 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBATES: DataBase of Audio features, Text, and visual Expressions in competitive debate Speeches
Mar 26, 2021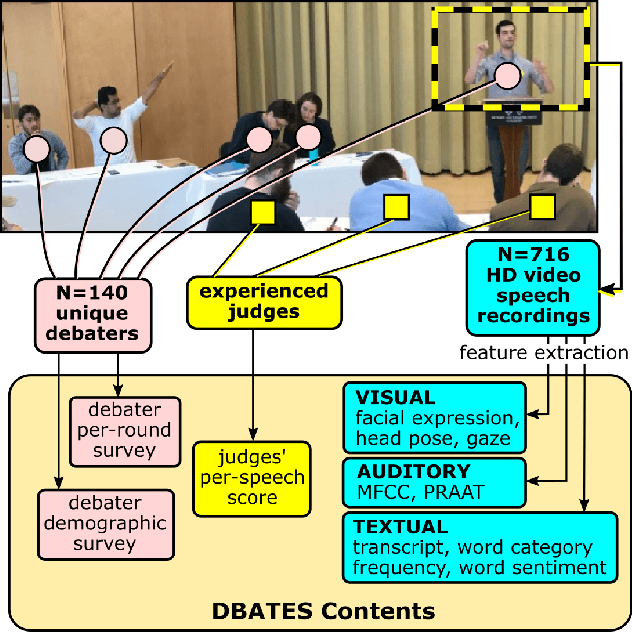
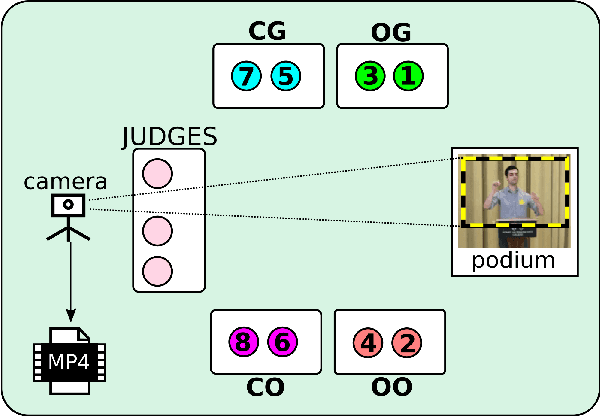
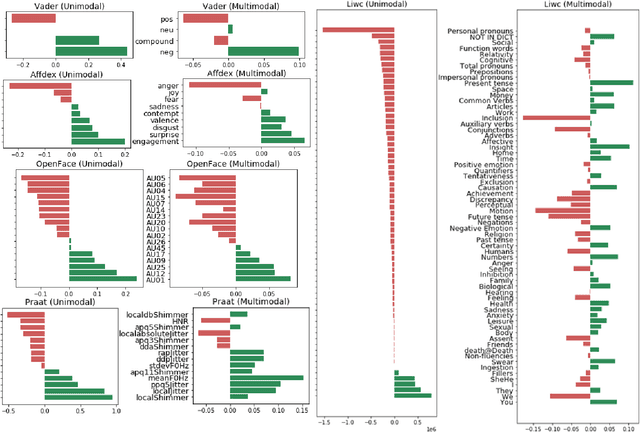

In this work, we present a database of multimodal communication features extracted from debate speeches in the 2019 North American Universities Debate Championships (NAUDC). Feature sets were extracted from the visual (facial expression, gaze, and head pose), audio (PRAAT), and textual (word sentiment and linguistic category) modalities of raw video recordings of competitive collegiate debaters (N=717 6-minute recordings from 140 unique debaters). Each speech has an associated competition debate score (range: 67-96) from expert judges as well as competitor demographic and per-round reflection surveys. We observe the fully multimodal model performs best in comparison to models trained on various compositions of modalities. We also find that the weights of some features (such as the expression of joy and the use of the word we) change in direction between the aforementioned models. We use these results to highlight the value of a multimodal dataset for studying competitive, collegiate debate.