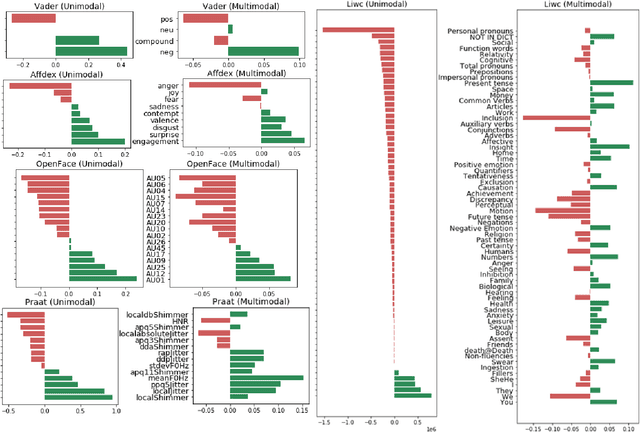

In this work, we present a database of multimodal communication features extracted from debate speeches in the 2019 North American Universities Debate Championships (NAUDC). Feature sets were extracted from the visual (facial expression, gaze, and head pose), audio (PRAAT), and textual (word sentiment and linguistic category) modalities of raw video recordings of competitive collegiate debaters (N=717 6-minute recordings from 140 unique debaters). Each speech has an associated competition debate score (range: 67-96) from expert judges as well as competitor demographic and per-round reflection surveys. We observe the fully multimodal model performs best in comparison to models trained on various compositions of modalities. We also find that the weights of some features (such as the expression of joy and the use of the word we) change in direction between the aforementioned models. We use these results to highlight the value of a multimodal dataset for studying competitive, collegiate debate.
Detecting Parkinson's Disease from Speech-task in an accessible and interpretable manner
Sep 02, 2020



Every nine minutes a person is diagnosed with Parkinson's Disease (PD) in the United States. However, studies have shown that between 25 and 80\% of individuals with Parkinson's Disease (PD) remain undiagnosed. An online, in the wild audio recording application has the potential to help screen for the disease if risk can be accurately assessed. In this paper, we collect data from 726 unique subjects (262 PD and 464 Non-PD) uttering the "quick brown fox jumps over the lazy dog ...." to conduct automated PD assessment. We extracted both standard acoustic features and deep learning based embedding features from the speech data and trained several machine learning algorithms on them. Our models achieved 0.75 AUC by modeling the standard acoustic features through the XGBoost model. We also provide explanation behind our model's decision and show that it is focusing mostly on the widely used MFCC features and a subset of dysphonia features previously used for detecting PD from verbal phonation task.
M-BERT: Injecting Multimodal Information in the BERT Structure
Aug 15, 2019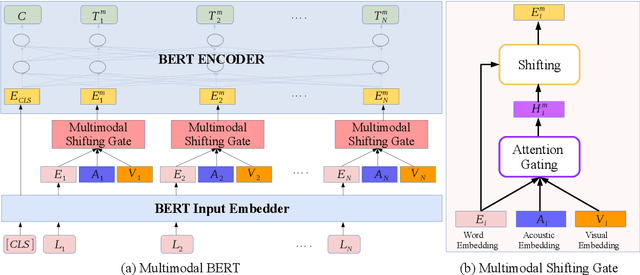
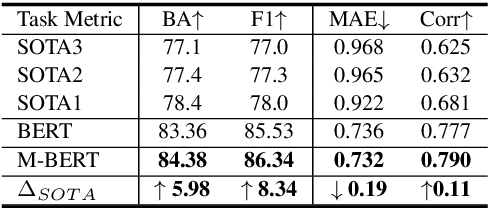
Multimodal language analysis is an emerging research area in natural language processing that models language in a multimodal manner. It aims to understand language from the modalities of text, visual, and acoustic by modeling both intra-modal and cross-modal interactions. BERT (Bidirectional Encoder Representations from Transformers) provides strong contextual language representations after training on large-scale unlabeled corpora. Fine-tuning the vanilla BERT model has shown promising results in building state-of-the-art models for diverse NLP tasks like question answering and language inference. However, fine-tuning BERT in the presence of information from other modalities remains an open research problem. In this paper, we inject multimodal information within the input space of BERT network for modeling multimodal language. The proposed injection method allows BERT to reach a new state of the art of $84.38\%$ binary accuracy on CMU-MOSI dataset (multimodal sentiment analysis) with a gap of 5.98 percent to the previous state of the art and 1.02 percent to the text-only BERT.
UR-FUNNY: A Multimodal Language Dataset for Understanding Humor
Apr 14, 2019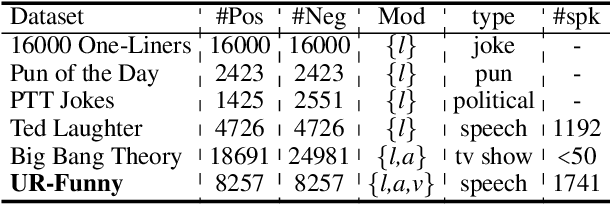
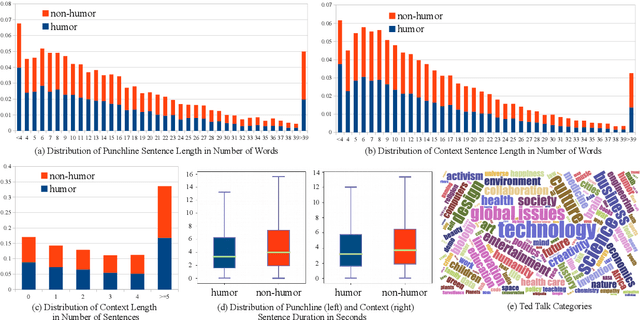
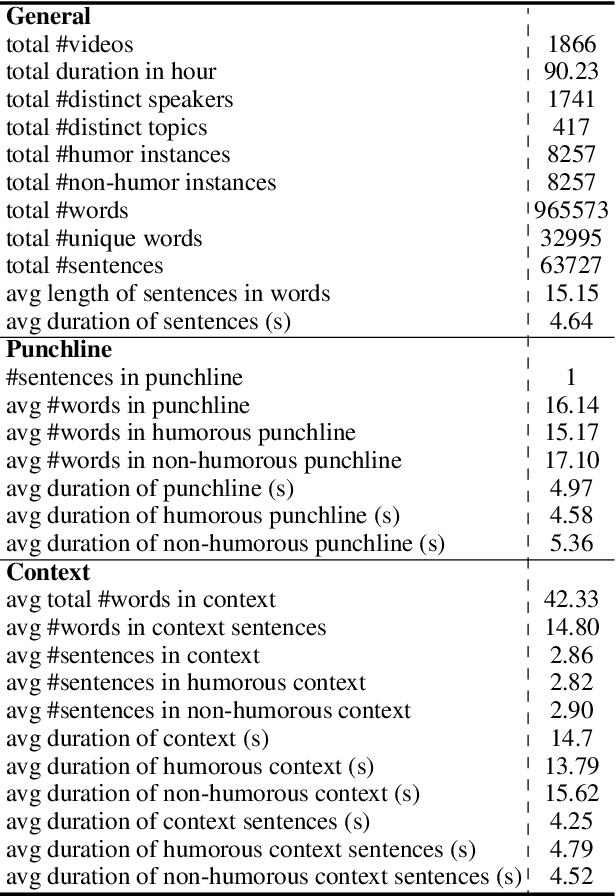
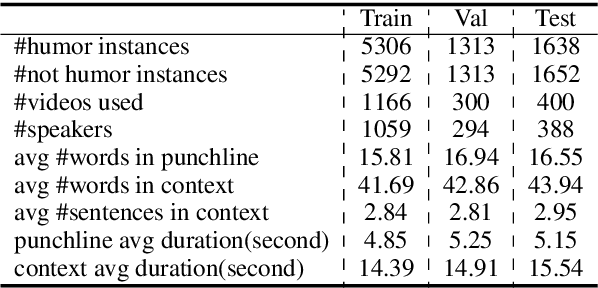
Humor is a unique and creative communicative behavior displayed during social interactions. It is produced in a multimodal manner, through the usage of words (text), gestures (vision) and prosodic cues (acoustic). Understanding humor from these three modalities falls within boundaries of multimodal language; a recent research trend in natural language processing that models natural language as it happens in face-to-face communication. Although humor detection is an established research area in NLP, in a multimodal context it is an understudied area. This paper presents a diverse multimodal dataset, called UR-FUNNY, to open the door to understanding multimodal language used in expressing humor. The dataset and accompanying studies, present a framework in multimodal humor detection for the natural language processing community. UR-FUNNY is publicly available for research.