 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturb Your Data: Paraphrase-Guided Training Data Watermarking
Dec 18, 2025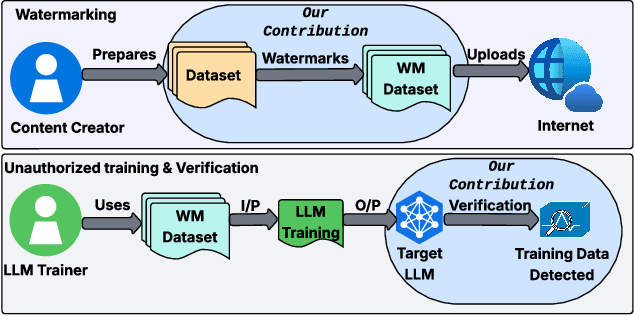
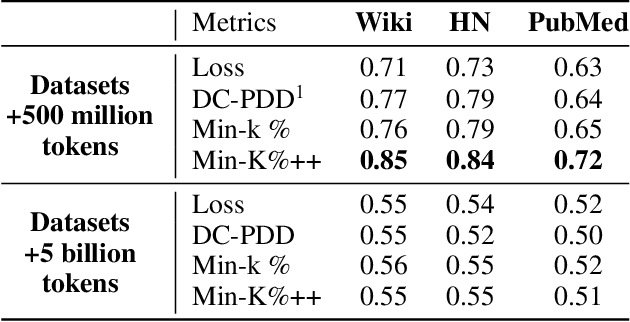
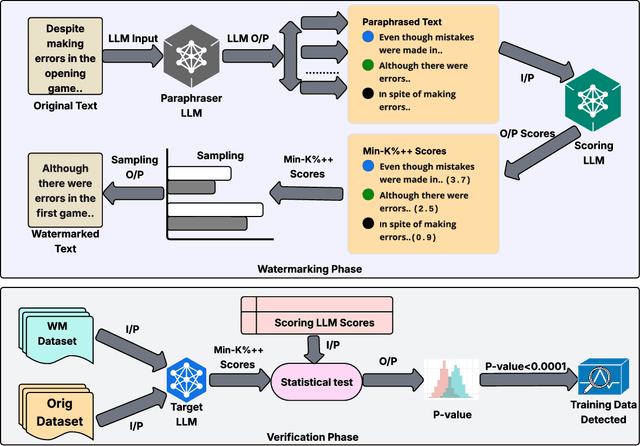
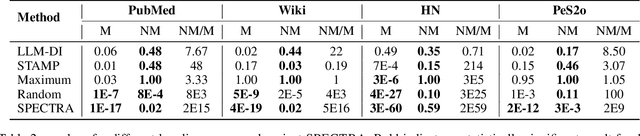
Training data detection is critical for enforcing copyright and data licensing, as Large Language Models (LLM) are trained on massive text corpora scraped from the internet. We present SPECTRA, a watermarking approach that makes training data reliably detectable even when it comprises less than 0.001% of the training corpus. SPECTRA works by paraphrasing text using an LLM and assigning a score based on how likely each paraphrase is, according to a separate scoring model. A paraphrase is chosen so that its score closely matches that of the original text, to avoid introducing any distribution shifts. To test whether a suspect model has been trained on the watermarked data, we compare its token probabilities against those of the scoring model. We demonstrate that SPECTRA achieves a consistent p-value gap of over nine orders of magnitude when detecting data used for training versus data not used for training, which is greater than all baselines tested. SPECTRA equips data owners with a scalable, deploy-before-release watermark that survives even large-scale LLM training.
Towards Effectively Leveraging Execution Traces for Program Repair with Code LLMs
May 07, 2025Large Language Models (LLMs) show promising performance on various programming tasks, including Automatic Program Repair (APR). However, most approaches to LLM-based APR are limited to the static analysis of the programs, while disregarding their runtime behavior. Inspired by knowledge-augmented NLP, in this work, we aim to remedy this potential blind spot by augmenting standard APR prompts with program execution traces. We evaluate our approach using the GPT family of models on three popular APR datasets. Our findings suggest that simply incorporating execution traces into the prompt provides a limited performance improvement over trace-free baselines, in only 2 out of 6 tested dataset / model configurations. We further find that the effectiveness of execution traces for APR diminishes as their complexity increases. We explore several strategies for leveraging traces in prompts and demonstrate that LLM-optimized prompts help outperform trace-free prompts more consistently. Additionally, we show trace-based prompting to be superior to finetuning a smaller LLM on a small-scale dataset; and conduct probing studies reinforcing the notion that execution traces can complement the reasoning abilities of the LLMs.
BuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.
DocLLM: A layout-aware generative language model for multimodal document understanding
Dec 31, 2023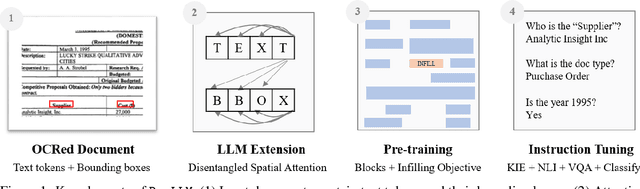

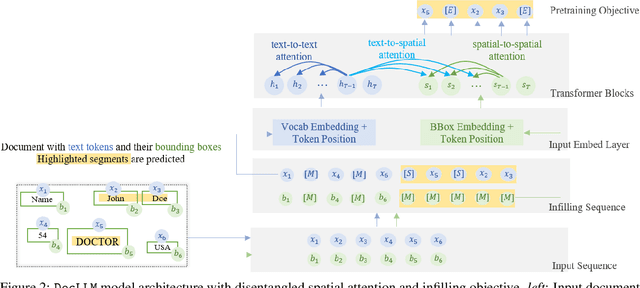
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in comprehending these documents effectively. In this paper, we present DocLLM, a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account both textual semantics and spatial layout. Our model differs from existing multimodal LLMs by avoiding expensive image encoders and focuses exclusively on bounding box information to incorporate the spatial layout structure. Specifically, the cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, we devise a pre-training objective that learns to infill text segments. This approach allows us to address irregular layouts and heterogeneous content frequently encountered in visual documents. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. We demonstrate that our solution outperforms SotA LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
How Effective Are Neural Networks for Fixing Security Vulnerabilities
May 29, 2023Security vulnerability repair is a difficult task that is in dire need of automation. Two groups of techniques have shown promise: (1) large code language models (LLMs) that have been pre-trained on source code for tasks such as code completion, and (2) automated program repair (APR) techniques that use deep learning (DL) models to automatically fix software bugs. This paper is the first to study and compare Java vulnerability repair capabilities of LLMs and DL-based APR models. The contributions include that we (1) apply and evaluate five LLMs (Codex, CodeGen, CodeT5, PLBART and InCoder), four fine-tuned LLMs, and four DL-based APR techniques on two real-world Java vulnerability benchmarks (Vul4J and VJBench), (2) design code transformations to address the training and test data overlapping threat to Codex, (3) create a new Java vulnerability repair benchmark VJBench, and its transformed version VJBench-trans and (4) evaluate LLMs and APR techniques on the transformed vulnerabilities in VJBench-trans. Our findings include that (1) existing LLMs and APR models fix very few Java vulnerabilities. Codex fixes 10.2 (20.4%), the most number of vulnerabilities. (2) Fine-tuning with general APR data improves LLMs' vulnerability-fixing capabilities. (3) Our new VJBench reveals that LLMs and APR models fail to fix many Common Weakness Enumeration (CWE) types, such as CWE-325 Missing cryptographic step and CWE-444 HTTP request smuggling. (4) Codex still fixes 8.3 transformed vulnerabilities, outperforming all the other LLMs and APR models on transformed vulnerabilities. The results call for innovations to enhance automated Java vulnerability repair such as creating larger vulnerability repair training data, tuning LLMs with such data, and applying code simplification transformation to facilitate vulnerability repair.
Neural Transition-based Parsing of Library Deprecations
Dec 23, 2022
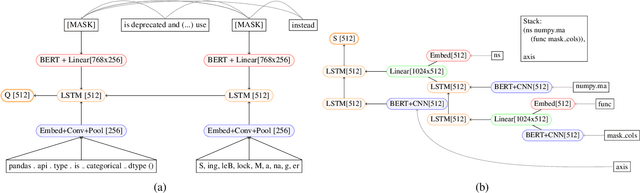


This paper tackles the challenging problem of automating code updates to fix deprecated API usages of open source libraries by analyzing their release notes. Our system employs a three-tier architecture: first, a web crawler service retrieves deprecation documentation from the web; then a specially built parser processes those text documents into tree-structured representations; finally, a client IDE plugin locates and fixes identified deprecated usages of libraries in a given codebase. The focus of this paper in particular is the parsing component. We introduce a novel transition-based parser in two variants: based on a classical feature engineered classifier and a neural tree encoder. To confirm the effectiveness of our method, we gathered and labeled a set of 426 API deprecations from 7 well-known Python data science libraries, and demonstrated our approach decisively outperforms a non-trivial neural machine translation baseline.