 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorless Diversification for Parallel LLM Ideation
May 28, 2026LLMs are increasingly used to generate candidate-idea pools for creative tasks where broad exploration is valuable. Parallel inference can be attractive in this setting when it broadens the pool while retaining quality and cost efficiency. We study inference-time controls for candidate-pool diversification, asking whether anchorless methods can rival methods that depend on observed seed ideas. Across three creative task families, we compare independent generation and semantic direction stratification with self-, peer-, and representative-anchor baselines, under neutral and population-referential divergent instructions. Population-referential divergence is a strong low-cost baseline, increasing semantic diversity while preserving quality proxies. Semantic direction stratification is stronger: a single planning call organizes generations across broad semantic directions, yielding the best diversity--quality--compute frontier. Anchored regeneration can be strong in final-pool diversity, but its advantage shrinks under full-pipeline token accounting. These results establish practical anchorless baselines for open-ended LLM ideation.
Ex Ante Evaluation of AI-Induced Idea Diversity Collapse
May 07, 2026Creative AI systems are typically evaluated at the level of individual utility, yet creative outputs are consumed in populations: an idea loses value when many others produce similar ones. This creates an evaluation blind spot, as AI can improve individual outputs while increasing population-level crowding. We introduce a human-relative framework for benchmarking AI-induced human diversity collapse without requiring human-AI interaction data, providing an ex ante protocol to estimate crowding risk from model-only generations and matched unaided human baselines. By modeling ideas as congestible resources, we show that source-level crowding is identifiable from within-distribution comparisons, yielding an excess-crowding coefficient $Δ$ and a human-relative diversity ratio $ρ$. We show that $ρ\ge1$ is the no-excess-crowding parity condition and connect $Δ$ to an adoption game with exposure-dependent redundancy costs. Across short stories, marketing slogans, and alternative-uses tasks, three frontier LLMs fall below parity across crowding kernels. Estimates stabilize with feasible model-only sample sizes. Importantly, generation-protocol variants show that crowding can be reduced through targeted design, making diversity collapse an actionable, development-time evaluation target for population-aware creative AI.
MuseRAG: Idea Originality Scoring At Scale
May 22, 2025An objective, face-valid way to assess the originality of creative ideas is to measure how rare each idea is within a population -- an approach long used in creativity research but difficult to automate at scale. Tabulating response frequencies via manual bucketing of idea rephrasings is labor-intensive, error-prone, and brittle under large corpora. We introduce a fully automated, psychometrically validated pipeline for frequency-based originality scoring. Our method, MuseRAG, combines large language models (LLMs) with an externally orchestrated retrieval-augmented generation (RAG) framework. Given a new idea, the system retrieves semantically similar prior idea buckets and zero-shot prompts the LLM to judge whether the new idea belongs to an existing bucket or forms a new one. The resulting buckets enable computation of frequency-based originality metrics. Across five datasets (N=1143, n_ideas=16294), MuseRAG matches human annotators in idea clustering structure and resolution (AMI = 0.59) and in participant-level scoring (r = 0.89) -- while exhibiting strong convergent and external validity. Our work enables intent-sensitive, human-aligned originality scoring at scale to aid creativity research.
AI Can Enhance Creativity in Social Networks
Oct 20, 2024



Can peer recommendation engines elevate people's creative performances in self-organizing social networks? Answering this question requires resolving challenges in data collection (e.g., tracing inspiration links and psycho-social attributes of nodes) and intervention design (e.g., balancing idea stimulation and redundancy in evolving information environments). We trained a model that predicts people's ideation performances using semantic and network-structural features in an online platform. Using this model, we built SocialMuse, which maximizes people's predicted performances to generate peer recommendations for them. We found treatment networks leveraging SocialMuse outperforming AI-agnostic control networks in several creativity measures. The treatment networks were more decentralized than the control, as SocialMuse increasingly emphasized network-structural features at large network sizes. This decentralization spreads people's inspiration sources, helping inspired ideas stand out better. Our study provides actionable insights into building intelligent systems for elevating creativity.
NADBenchmarks -- a compilation of Benchmark Datasets for Machine Learning Tasks related to Natural Disasters
Dec 21, 2022Climate change has increased the intensity, frequency, and duration of extreme weather events and natural disasters across the world. While the increased data on natural disasters improves the scope of machine learning (ML) in this field, progress is relatively slow. One bottleneck is the lack of benchmark datasets that would allow ML researchers to quantify their progress against a standard metric. The objective of this short paper is to explore the state of benchmark datasets for ML tasks related to natural disasters, categorizing them according to the disaster management cycle. We compile a list of existing benchmark datasets introduced in the past five years. We propose a web platform - NADBenchmarks - where researchers can search for benchmark datasets for natural disasters, and we develop a preliminary version of such a platform using our compiled list. This paper is intended to aid researchers in finding benchmark datasets to train their ML models on, and provide general directions for topics where they can contribute new benchmark datasets.
DBATES: DataBase of Audio features, Text, and visual Expressions in competitive debate Speeches
Mar 26, 2021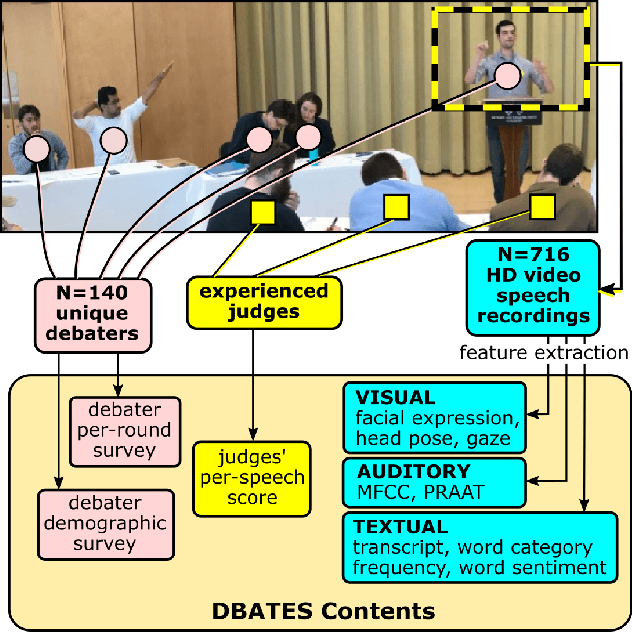
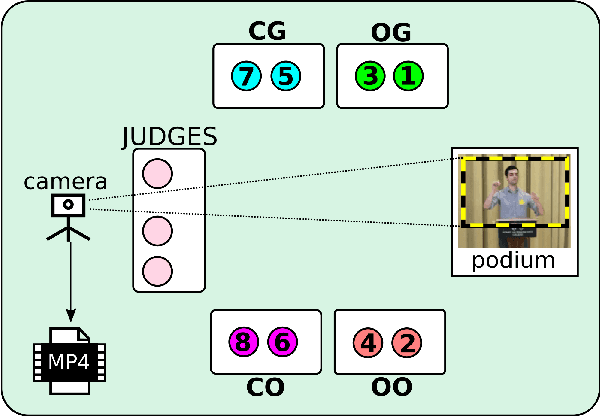
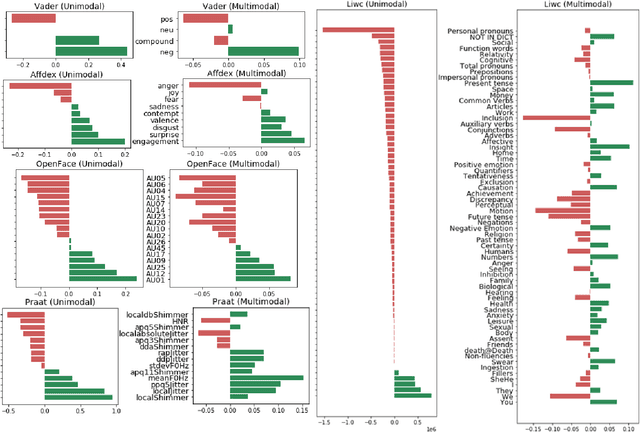

In this work, we present a database of multimodal communication features extracted from debate speeches in the 2019 North American Universities Debate Championships (NAUDC). Feature sets were extracted from the visual (facial expression, gaze, and head pose), audio (PRAAT), and textual (word sentiment and linguistic category) modalities of raw video recordings of competitive collegiate debaters (N=717 6-minute recordings from 140 unique debaters). Each speech has an associated competition debate score (range: 67-96) from expert judges as well as competitor demographic and per-round reflection surveys. We observe the fully multimodal model performs best in comparison to models trained on various compositions of modalities. We also find that the weights of some features (such as the expression of joy and the use of the word we) change in direction between the aforementioned models. We use these results to highlight the value of a multimodal dataset for studying competitive, collegiate debate.